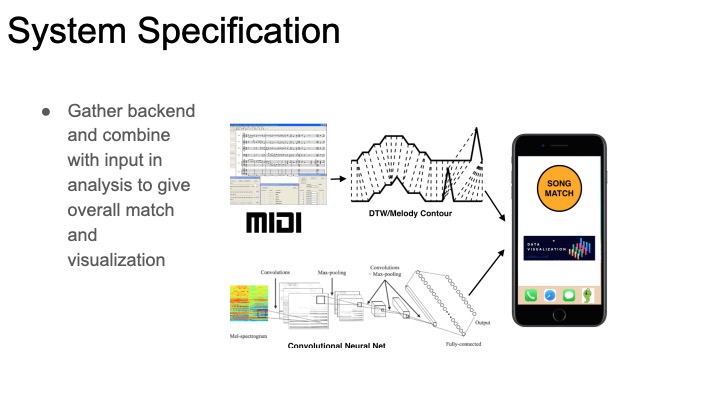
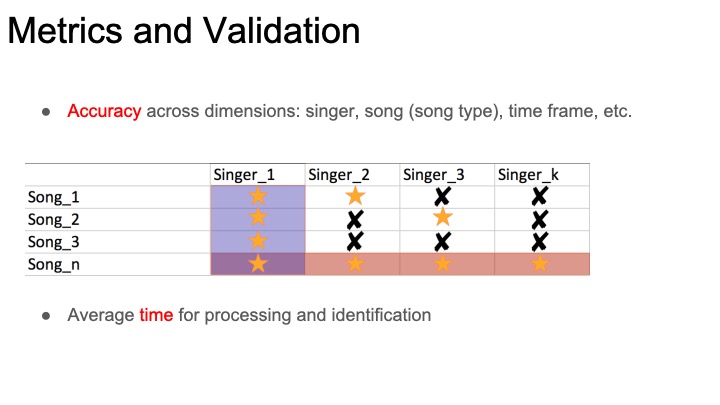
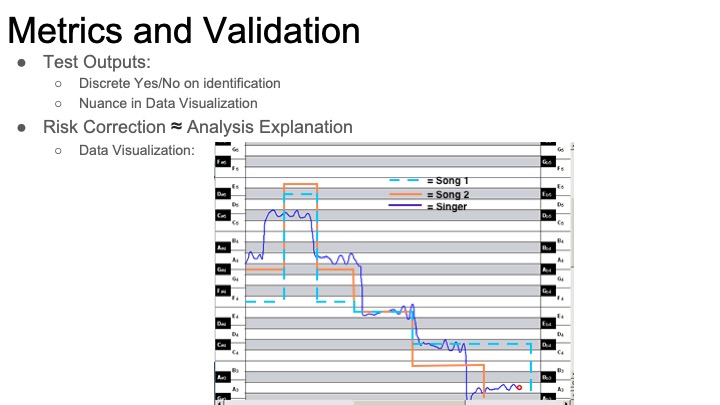
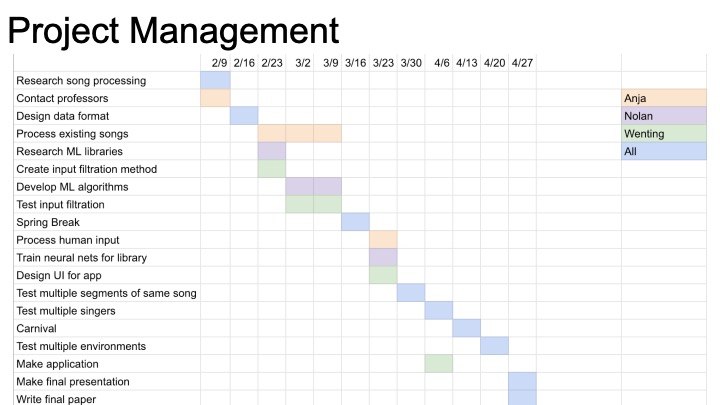
*Backlog from before websites were set up*
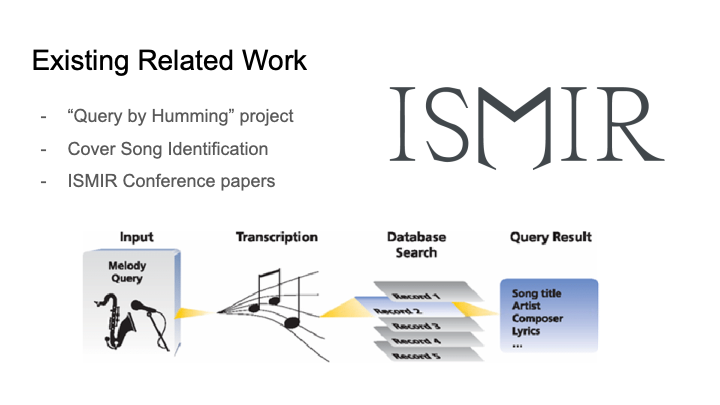
This week I did more thorough research into similar existing as well as related research that could be helpful for developing our solution. Roger Dannenberg, a CS professor whose primary field is computer music, has done a lot of work that is of interest for our project, including the query by humming project that we noted in our project proposal. We have been in contact with him and intend to meet with him soon.
