This week, we decided to pivot away from our physical interface. There are unfortunate news, as we were making progress in various areas. However, after ordering a first round of materials for testing, we realized it would take too long for our final batch of supplies to arrive in time for the end of the semester.
Luckily, we accounted for this in our initial proposal, and can now pivot towards a fully virtual implementation — one that uses the web application John has been working on to display the results of Angela and Marco’s work so far.
To that end, we’ve listed out some of the re-worked scopes of our project below:
- Note Scheduling:
-
- Pivot from 5 discrete volume levels to more volume levels
- Take advantage of newfound dynamic range at quieter volumes: no longer limited by 5N minimum threshold
- Latency from input to output: 2% of audio length
- Threshold for replaying a key: 15% of max volume between each timestamp
- Web App:
- Take in recorded audio from user (either new recording or uploaded file
- ‘Upload’ recording to audio processing and note scheduler
-
-
- (Stretch goal) → Save csv file on backend (in between audio processing and note scheduler) for re-selection in future.
- Upon completion of audio processor, web app displays graphs of audio processing pipeline/progress
- Run ‘Speech to Text’ on audio file and support captions for virtual piano.
- Probably run in conjunction with audio processing such that we can more immediately display the virtual piano upon finishing the processing.
- Shows virtual piano on a new page that takes the audio playback, shows keys ‘raining’ down on keys using inspiration from ‘Pianolizer’ (https://github.com/creaktive/pianolizer)
- In order to optimize latency → Web app would prioritize processing just the audio and playing it back on virtual piano
- On a separate tab, we will show graphs
- Metrics:
- Latency
- Time between submitting audio recording to processing and return of graphs / audio for virtual piano
- Defined as a function of input audio length
- Latency
-
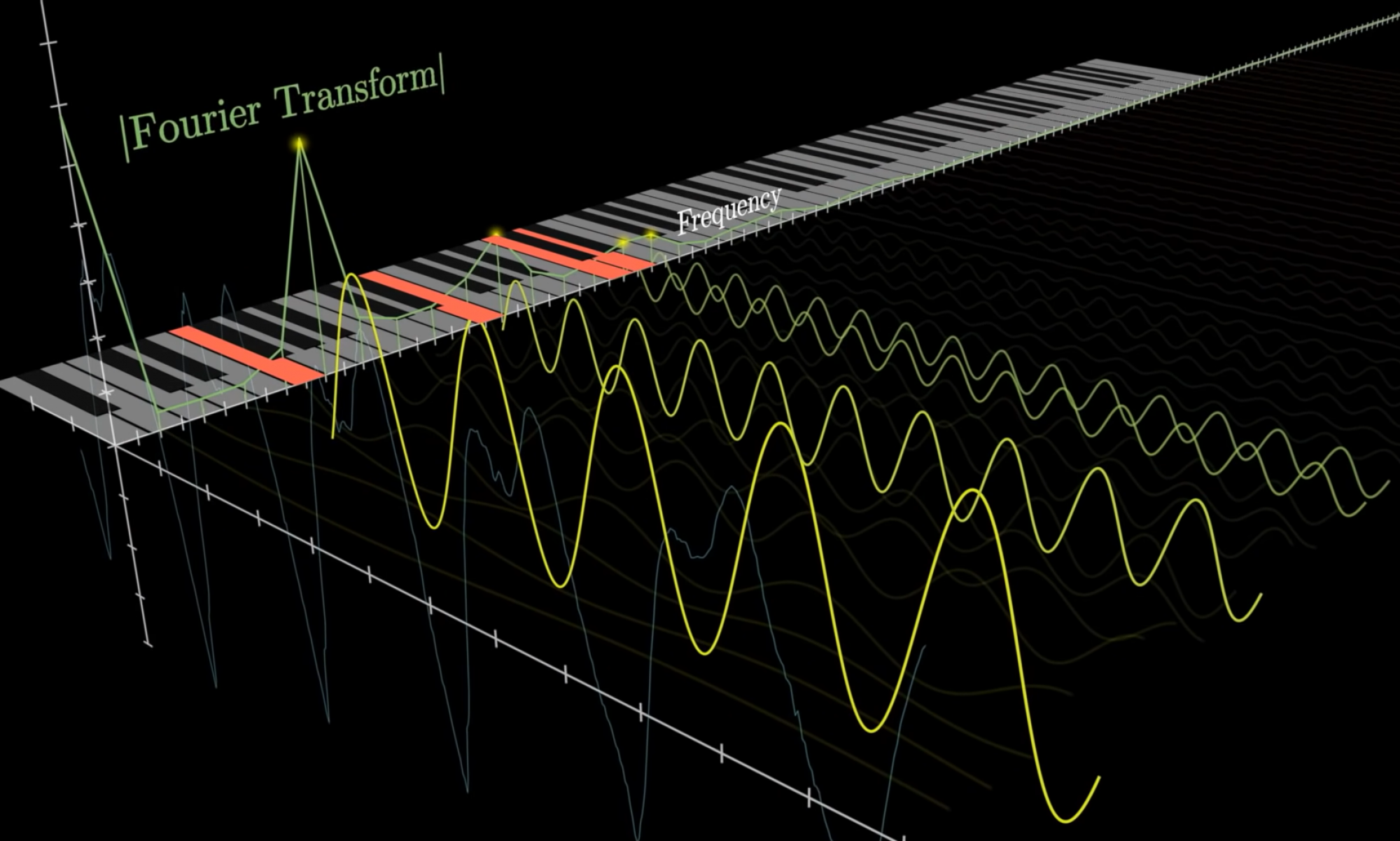
- Signal Processing
- Take in recorded audio from web app backend
- Generate three files
- A series of plots that give information about the incoming audio and frequencies perceived by the system
- A digital reconstruction of the original wav file using the frequencies extracted by our averaging function
- The originally promised csv file
- Metrics
- Audio fidelity
- Using the reconstructed audio from the signal processing module, we can interview people on whether they can understand what the reconstructed audio is trying to say. This provides insight into how perceivably functional the audio we’ll generate is (reported as a percentage of the successful reports / total reports).
- Generate information on what percentage of the original frequencies samples are lost from the averaging function (reported as a percentage of the captured information / original information)
- Audio fidelity