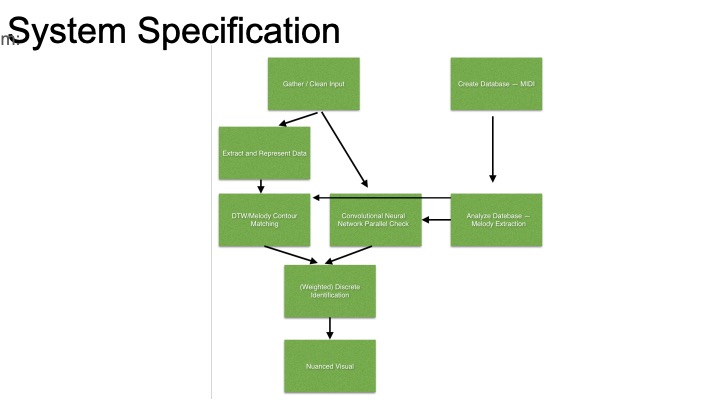
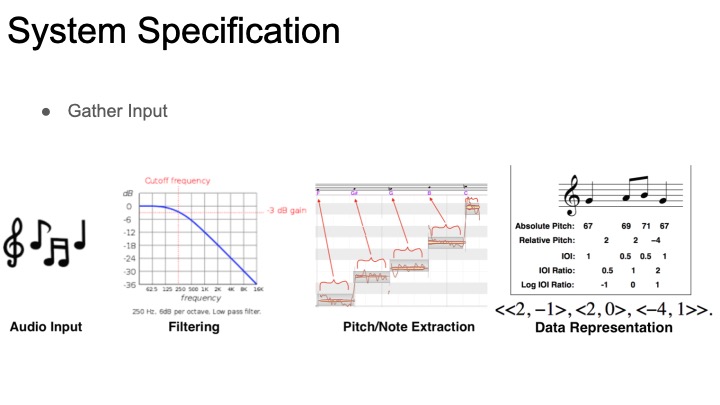
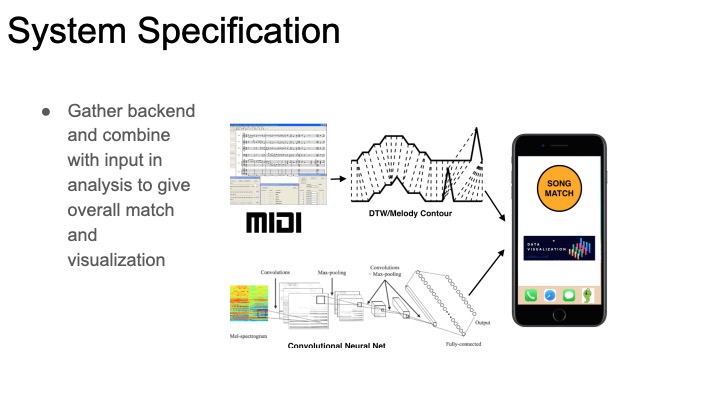
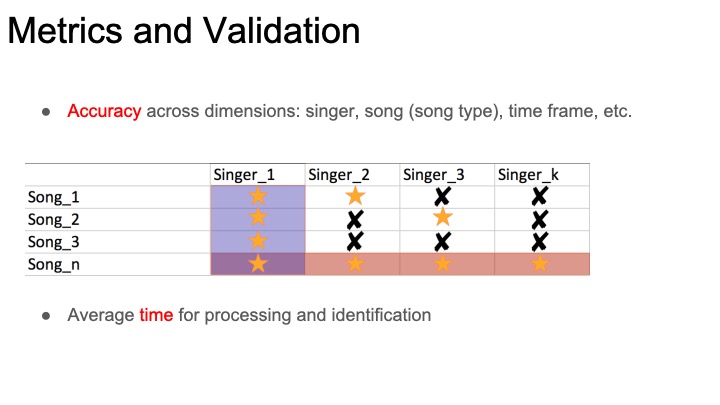
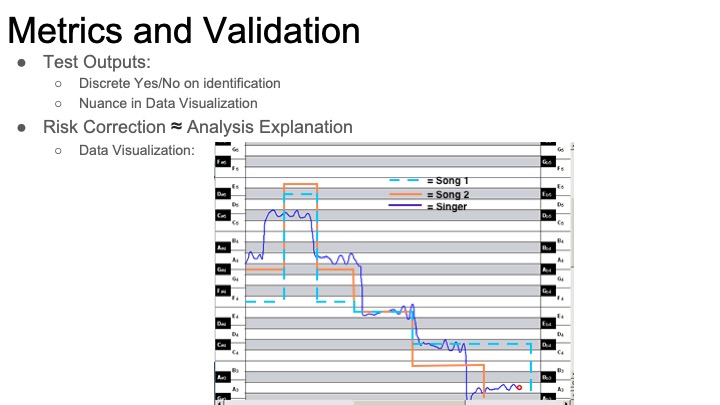
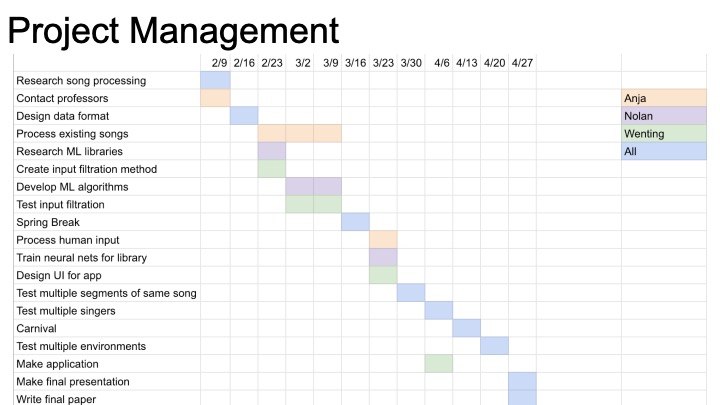
This week I began working on my arm of the project, the chroma feature similarity matrix analysis. Since the first step is building chroma features (also known as chromagrams), I’ve started looking into available toolboxes/code for creating these. Most of the existing work seems to be in MATLAB, so if I want to use an existing chromogram library I’ll have to decide between working in matlab and compiling to c++ or simply drawing inspiration from the libraries and building my own implementation. Even within chroma feature extraction, there are lots of design parameters to consider. There will be a choice between how the chroma vector is constructed (a series of filters with different cutoffs, or fourier analysis and binning are both viable options). On top of this, Pre and post-processing can dramatically alter the features of a chroma vector. The feature rate is also a relevant consideration: how many times per second do we want to record a chromagram?
Some relevant pre-and post-processing tricks to consider:
accounting for different tunings. The toolbox tries several offsets of <1 semitones and picks whichever one is ‘most suitable’. If we simply use the same bins for all recordings we may not need to worry about this? but also, a variation of this could be used to provide some key-invariance.
Normalization to remove dynamics–dynamics might actually be useful in identifying a song. We should probably test with and without this processing variant.
“flattening” the vectors using logarithmic features–this accounts for the fact that sound intensity is experienced logarithmically, and changes the relative intensity of notes in a given sample.
logarithmic compression and a discrete cosine transform to discard timbre information and attempt to get only the pitch info
Windowing different samples together and downsampling to smooth out the chroma feature in the time dimension–this could help obscure some local tempo variations, but its unclear right now if that’s something we want for this project. This does offer a way to change the tempo of a chroma feature, so we may want to use this if we try to build in tempo-invariance.
As it turns out, these researchers have done some work in audio matching (essentially what we’re doing) using chroma feature, and suggest some settings for their chroma toolbox that should lead to better performance, so that’s a great place for us to start.
an important paper from this week:
https://www.audiolabs-erlangen.de/content/05-fau/professor/00-mueller/03-publications/2011_MuellerEwert_ChromaToolbox_ISMIR.pdf
http://resources.mpi-inf.mpg.de/MIR/chromatoolbox/
http://resources.mpi-inf.mpg.de/MIR/chromatoolbox/2005_MuellerKurthClausen_AudioMatching_ISMIR.pdf