This week I focused on fixing the empty audio issues when sending ongoing recording audios in chunks to the backend and further tested our app performance when the model size used is large.
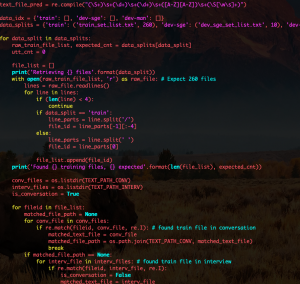
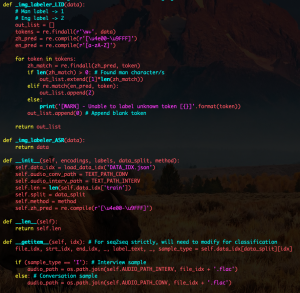
After my research on the cause of the audio chunk transfer issue, I found that the mediaRecorder API automatically inserts some header information into the audio bytes. This header information is crucial for proper functioning of the backend audio processing tool “ffmpeg”, so it means that I could not just naively needlepin into the frontend audio bytes, send them in chunks and expect the backend to successfully handle each chunk because not every chunk would have the necessary header information.
As an alternative strategy to achieve the audio chunking effect (in order to make our ML model only run on each audio chunk once as opposed to have to redundantly run on the audio from the very beginning of the recording session), I performed experiments on the conversion ratio of byte sizes of a same audio in webm format and wav format. Having the conversion ratio, I can approximate on the backend where I should cut the new wav file (containing all audio data from the beginning of the recording session) to get the newest audio chunk. In this case, I can feed the approximate new audio chunk into our model and achieve the same effect of sending chunks between the client and server.
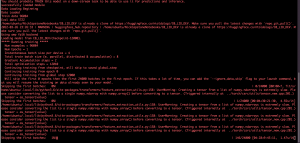
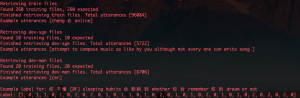
After the fix, the system is able to run fairly efficiently achieving an almost real-time transcription experience. I further tested the system run speed with larger models.
For large model testing, I continued using “jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn” for the Mandarin ASR model and tried a new and larger “facebook/wav2vec2-large-960h-lv60-self” English ASR model. It verifies that our current deployment and chunking strategy is feasible for deploying our own model.
Next week, I am expecting to get the first trained version of the language detection model from my teammate Nicolas, and I will begin integrating language detection into the deployed app.
Currently on the web application side, there has not been any major timeline delay. Potential risks include that our own trained models might run much slower than the models I have tested so far. Also, it would require further research for tutorials on how to join multiple models’ logits together.
Another concerning observation I saw as I achieved the audio chunking effect was that the model only suboptimally predicted each chunk while not achieving a high transcription accuracy at sentence level. This is a problem we need to discuss as a team for a solution.