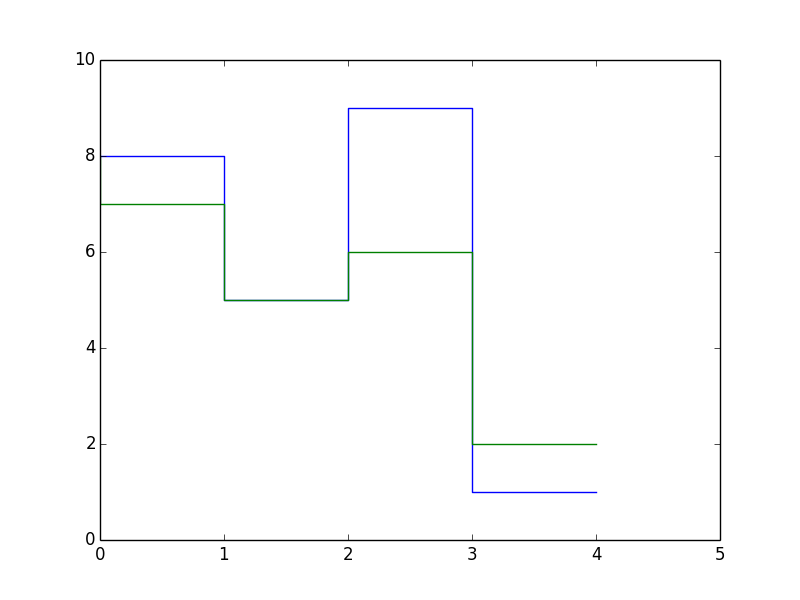
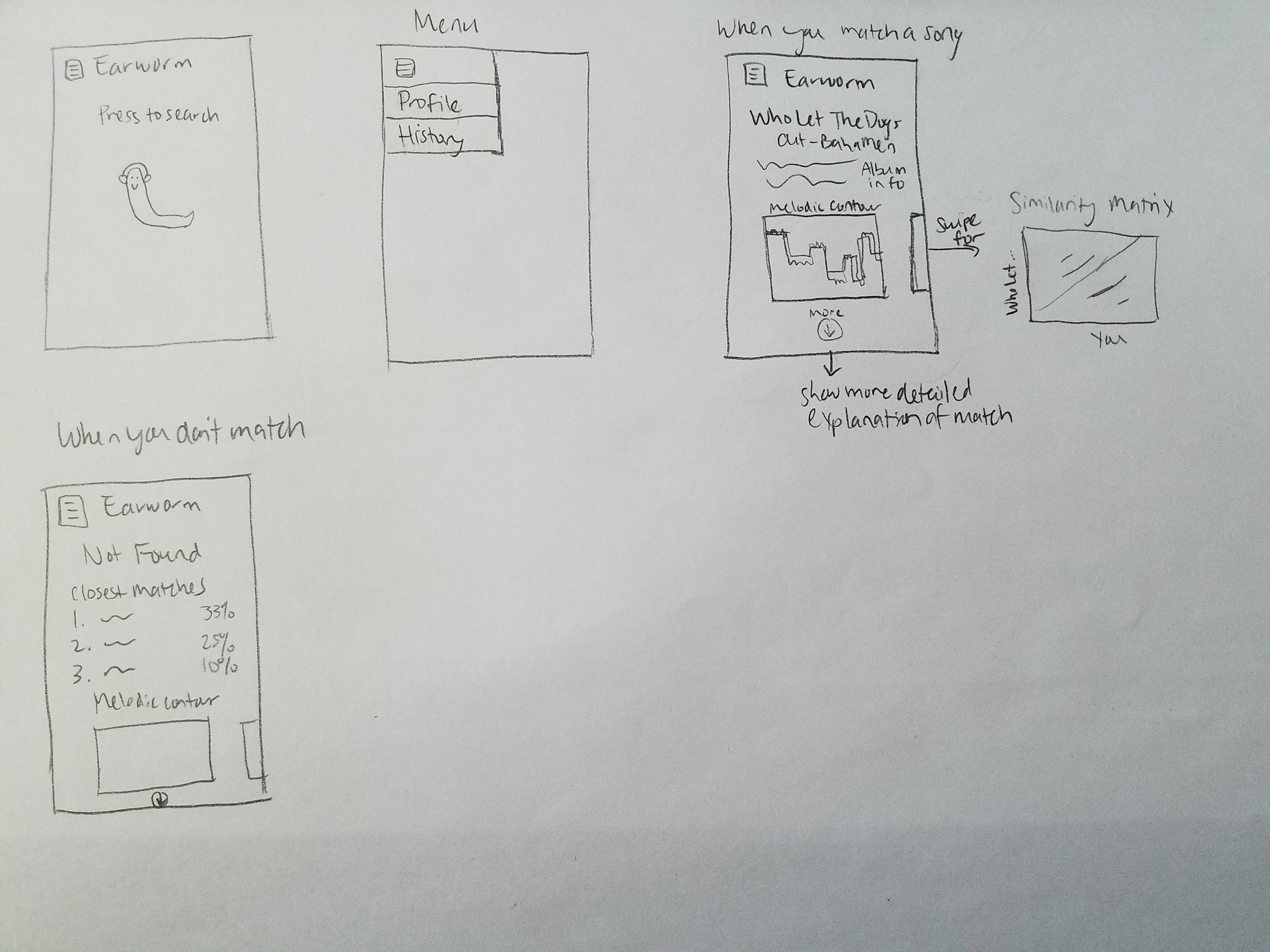
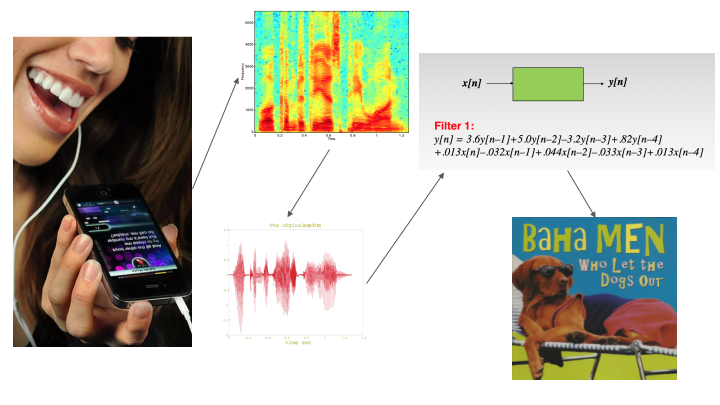
The projects I looked into were the MUSART query by humming project and his work in structural analysis. From studying the query by humming project, I found that our intended method for analyzing songs was more difficult and had more improbable success than previously thought. Our most ambitious idea was to analyze songs by breaking it down into multiple voices by applying concepts from polyphonic pitch tracking, but this project simply used pre-existing MIDI files for that instead of analyzing the raw audio of the songs. Also, looking at the performance of their system, our goal for 75% accuracy in recognizing songs may not happen. In order to counteract the possibility of our system not being able to match the song, I came up with the idea to do some sort of data visualization. Even if we are unable to find a match, the algorithm will have done some manner of work to try and match it. I would like to include that in the results of the query to demonstrate that it did, in fact, try to do something. An example of what it might show is a highlighted portion of melody that it matched between the input query and an existing song.
