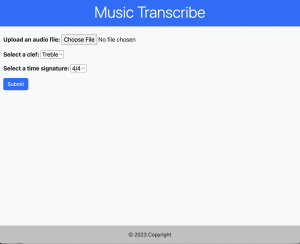
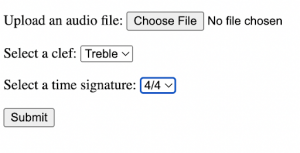
While Alejandro is familiar with Bootstrap, he focused on converting the previously written CSS to this as it helps modularize our project better.
I continued working on the project, specifically the cruz of a major bug. The bug was that if the length of the notes array was greater than 0, then we weren’t able to draw the notes using the Vexflow library. We continued to encounter an uncaught syntax error in our JavaScript file. After digging into various forums and documentation for the JavaScript library Vexflow, we ended up with the resolution to this – implement a try and except case and sort of hard code it in. I then tested it with various files and arrays and ensured it doesn’t fail.
As this tooka few days to sort out, I was mainly assisting Alejandro and Aditya on higher level discussions surrounding the integration files we had to alter, as outlined in the team status report. I also took the lead on the ethics assignment for our group.
I’d say I’m on track with the front-end nearly finalized and contributing mostly on debugging and code structure discussions on the backend.
I’ll be taking a lead on SNR rejection and adding more front end functionality such as saving and downloading files next week and perhaps creating user profiles.