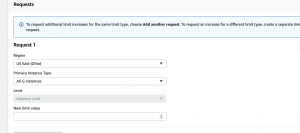
This week I was focused heavily on two things: aggregating all of the datasets and material I will need for development and getting them uploaded on my remote development environment (AWS), drilling down into the metrics, requirements, and detailed design of our whole system for the design review. On the development side, I was able to retrieve and store the latest wav2vec 2.0 model for feature extraction specifically targeting mixed language inputs. Marco and I will be able to further fine-tune this model once we reach system-level training of the ASR model. I was also able to register and am waiting for final approval to gain full access to the SEAME code-switching dataset for Mandarin and English. Marco was granted access within a day or two so I plan to have full access to that data by Monday. My final setup for my remote Jupyter notebook is also fully configured. Using dedicated GPU instances, we’ll be able to train continuously overnight without having to worry about up-time interruption.
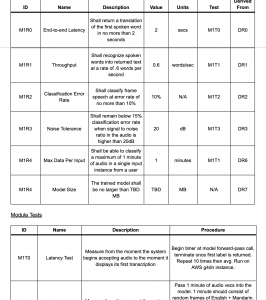
On the design side I completed detailed design documentation for each of the modules I will be either entirely or partially responsible for (Modules 1, 3, 7) with traceability matrices for requirements, unit testing, and validation. Each requirement can trace upwards to design-level requirements, and downwards to a specific test for easy tracking of how lower level decisions have been informed by high-level use case targeting. I added all of these matrices along with system-level versions of them to our ongoing design review document which also includes module-level architecture descriptions and interface details between modules.
I’m currently on-track with my planned work. Since Marco was able to gain access to the SEAME database, it has freed both of us up with an extra two-days in the schedule for either training work or system integration work at the end of the semester. This week I will plan to finish our design review presentation, our design review document, and target having a first version of the LID model initialized and ready for initial training by next weekend.
![]()