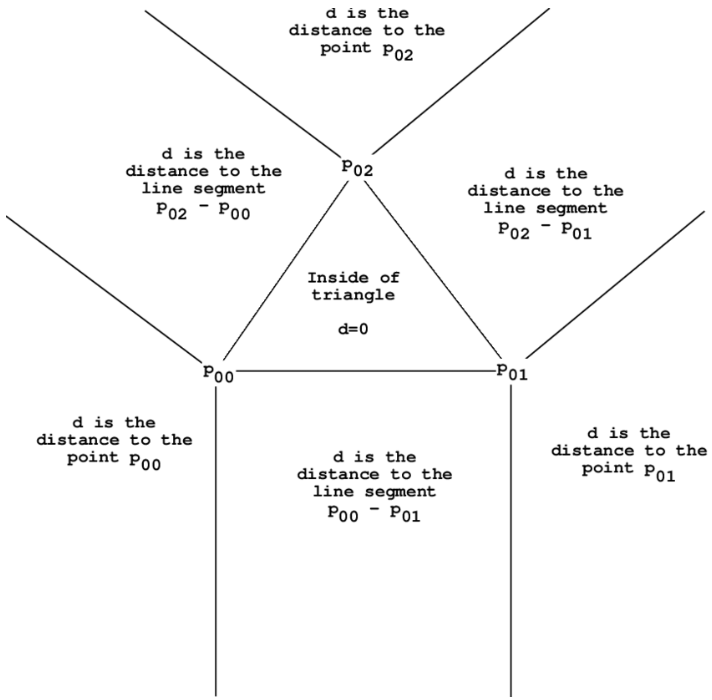
This week I have been practicing for the design review presentation, as well as working on the design review document. While we have figured out all of the components of our design prior to this week (the laser, the camera, and the algorithms to compute point clouds), many details needed to be ironed out.
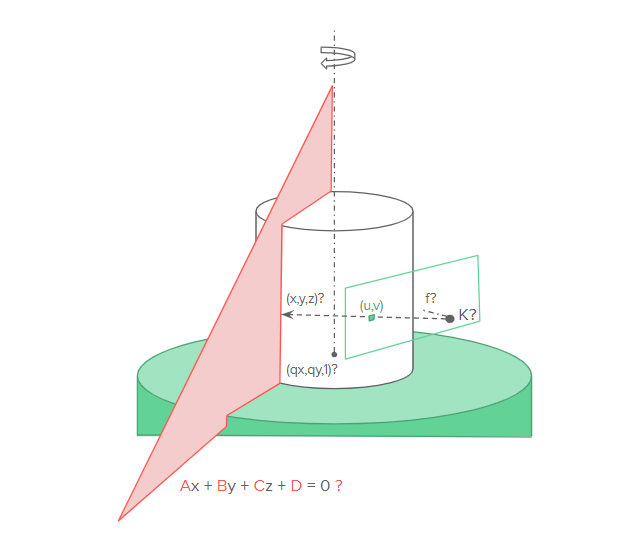
Specifically, I worked out some of the math for the calibration procedures which must be done prior to scanning. First of all, intrinsic camera calibration must be done, which resolves constants related to the cameras lens and polynomial distortion that may have. This calibration helps us convert between pixel space and camera space. Secondly, extrinsic camera calibration must be done, which solves a system of linear equations to find the translation and rotation matrices for the transformation between camera space and world space. This system is made non-singular by having sufficiently many known mappings between camera space and world space (specific identifiable points on the turntable). Thirdly, the axis of rotation for the turntable must be computed in a similar manner to the extrinsic camera parameters. Finally, the plane of the laser line in world space must be computed, which requires the same techniques used in the other calibration steps, but since the laser line is not directly on the turntable, an additional known calibration object must be placed on the turntable.
