John’s Status Update (12/10)
This week I have been focused on the final integration steps for the web app, and in particular, the transfer of arrays from the note scheduler (that describes what notes to play at which sample time) to the front-end piano such that the correct set of key audios can be triggered all together. In this vein, I have worked to set up the infrastructure of receiving these 2-D arrays and playing through them with the corresponding piano audio files. I have tested the audio playback on several arrays and been able to reproduce the proper sounds. With the stream of data from the notes scheduler, we will be able to play the audio files necessary to recreate the audio.
I have been also working on the visualization aspect of the virtual piano such that users can see which keys are being played to create the sounds they are hearing. Here is a snippet of the piano playing a subset of a large array of notes:

With good progress in the audio processing parts, we have been able to listen back to audio files that have been processed to only include the frequencies of piano keys. With these audio recreations, we have a good baseline to compare our piano recreated sounds with that help us guide our optimizations.
Lastly, I have been looking at AWS instances to push our finished product to and have been researching good E2C instances that will allow the webapp to have access to several strong GPU and CPU cores to perform computation rapidly. Once set up, we will be able to conduct processing and audio playback very seamlessly and efficiently. We are planning to use an instance with at least 8 CPU cores as to be able parallelize our code through threading.
What is next is to polish the integration and data transfer between the 3 main sections of our code to optimize the user experience and push everything to the AWS instance.
John’s Status Report (12/3)
This week, I focused on attempting to recreate the input audio using piano key audio files. To do this, I needed several things: audio files for all keys on the piano (in order to reconstruct the sounds), a piano design for visualization on the web app, and JavaScript functions to interpret the note scheduler list and play the correct notes at each sample.
In terms of the audio files, I finally found all the necessary notes from a public GitHub (https://github.com/daviddeborin/88-Key-Virtual-Piano). This has allowed me to extract each note and utilize them for playback. With these files, I can play many in parallel, choose what volume to play them at (using information encoded from the notes scheduler), and whether I need to repress them or not on any given sample.
In terms of a piano visualization design, I was able to get a 69-key piano formatted for our webapp after drawing inspiration from and wrestling with the HTML, CSS, and JavaScript code from the Pianolizer Project (https://github.com/creaktive/pianolizer). Now, we are able to see a piano on our web app as the sounds are being played.
Up next, I am planning to tie everything together with the proper functions that allow for playing the notes in parallel for each time sample to recreate the audio. I will be using the piano design to change the color of the keys currently being played so users can visualize what notes are being played as they hear them. Lastly, I will be working with Angela to incorporate a speech-to-text analyzer for both the input and output audio to see if the program can capture the word being ‘spoken’ by the piano.
Team Status Report 12/3
This week, we revisited our rescoped project and laid out the plans amongst ourselves and the professors. In last week’s team status report, we went on a deep dive of our new scope (linked here for reference: Last Week’s Report).
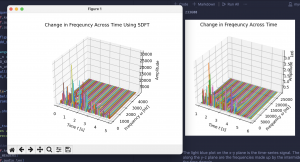
In terms of current progress in our overall project, we have focused efforts on rounding out playing back the processed audio using virtual piano notes through our web app. For the audio processing component, the system successfully implements a Sliding Discrete Fourier Transform to be able to capture amplitudes from the input audio at each specific piano frequency. This has allowed for accurate reconstruction of the audio using just the frequencies at each piano key. Below we have graphs showing the comparison of the reconstructed audio (left) and the original (right) in the above image. If the image quality permits, you can see how, by only using the piano keys, we are able to create a very similar Time vs. Frequency vs. Amplitude graph.
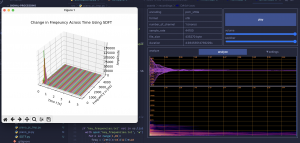
In this graph we have processed an audio file of just 1 piano key. We can see based on our audio processing the spike at the frequency of that key and the corresponding spectrogram showing the brightest color for that frequency. This was done as a way to prove that our processing is accurately capturing values for the input frequency and a bit of a sanity check.
