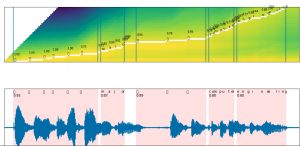
This week, we focused on tuning the model parameters and silence chunking system to further increase accuracy of our system and prepared for the final demo next week.
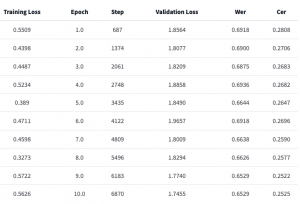
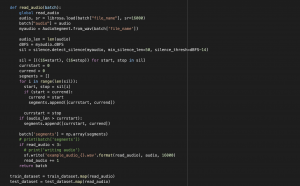
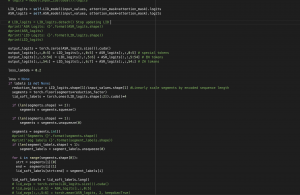
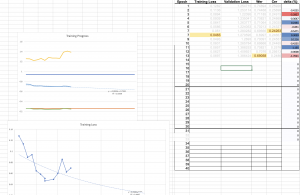
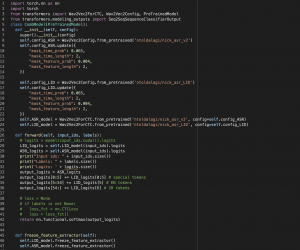
First, we finished making the final presentation this week and the final poster for the demo next week. In addition, we did some fine-tuning on the LID model and solved our model’s problem for switching languages really quickly to the point where the segment is shorter than the minimum input for the ASR model. The short segments are often inaccurate since they are shorter than an average normal utterance of 0.3 seconds. To address this issue, we set a minimum threshold for each segment to be at least 0.3 seconds long and merge the short segments with nearby long segments. This approach improved CER by about 1%.
On the web app end, this week we mainly focused on tuning the hyperparameters used in our silence chunking logic to enhance the balance between robustness, accuracy and real-timeness of our system.
By testing our app with different audio input devices, we observed that our system required different amplitude threshold values to work optimally for different input devices. Thus, we changed our system’s silence threshold value to the minimum of the various optimal values observed so that we could have the fewest false positive detections of silence which could lead to chunking into a single word by mistake and getting false transcription.
Next, we tested the optimal minimum silence gap length that triggers a chunk. Through testing, found the minimum 200ms of gap to be optimal, which avoids breaking a word but promptly captures a complete chunk and triggers a transcription request for that chunk. A minimum silence gap longer than 200ms would sometimes cause a transcription request to be delayed for several seconds if the user is speaking with little pause, which violates our real-time transcription requirement.
Finally, we modified the frontend logic that combines multiple chunks’ transcription and fixed the problem of multiple chunks’ transcription being concatenated together (for example “big breakfast today” would be displayed as “big breakfasttoday”).
For next week we plan on fixing some minor issues with the system, especially with the silence detection. Currently, the silence detection is using a constant decibel as the threshold, but this could be problematic in a noisy environment where the average decibel is higher. We will also finalize the hardware devices needed (including a noise cancellation microphone) for demo.