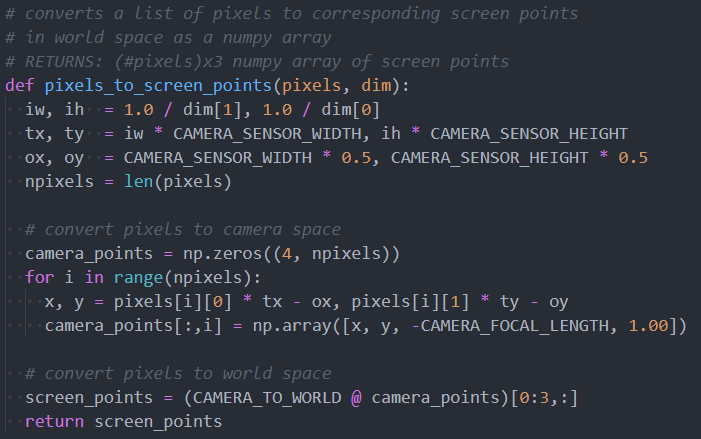
The method for transformation between pixel space and world space is given by the following equation:
λu=K(Rp+T)
Where K and λ are computed during intrinsic camera calibration, and R and T are computed during extrinsic camera calibration. We can then map the pixel where the center of the turntable is to a point in world space, q, with a fixed z=0, and a rotational direction of +z (relative to the camera perspective).
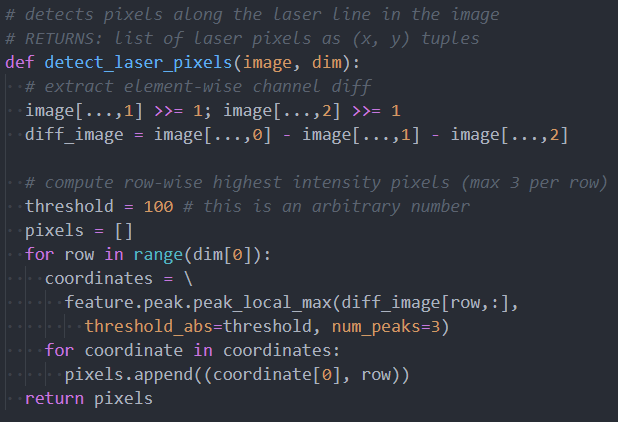
To calibrate the plane of the laser line, we first need image laser detection. We will compute this by first applying two filters to the image:
- A filter that intensifies pixels with color similar to the laser’s light frequency
- A horizontal gaussian filter
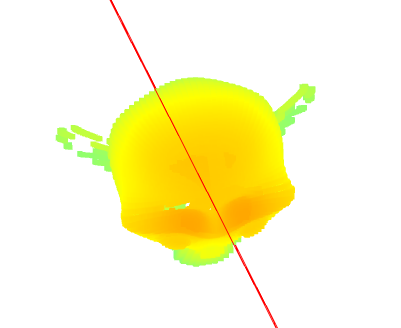
Then, for each row, we find the center of the gaussian distribution and that is the horizontal position of the laser line. If no intensity above a threshold is found, then that row does not contain the laser. Note that this solution prevents detection of multiple laser points within a single row, but this case will only occur with high surface curvature and can be resolved by our single-object multiple-scan procedure.
Laser plane calibration then happens by having a flat object on the turntable to allow for image laser detection. This allows us to find a set of points which are on the plane, which we can use to then solve a linear equation to compute the A, B, C, and D parameters of the plane of the laser line in world space. There is a slight caveat here. Since the laser itself is not changing angle or position, the points we capture do not identify a single plane, but rather a pencil of planes. To accommodate this, we will rotate the known calibration object (a checkerboard) to provide a set of non-collinear points. These points will allow us to solve the linear equation.
Calibration parameters will be solved for in the least-squared error sense, to match our recorded points. Global optimization will then be applied to all the parameters to reduce reconstruction error. Our implementation of optimization will probably consist of linear regression.