For the Web app and note scheduling, we have been discussing the idea of incorporating the natural decay of piano keys to determine how we will determine whether a note will be re-pressed at any given sample and how we can playback the audio at different volumes using our web app. We have acquired audio files for every note, and using the 2-D array from the scheduler representing which of the 69 keys to play at each sample, we will be playing the corresponding audio file to recreate all the notes played at each sample.
This upcoming week, we are planning to take measurements of note accuracy, fidelity with understanding speech through the audio playback, and performing an inverse FFT on the audio (not using the piano note audio files as a medium) to compare the recreation using piano notes. As we wrap up our project, we are also preparing our presentation, final paper, and fine-tuning our performance metrics to meet the requirements we set for ourselves.
John’s Status Report for 11/19
This week, after settling on implementing our virtual piano interface instead of the physical piano, we rescoped our project and agreed upon some new parameters and features for our project.
In terms of the web app, we decided that it would be the start and end point for the user. What this means is that we offer the interface of recording an audio file or uploading a .wav file, next this uploaded audio gets sent to the audio processing and notes scheduling modules, lastly the results get displayed back on the web app and the audio is recreated using a virtual piano interface.
In terms of new features and parameters introduced, we are planning to add a speech-to-text library to create captions and have an objective way of testing fidelity of the output audio. Creating captions would help with interpreting the words ‘spoken’ by the piano and, by toggling them on and off, we can run experiments to see how easy it is to interpret the audio with and without the captions. Introducing a speech-to-text library would also allow us to take a speech-to-text reading of the initial, spoken audio and also one of the piano output, which we could compare to see if an objective program can understand the piano output.
This week, after coming together as a team to discuss these changes, I have mainly been focused on implementing a virtual piano interface on the web app. So far, I have found a well-documented repository (found here: https://github.com/creaktive/pianolizer) that emulates a very similar system to what we want. I have begun piecing it apart to understand how to create something similar and adding it to our own app. I am planning to extract the piano design and note visualization scheme used by the repository since this would save us a lot of time and it is mostly CSS and Image creation, which is a bit removed from the engineering concepts that we could implement more deeply in other areas of the project.
What is next is testing the full loop of intaking audio, processing it, then seeing it be played back. For this, we need more testing of the other modules and ‘glue’ code to form everything together and fine tune our testing parameters.
John’s Status Report for 11/12
Early this week, I was focused on polishing the web app for the demo. I was able to integrate the audio processing code such that when users upload an audio file, this file is accessed by the python audio processing code in order to perform the processing on it and output the audio with the piano note frequencies. In the process I realized some issues with file formatting of the recorded audio from the web app. The python processing code expects the audio to be in a .wav format with a bit depth of 16 (16 bits used for the amplitude range), however, the web app recorded in a webm format (a file format supported by major browsers). I attempted to configure the webm file as a wav directly using the native Django and JavaScript libraries, but there was still issues getting the file header to be in the .wav format. Luckily, we discussed as a group and came across a JavaScript library called ‘Recorderjs’ (https://github.com/mattdiamond/Recorderjs). This allowed us to record the audio directly to a .wav format (by passing the webm format) with the correct bitdepth and sample rate (48 kHz). With this library I was able to successfully glue the webapp code to the audio processing code and get the webapp intaking the audio and displaying all the graphs of the audio through the processing pipeline.
We were not able to get the final processed audio played back due to difficulty in performing the inverse Fourier transform with the data we had. In an effort to better understand Fourier transforms and our audio processing ideas, I talked to Professor Tom Sullivan after one of classes with him and he explained the advantages of using Hamming windows for the processing and how we could potentially modify our sampling rate to save processing time and better isolate the vocal range for a higher resolution Fourier transform.
