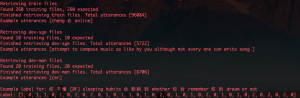
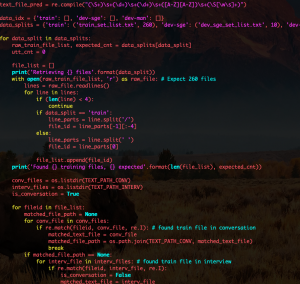
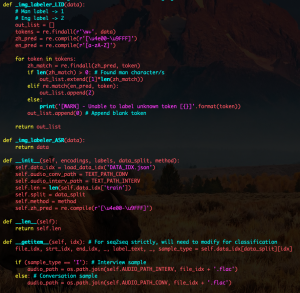
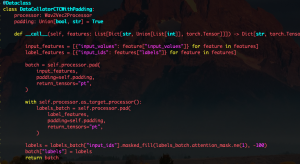
Since the last update, I’ve finished writing all the infrastructure needed for complete training of our LID and ASR models on the SEAME dataset. Due to a unique directory configuration, multiple sets of labels, and un-split test and training datasets, this all needed to be accomplished by an indexing process. I completed a script that indexes and stores all of the labels associated with each file and each possible utterance within each file. It was about 10MB and can be loaded extremely quickly. Using this index, we are now able to create separate data loaders for the separate tasks which are then capable of labelling our data as needed for the application. The index has also separated the data into training and test sets. One test set is biased towards Mandarin while one is biased towards English. I also completed an implementation of a data collator which is be used to make training as efficient as possible during forward passes of batches. Training now continues on the LID model end-to-end.
I’m on schedule for delivering the working LID model. This week will just be about supporting and continuing training. There will also be a small amount of coding needed just to set up running both combined models jointly (combining their outputs etc.).