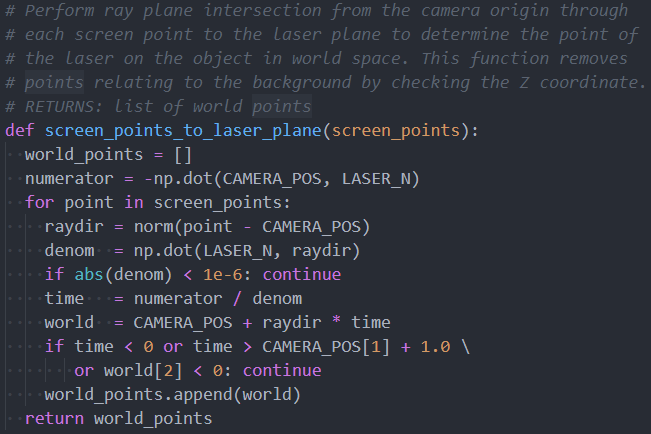
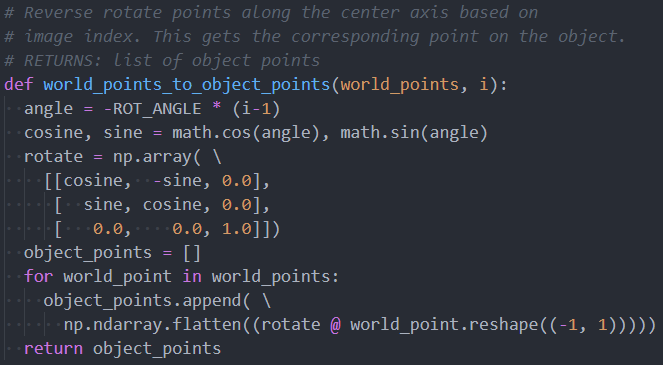
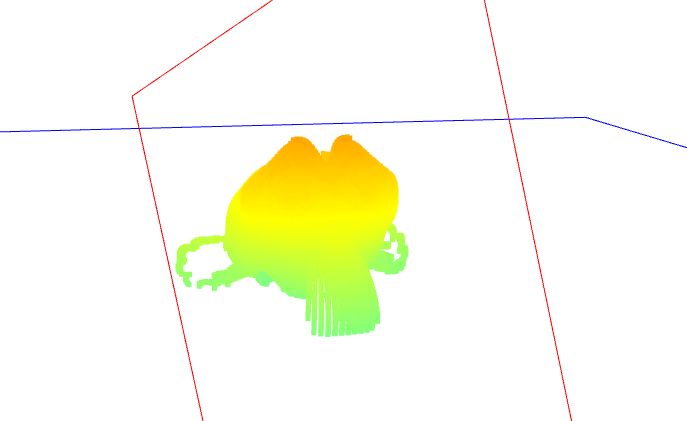
Once calibration is done, to generate 3D point cloud data we simply perform ray-plane intersection between the ray originating at the world space of the pixel with the laser line away from the camera position towards the laser plane in world space. This point is in world space coordinates, so it must be un-rotated around the rotational axis to get the corresponding point in object space. All such points are computed and aggregated together to form a point cloud. Multiple point clouds can then be combined using pairwise registration, which we will implement using the Iterative Closest Points (ICP) algorithm.
The ICP algorithm aims to compute the transformation between two point clouds by finding matching points between the point clouds. It is an iterative process that may converge on local minima, so it is important that multiple scans are not sufficiently far from each other in terms of angles.
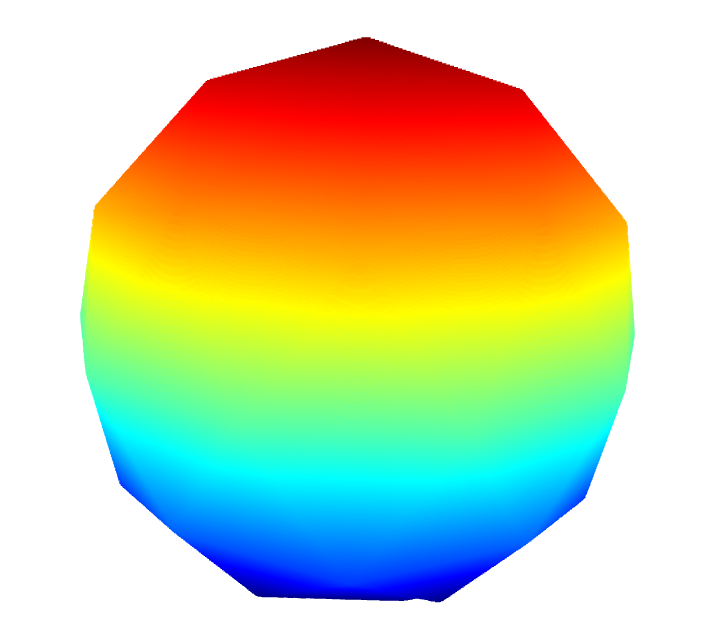
Background points during 3D scanning can be removed if they fall under an intensity threshold in the laser-filtered image, and unrelated foreground points (such as points on the turntable) can be removed by filtering out points with a z coordinate of close to or less than 0.
Since we will not be getting our parts for a while, our next steps are to find ground truth models with which to test, and begin writing our verification code to test similarity between our mesh and the ground-truth. To avoid risk related to project schedule timing (and the lack of significant remaining time), I will be writing the initial prototyping code next week so that once the parts arrive we can begin early testing.