
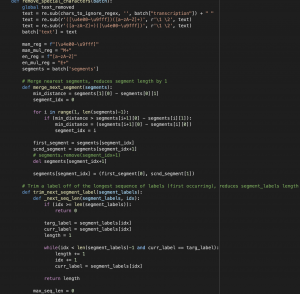
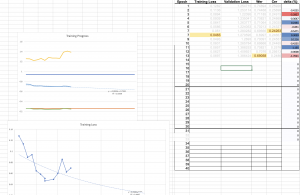
We’ve continued to push the model performance by updating the architecture and techniques used to more closely align with our guiding paper. This week we achieved a 20% reduction in the WER on our toughest evaluation set by using a combined architecture which creates LID labels using a novel segmentation technique. This technique create “soft” labels which roughly infer the current language using audio segmentation which is then fused with the golden label text. Training and hyper-parameter tuning will continue to till the final demo, we anticipate there is likely room to get another 15% reduction in the error rate.
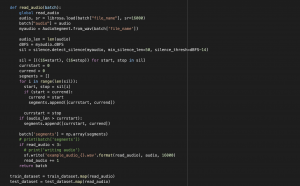
On the web app end, we finished implementing an audio silence detector on the JavaScript frontend and another backend transcription mechanism. The silence detector in the frontend detects a certain length of silence as the user is recording and only sends a transcription request when there is a silence gap detected and the backend model will only analyze the new audio chunk after the most recent silence gap. In this way, we would resolve the problem we had before with a single word being cut off since we were cutting the audio into 3 second trunks arbitrarily.
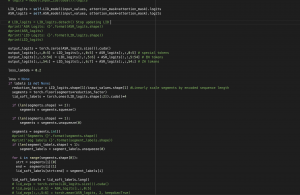
The new backend transcription mechanism takes in a piece of audio, tags each frame of the input audio with a language tag (<eng> for English, <man> for Mandarin and <UNK> for silence), breaks the input audio sequence into chunks of smaller single-language audio sequences and feeds each chunk to either a English or a mandarin ASR model. In this way we can integrate advanced pretrained single language ASR models into our system and harness their capability to enhance our system accuracy.
Below is the video demonstration of the silent chunking mechanism + our own mix-language transcription model.
https://drive.google.com/file/d/1YY_M3g54S8zmgkDc2RyQqt1IncXd5Wxo/view?usp=sharing
And below is the video demonstration of the silent chunking mechanism + LID sequence chunking + single language ASR models.
https://drive.google.com/file/d/1bcAi5p9H7i9nuqY2ZtgE7zb4wOuB0QsL/view?usp=sharing
With the silent chunking mechanism, we observed that the problem we had with a single spoken word being cut into two pieces audios was resolved. And we can see that the mechanism that integrates LID sequence chunking + single language ASR models demonstrates a higher transcription accuracy.
Next week, we will be focusing on running evaluation of our system on more diverse audios. We will also try adding Nick’s newly trained model into our system to compare with the current accuracy. So far we are a little delayed on our evaluation schedule because we were trying to enhance our system further by adding the mechanisms above. We do expect to finish the evaluation and further parameter tuning (silence gap length threshold and silence amplitude threshold) before the final demo.