With our updated requirements (an effective Engineering Change Order (ECO) made by our group in a manner parallel to that of the manner by which P6 perhaps accomplished the same goals, with plenty of paper work and cross-team collaboration required), we began the week ready to once and for all tackle the issue that has plagued us for the last two weeks: choosing a specific sensor. From the quantitative results we require for our device to produce, we worked forward in a constructive logical manner to determine which components would be required. Our final project requirements are below:
Requirements
- Accuracy
-
-
-
- 90% of non-occluded points must be within 2% of the longest axis of the object to the ground truth model points.
- 100% of non-occluded points must be within 5% of the longest axis of the object to the ground truth model points.
-
-
- Portability
-
-
-
- Weighs less than 7kg (weight limit of carry-on baggage)
-
-
- Usability
-
-
-
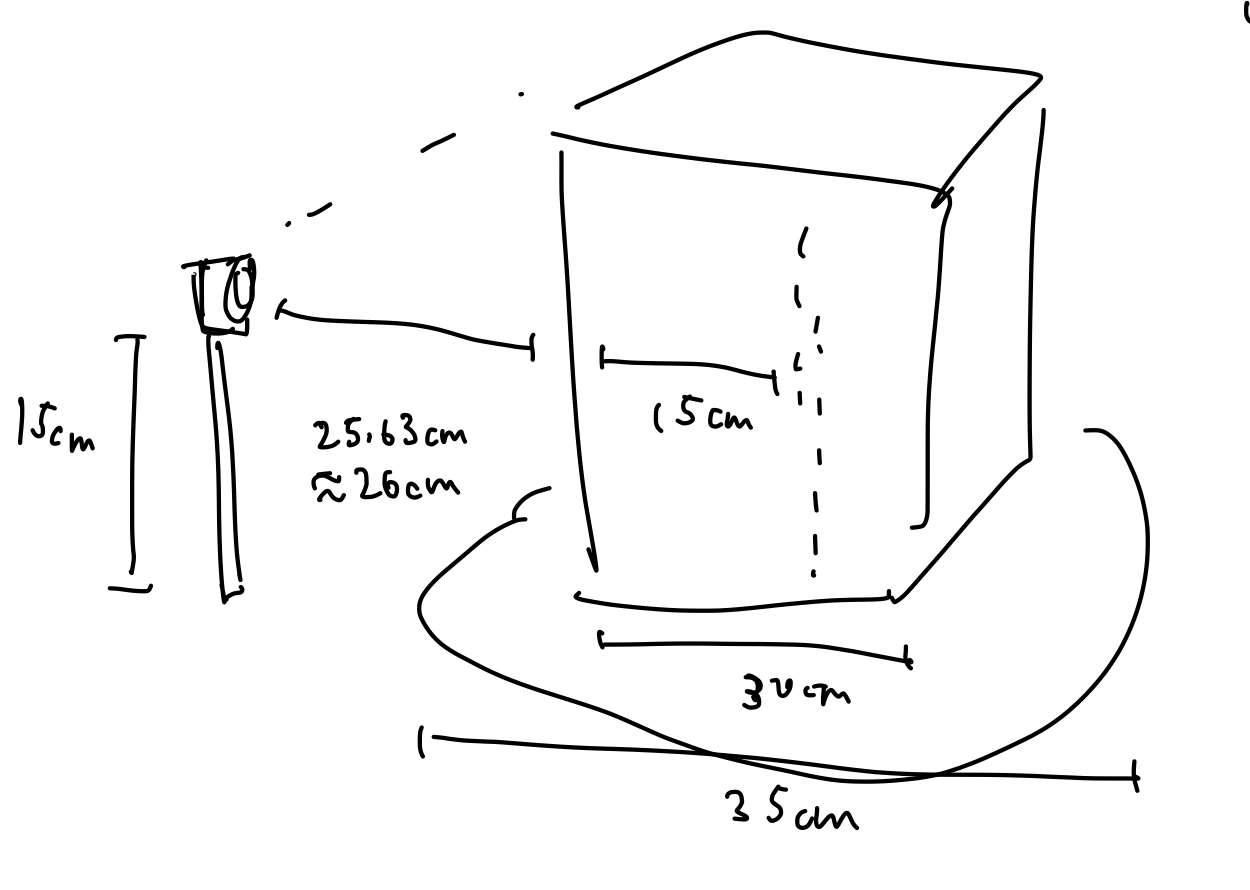
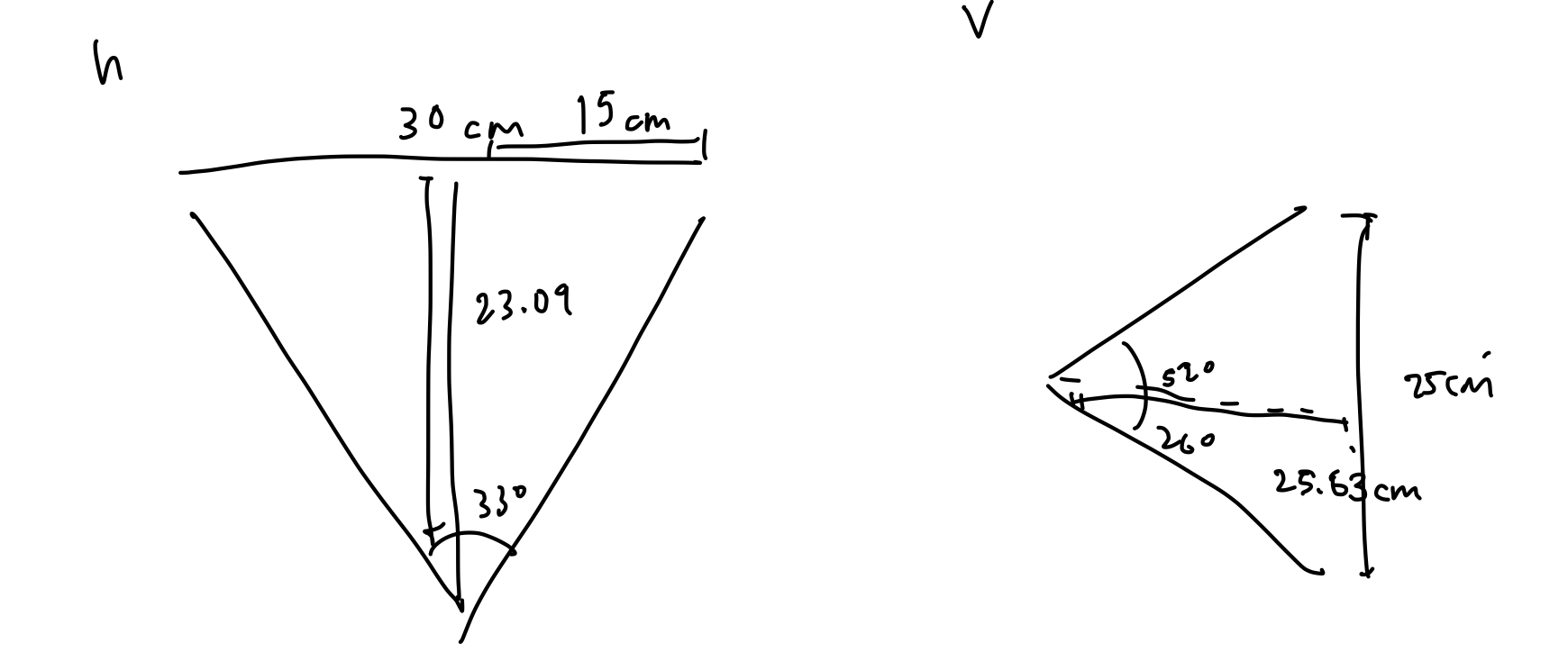
- Input object size is 5cm to 30cm along longest axis
- Weight Limit: using baked clay as example – 0.002kg/cm^3 * (25^3 – 23^3) = 6.91 kg
- average pottery pot thickness is 0.6-0.9cm – round to 1cm
- for plastic the weight limit is 4.3kg
- Our weight limit will be 7kg – round up of the baked clay
- Output Format
- All-in-one Device
- No complex setup needed
- Input object size is 5cm to 30cm along longest axis
-
-
- Time Efficiency
-
-
-
- Less than one minute (time to reset the device to scan a new object)
-
-
- Affordability
-
-
- Costs less than $600
-
Note that the only requirement significantly changed has been that of accuracy. The use case of our device is to be able to capture the 3D geometric data of arbitrary small-scale archeological objects reasonably quickly. We envision groups of gloved explorers with sacks of ancient goodies, wanting to be able to document all of their research in a database of 3D-printable and mixed-reality applicable triangular meshes. To perform scans, they will insert an object into the device, press the scan button, and wait a bit before continuing to the next object. They should not need to be tech experts, nor should they need to already have powerful computers or networks to assist with the computation required. In addition to this, the resulting models should be seen by these archeologists as true to the real thing, so we have adjusted our static accuracy model with a dynamic one, whose accuracy is based on the dimensions of the object to be scanned. We have chosen the 2% accuracy requirement for 90% of points by considering qualitative observational results that may be seen when comparing original objects to their reconstructed meshes. Since archeologists do not have a formal standard by which to assess the correctness of 3D models created for their objects, we took this freedom to use our intuition. 2% of a 5cm object is 1mm, and 2% of a 30cm object is 6mm, both of which seem reasonable to us given what those differences mean for objects of those respective sizes.
