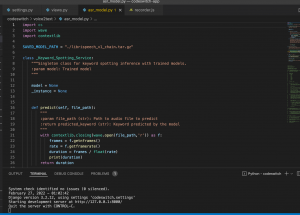
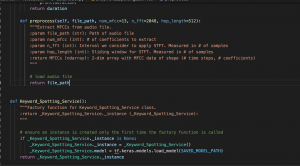
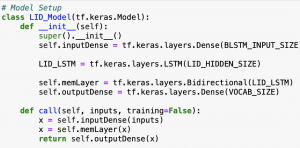
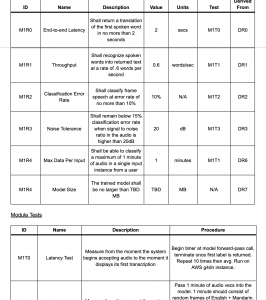
For this week, I primarily focused on getting different tokenized outputs for Chinese characters. As discussed in last week’s report, there are many different ways to define the output space, and each possibility may result in different performances in the final model. The most simple and naive way is to use the actual characters. Some existing models I found using this approach achieved a character error rate of around 20%. This approach works, but there is definitely room for improvement. The second approach is to use pinyin as the output space. This drastically reduces the size of the output space, but does require a language model to convert pinyin into actual characters. A paper published this year by Jiaotong University reported that their model achieved a character error rate of 9.85%.
We also discussed some implementation ideas for performing a real-time transcription system. One idea is to use a sliding window. For instance, an audio segment from 0s to 4s will be sent to the server, then 1 second later the audio segment from 1s to 5s will be sent. The overlapped regions are then compared and aggregated by the relative output probability. This approach, theoretically, would maintain context information, which leads to a higher transcription accuracy, and process in a short span of time.
Overall, I am on schedule for this week. For next week, I plan on training some models transcribing Chinese using the output spaces mentioned above on Amazon Web Service. I also plan on doing some research on Amazon SageMaker, which is a fully managed machine learning service that could be easier and cheaper to use than a EC2 instance.