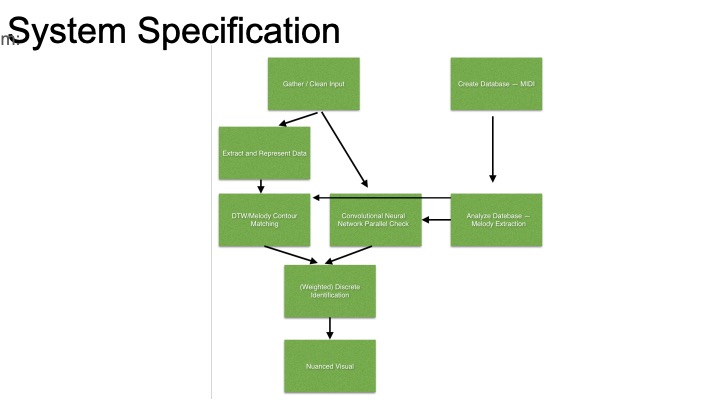
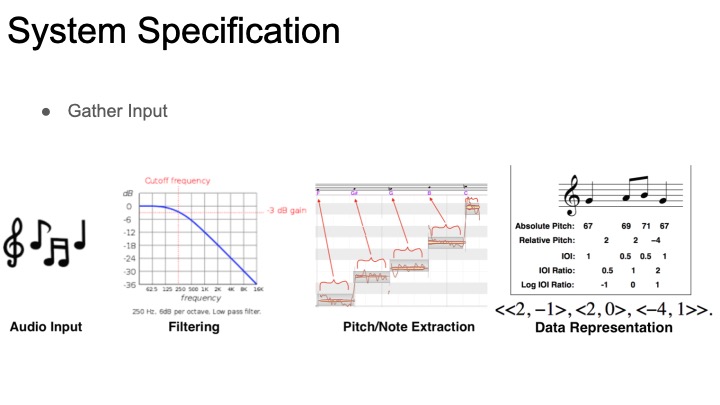
While browsing Professor Dannenberg’s work, I stumbled upon his work in structural analysis. The purpose of these projects was to make models that could analyze songs and provide an explanation of it, i.e. “the song is in ‘AABA’ form.” Our project’s intent is not that, but I figured the analysis methods from these projects were relevant to what we are trying to do. Much of this work was in looking for patterns in the music to discover the structure of the song, including ways to transcribe melody using monophonic pitch tracking, chroma representation, and polyphonic transcription. We will likely be doing something similar in order to extract information from the input sounds.
I am currently on schedule, but the research phase will probably continue into next week as we explore all our options and discuss further with professors such as Roger Dannenberg.
I’d like to have some semblance of our data format design, and I intend to do research into data visualization, though that will depend on the data format and matching method.