We have made an effort this week using these requirements to perform geometric calculations to compute the spatial frequency of our data collection, and in turn the number of points of data that must be collected. From this, we have narrowed down the requirements of our sensor, and began eliminating possibilities. Finally, from those possibilities that remained, our team has chosen a specific sensor to start with: a dual stripe-based depth sensor utilizing a CCD camera. In order to mitigate risk potentially imposed by errors of the sensor, our fallback plan is to add an additional sensor to act as an aid in correcting systematic errors, such as a commercial depth sensor. Since the sensor only costs under $20 + $20 + ~$80 = ~$100 (depending on our choice of camera, it may be more expensive), much less than our project budget, we will be able to add an error-correcting sensor should the need arise for our project.
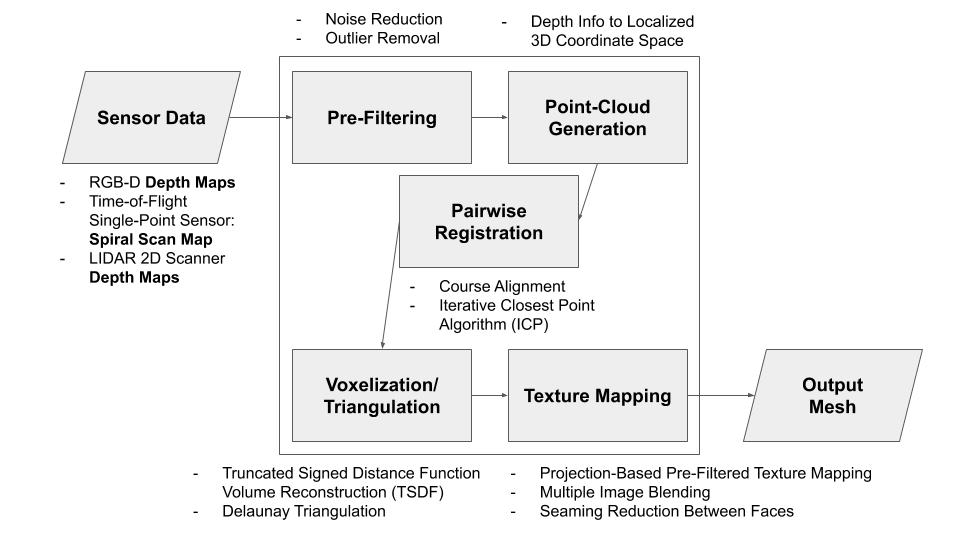
From the behavior of this sensor, which is a laser triangulation depth sensor, we have derived the various other components of our design, including algorithmic specifications, as well as mechanical components required to capture the intended data (whose specifications have been computed during choosing of the sensor). We have chosen a specific computational device for our project, as well as most of the technologies that will be used. All of these details are covered in our respective status updates (Alex for data specifications and sensor elimination, Jeremy for determining algorithms and technology for computation, Chakara for designing and diagramming mechanical components). The board we have chosen is the NVIDIA Jetson Nano Developer Kit ($90), an on-the-edge computing device with a capable, programmable GPGPU. We will utilize our knowledge of parallel computer architectures to be able to implement the algorithmic components on the GPU with the CUDA library, in an effort to surpass our speed requirement. We will implement initial software utilizing software such as Python and Matlab, then transition into our optimized C++ GPU code to meet the timing requirements as the need arises.
Since we are behind in choosing our sensor and thus ordering components for our project, we have been designing all of the other components in parallel. Regardless of the specific sensor chosen, the mechanical components and the algorithmic pipeline would be similar, albeit with slightly different specifications. This parallel work has allowed us to have a completed design at the time we have chosen the specific sensor. However, much of our algorithmic work was based on camera-based approaches, and since we are utilizing a laser depth sensor, we will not need to perform the first few stages of the pipeline we proposed last week. We still need some additional time to flesh out our approach to translate between camera space coordinates and world space coordinates, as well as algorithms for calibration and error correction based on two lasers. Because of this additional time we are extending the algorithm research portion of our Gantt chart.
The main risk we have right now is that since we are designing our own sensors, it is possible that our sensors might not meet our accuracy requirements. Thus, we might need to have a noise reduction algorithm or might potentially have to buy a second sensor to supplement our sensors.
Our design changed a little by using a laser instead of a depth-camera. This changes our pipeline a little but doesn’t affect the mechanical design and overall algorithm.
Below is the link to our updated schedule.
https://docs.google.com/spreadsheets/d/1GGzn30sgRvBdlpad1TIZRK-Fq__RTBgIKN7kDVB3IlI/edit?usp=sharing