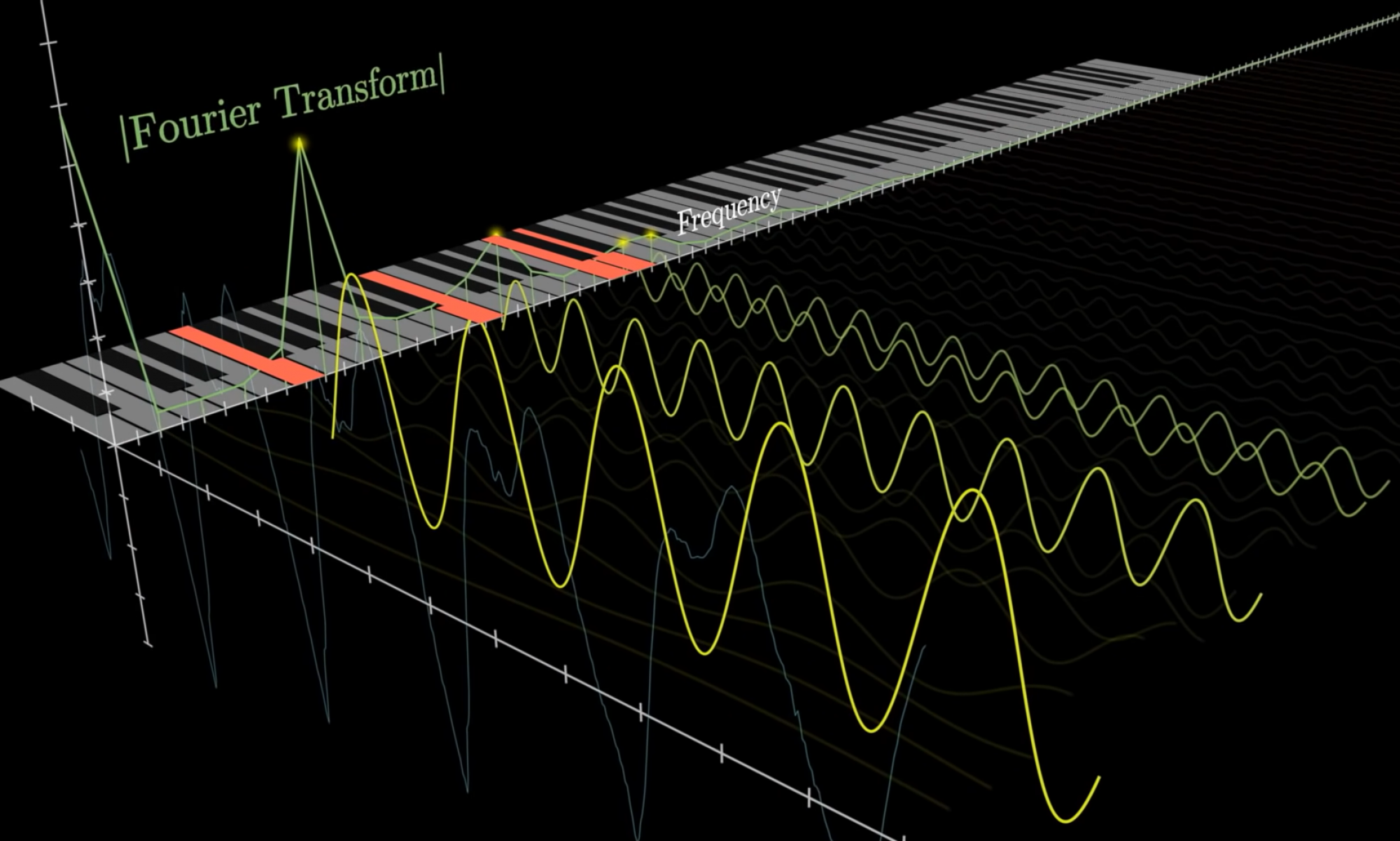
This week I continued to work on the note scheduling module. Last week I completed all the main functions, but I was unhappy with the state of the syllable and phoneme recognition. (Note: a phoneme is an atomic unit of speech, such as a vowel sound or a consonant sound in English).
Phoneme recognition is important for our project as it allows us to know when to lift or press piano keys that have already been pressed, and when to keep them pressed to sustain the sound. This allows for fluid speech-like sounds, as opposed to a stutter.
First, I read about how speech recognition handled syllable recognition. I learned that it was done through volume amplitudes. When someone speaks, the volume of speech dips in between each syllable. I discussed using this method with my team, but we realized that it would fail to account for the phonemes. For example, the words “flies” and “bear” are both monosyllabic, but require multiple phonemes.
I’ve now implemented two different methods for phoneme differentiation.
Method 1. Each frequency at each time interval has its volume compared to its volume in the previous time interval. If it’s louder by a certain threshold, it is pressed again. If it’s the same volume or slightly quieter, it’s held. If it’s much quieter or becomes silent, the key is either lifted and re-pressed with a lower volume or just lifted.
Method 2. At each time interval, the frequencies and their amplitudes are abstracted into a vector. We calculate the multidimensional difference between the vectors at different time intervals. If the difference is larger than a threshold, it will be judged to be a new phoneme and keys will be pressed again.
In the upcoming weeks we will implement ways to create the sounds from the key scheduling module and test both these methods, as well as other methods we think of, on volunteers to determine the best method for phoneme differentiation.