With this information, we are in the process of configuring our audio processing to allow for modular changes to many parameters (fft window, sample rate, note scheduling thresholds, etc..). I am also fixing the audio playback currently so we can successfully hear the audio back and have an idea of the performance of our processing.
My plans for the upcoming week is to work with the group to identify how we will set up with testing loop (input audio with different parameters, hear what it sounds like, see how long the processing takes, evaluate, then iterate). I will also be integrating the note scheduling code with our backend such that we can control the stream of data sent to the raspberry pi via sockets.
Team status report for 11/5
This week, our team focus has been on establishing the requirements for our upcoming demo. We hope that by setting up our project for this demo, we can also have a platform built to test out parameters of our project and evaluate the results.
For our demo, we are hoping to have a web app that allows users to record audio to send to the audio processing modules. The audio processing will perform the Fourier Transform on the audio to get which frequencies comprise our audio. We will then take the frequencies that correspond to the keys of the piano and filter the frequencies of the recorded audio such that the only remaining frequencies are those that the piano can produce. This filtered set of frequencies represents what notes of the piano can be pressed to produce the snippet of audio. These many snippets of frequencies (at this point filtered to only contain those the piano can produce) are then sent to the note scheduler that takes in which notes to play and outputs a schedule representing when to play each key on the piano. This note scheduling module is important as it will help to identify whether a particular note’s frequency is present in consecutive samples, thus handle the cases of whether we need to keep a note pressed between many sample, re-press a note to achieve a new, higher volume, or release a note so that the frequency dies out. Lastly, these many audio samples, only containing piano frequencies, will be stitched together and played back through the web app. The audio processing module also creates graphical representations of the original recording (as time vs amplitude) and the processed recording (as time vs filtered amplitude- representing the piano keys) and displays them to the user.
Our goal with this demo is to not only show off a snippet of our project pipeline, but also provide a framework to test parameters and evaluate the results. We have many parameters in our project such as window of time for the FFT, window of frequencies to perform averaging for each note, the level of amplitude difference between consecutive frequencies that determine whether we re-press a note or keep it pressed down, just to name a few. We hope that with this demo, we can fine tune these parameters and listen to the output audio to determine whether the parameter is well-tuned. The output playback from our demo is the sound we would hear if the piano were able to perfectly replicate the sound with its available frequencies, so if we use our demo to test an optimal set of parameters, this will help the piano recreate the sound as best as possible.
We have also placed an order through AliExpress for a batch of solenoids. It is set to come in by the 11th of November. We will evaluate the effectiveness of the solenoids and quality from the AliExpress order, and if the solenoids are good, we will place an order for the rest of the solenoids we need.
In the next weeks, we are planning to define tests we can perform with our demo program to tune our parameters. We will also be planning how to test the incoming batch of solenoids and what will determine a successful test.
John’s Status Report for 11/5
This week, our group was focused on defining the requirements for our interim demo. For my part, I am working on the web app that users will interface with to record audio, upload it to the audio processing part, then see the results of the audio processing and piano key mapping displayed in graph form.
So far, I have added more to the web app, allowing users to visit a recording page and speak into their computer microphone to record their speech. As of now, I am using the videojs-record JavaScript package to record the user audio and display the live waveform of recording. This package includes many features and plugins that allow for efficient audio recording and easy implementation within our Django web app framework.
Currently, the user records the audio and this file gets stored in a local media folder as well as in a model on the sqlite3 backend. This allows different pages of the webapp to access these models so that the user can play back the audio or select a previously recorded clip to send to the piano.
What’s next is connecting up the audio processing and note scheduling modules written by Marco and Angela to the web app. Once we have uploaded their portions to the web app, we can work to pass in the recorded audio to these modules then displaying the outputs back onto the web app.
John’s Status Report 10/29
This week, I was focused on 2 main things: helping to restructure our circuit power design to be much safer and getting a basic web app interface initialized.
