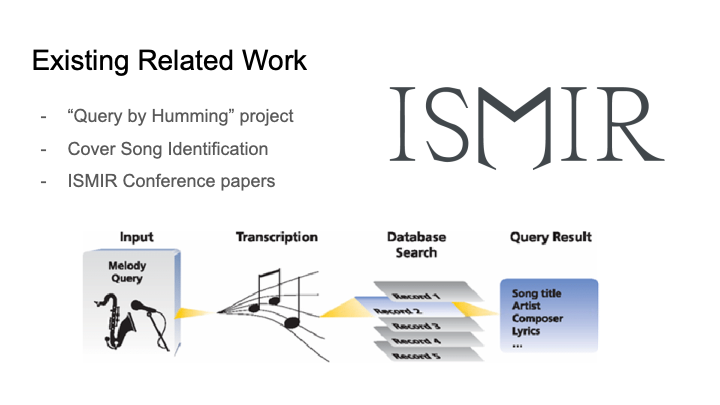
In the process of putting together the design presentation and design document, we have decided to take two parallel paths on our project, as described in our team status report. One will follow a similar path to the query by humming project that will match against a MIDI library, while the other will use chroma feature analysis to examine similarities between MP3s.
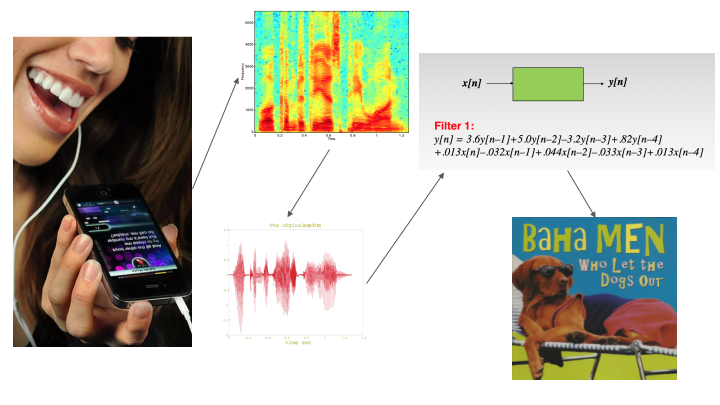
From the data visualization standpoint, the two approaches will be generating results in two different ways. Since the first approach will be borrowing work from other research, I am not completely sure how that will be able to be visualized – whether it will be a black box computation or whether I can extract out its process to display it. The second approach will follow what I mentioned last week with showing the similarity matrix.
While the UI design of the app will be done later, I have begun the process of deciding on its functionalities and features. Similar to the existing Shazam, users will tap to begin singing and matching. We hope to have sliders for the user to weight melody and rhythm differently depending on what they are more confident in. Once our algorithm has finished processing, it will pop up with the matched song or no match if it could not find anything. Either way, the user will be able to see some of the work that was done to match the song. The level of detail that we will show initially is yet to be determined (for example, we can include a “see more” button to see more of the data visualization aspect). The app will maintain a history of the songs that have been searched and potentially the audio files that it has previously captured, thus also maintaining a history of what has been matched to the song before as well.
Now that our design is more concrete, we have reached the phase where we are going to begin implementation to see how our methods perform. I would like to begin data visualization with some test data to see how different libraries and technologies will fit to our purposes. Also, in conjunction with Nolan, I will be looking into chroma feature analysis and using CNNs to perform matching.