On web app side, we focused on enhancing the accuracy of output transcriptions through some autocorrect libraries and building features of our web app that demonstrates the effects of using multiple approaches, including periodically resending the last x-second audio for re-transcription, resending the entire audio for re-transcription at the end of a recording session and chunking the audio by silence gaps with different silence chunking parameters.
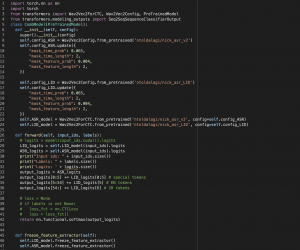
We switched the app’s transcription model to Nick’s newly trained model, which shows a significantly higher English transcription accuracy; however, both languages’ transcription is not perfect yet with some misspelled English words and non-sense Chinese characters, so aside from continuing our model training, we are looking for autocorrect libraries that can autocorrect the model output texts. The main challenge for using existing autocorrect packages is most of them (e.g. autocorrect library in python) only deals with well when the input is in one language, so we am experimenting with segmenting the texts into purely English character substrings and Chinese character substrings and run autocorrect on these substrings separately.
We also integrated all 3 approaches we tried for re-transcription before into our web app so that there is an entry point for each of these approaches, so during the final demo, we can show the effect of each of these to our audience.

Next week we will finish integrating an autocorrection libraries and also look for ways to map our transcription to a limited vocab space. After these two actions, we hope to eliminate the non-English-words being generated by our app. If time allows, we will also add a quick redirection link on our web app that quickly jumps to google translate to translate our codeswitching transcription, so that our audience that do not understand Chinese can understand transcription in our demo.
On the modeling side we are currently working on training a final iteration of fused LID ASR model which has some promise to give the best performance seen so far. Earlier this week we were also able to train a model which improved our CER and WER metrics across all evaluation subsets.