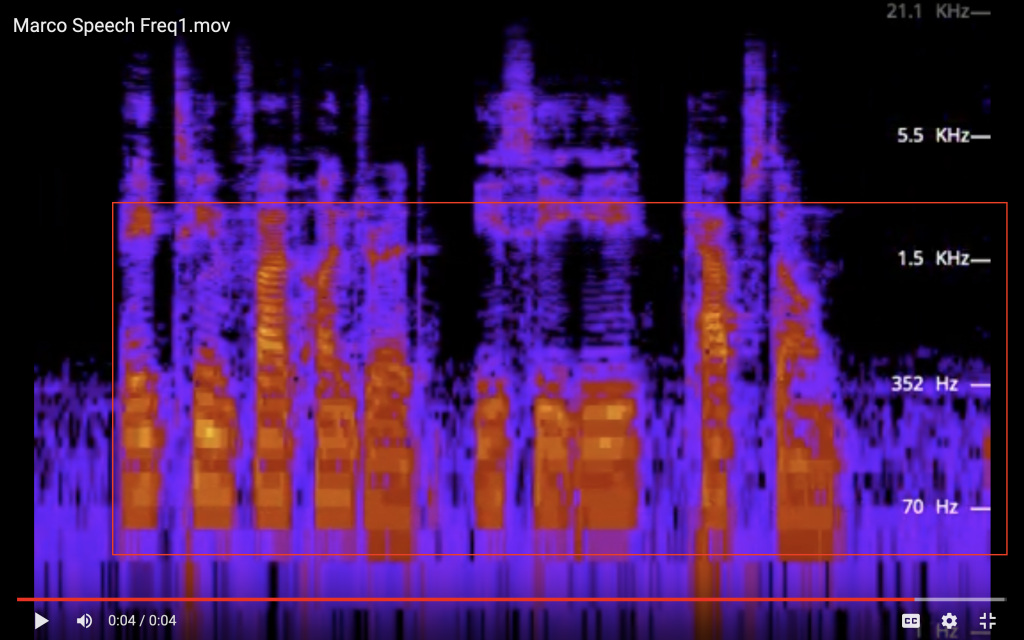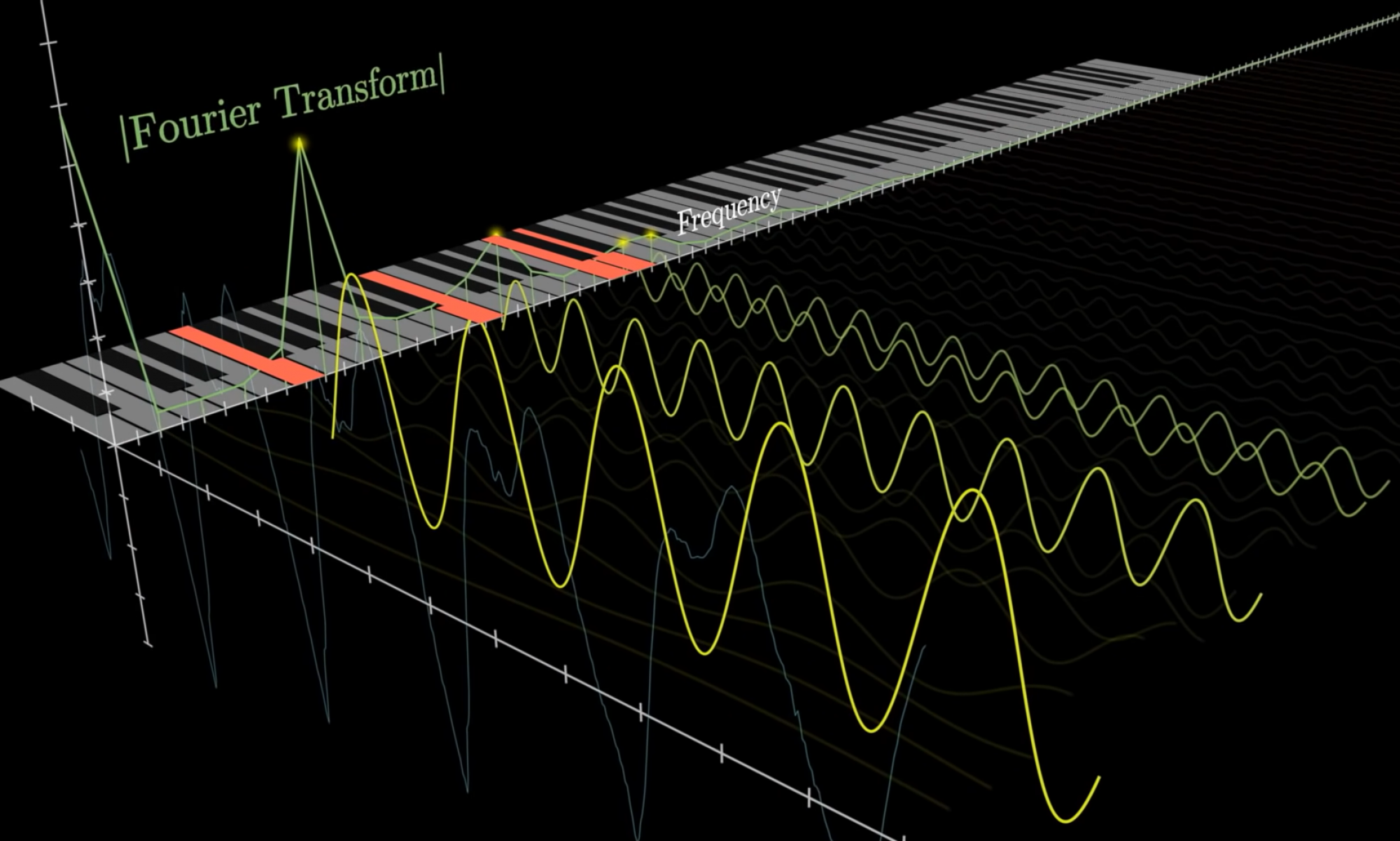
At the beginning of the week, I helped prepare the slides and studied the different aspects of the project in preparation for questions. Even though I’m not directly in charge of things like the audio processing, it was a good idea to re-familiarize myself with the concepts, both in anticipation of questions and also to work on the project collaboratively.
I also began the coding process. I have now outlined all the functions of the note scheduling module, and the inputs, outputs, preconditions and postconditions for each. This was possible as Marco and I discussed last week the format for the output of the audio processing module. I have also written pseudo-code for some of the functions.
I expressed interest in helping with some of the audio processing earlier on, especially with writing our custom FFT function. I thought it would be an interesting problem to work on, as it reduces the Fourier’s time complexity from O(n^2) to O(nlogn). As we would have access to AWS resources, we would also be able to further speed up the process with parallelism. I will investigate whether this is necessary for near-real-time speech-to-piano later. It’s possible that the bottleneck would be elsewhere, but if the bottleneck is in the audio processing, it’s good to know we have options for improving the timing here.