In terms of the power redesign, Professor Tamal pointed out the large safety issue with our power supply in his feedback for our design documentation. Originally, we wired all 69 of our solenoids in parallel to a main power bus that would carry current to distribute amongst all the solenoids. This would mean that the bus would need a whopping ~30A supplied to it. This introduced a large safety concern and difficulty getting large enough wires for the bus that we could connect the solenoids to directly. Luckily, with some help from the player piano builders Discord we are a part of, I got some inspiration from the pictures showing people using multiple power supplies. With this we decided to split our large power supply into 9 smaller ones. This would allow us to group together batches of 8 solenoids and power them each with a 3A power supply. This is a much safer option since household and microcontroller electronics run on this amperage. This also allows us to also use more standard wire gauges and connectors for the solenoids.
In terms of the web app initialization, I created a preliminary app using Django as the overall framework and sqlite3 as the backend database. For our web app, we will be hosting a basic user audio playback interface consisting of controls to upload recordings, save recordings, and pause/play the piano playing. The only data we need to store are processed .wav files saved as text files describing the scheduled notes. We are using sqlite3 for the backend management engine since it is simple to use and I am familiar with it from learning web development in the CMU webapps course. With sqlite3, it is not very tailored to storing large files, however we will be keeping our processed files in a media folder on the AWS EC2 instance, as it can hold more data anyways, then we will store file references in the sqlite3 backend.
For the next week, I will begin getting our audio processing modules on the web app and being able to interact in basic ways. I will work with the team to flush out an interface protocol to know how the user interface will be sending commands to the audio processing and note scheduler.
John’s Status Report 10/22
This past week, I worked alongside Marco and Angela to clearly scope out our entire project design, identify trade-offs in our choices, and redefine our priorities to finish the design doc, begin our audio processing, and ultimately finish our project on time. In the week before fall break, we set a team deadline to finish and test our proof of concept design before our design doc was due and start on the audio processing component of our project. I was tasked with writing various sections of our design doc as well as those pertaining to my specialized areas (web-app and physical system).
Along-side writing our design doc, I put my time into defining what a successful proof-of-concept design looked like for our physical system and how we could go about designing it. To recall, our physical system will consist of 69 cylindrical solenoids fixed to a solid chassis that will be placed on top of the keys of a piano and activated electronically to press the keys. The solenoids will be controlled from a Raspberry Pi and several shift registers connected to MOSFETs that allow or block current flow into each solenoid. For our proof-of-concept, we ordered 5 smaller solenoids of similar type as our final product, MOSFETs, and Shift registers. Our plan was to use an Arduino and simple programs to drive the shift registers connected to each solenoid to prove that we could not only drive multiple solenoids at once and correctly calculate power-needs, but also to input patterns for solenoid activation that closely simulates the note scheduling we would be doing for the final physical system. After deep diving into spec sheets for our solenoids and shift registers, we were able to successfully program several patterns of activation for our solenoids and time them appropriately. (A video is linked showing the activation of 3 solenoids each second in a simple pattern).
Link to my drive for video showing 3 solenoids activating in pattern.
On top of the proof-of-concept tests with activating solenoids in a pattern, I also implemented a test for seeing how fast the play-rate is for 1 solenoid. This would affect how many sounds we could produce per second. As Angela found out, the English language can speak up to 15 phoneme (a phoneme is the smallest unit of speech distinguishing one word / word element from another) per second, which may require us to produce up to 15 sounds per second. This test confirmed that we are able to reproduce this upper bound if necessary. (A video is linked below showing the solenoid play rate at 16 times per second).
Link to my drive for video showing play rate at 16Hz.
Overall, these experiments have given us confidence in our ability to design and create the overall physical system reliably. We have also discovered some helpful resources along the way (thanks to an online forum of self playing piano makers that Marco found) that have allowed us to focus less on the physical design of the chassis and more on our unique circuity idea, audio processing, note scheduling, and web app.
For the remainder of the Fall break and the following week, I will be helping to plan out the audio processing and note scheduling as well as setting up the web app for hosting the above mentioned systems.