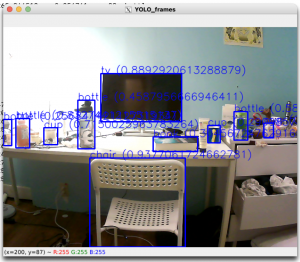
Updated the perspective algorithm, so that it can now 1. crop image, 2. better adjust the perspective by applying an offset(the divide ratio/offset ratio)3. Better boundary check. The current function still needs to manually set the cropping dimensions but it is soon expected to crop automatically. This simply means that the code will crop the image based on the left/right/up/down most objects. The code still needs cleaning up.
The parameters needed for the perspective algorithm also includes the ratio of the length of the upper side of the table and the lower side of the table, or similar; This parameter has currently set manually. This not only adjusts the x coordinates, according to its y coorinates(the top 2 vertex of a trapezoid is stretched to the side), it also adjusts the y coordinates(the farther it is to the back of the image, with the same amount of pixels, it represents more distance in reality).More work could be done so that such ratio could be calculated automatically, such as image segmentation algorithm. However, it does not perfectly address the case where there is no table/the table is at angle to the left/right/ the table is just a smart part of the room.
One thing we can do is just to set the scope of this project, so that such parameter is given when setting up the camera.
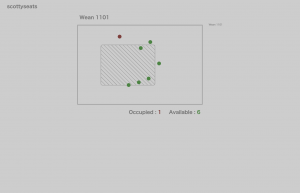
Figure 1: original plan without straightening
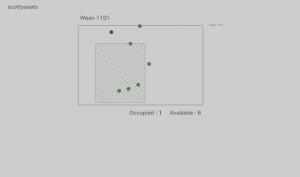
Figure 2: adding perspective adjustment(not effective due to how man white space there is top of the image, thus adding crop is necessary)
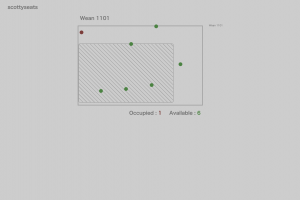
Figure 3: adding cropping(Focus on the seats, the seats are more aligned, but the table is a problem)
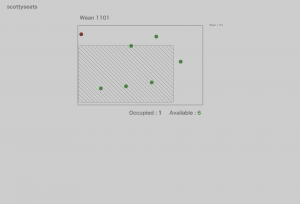
Figure 4: Applying offset
Another thing we realized during the demo is that we are currently only using portrait images to test out the results. While landscape images will work, it will be stretched to make it fit in portrait mode. We could set it so that we only allow for a specific kind of import, or, from the user perspective, the “stretched” result does perfectly reflect where the seats and tables are and all other vital information for them to make the decision. Thus, this is not too big a problem.
I also updated tables during the past week. Tables will not be displayed. But there were 2 problems I encountered:
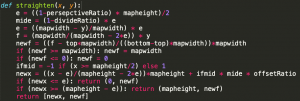
- Tables might look “fat”. This is because yolo is not capable of getting the outline of the table, namely a rectangle instead of a trapezoid. This is solved partly today, by when calculating the length of the table and feeding the left-bottom coordinates and the right-top coordinates into the straightening method algorithm, for the right-top coordinate, we use the x value of itself but the y value of the left-bottom coordinate. I understand that this sounds confusing, but this is to counter the problem that since the right-top point it farther “back”, it will be stretched out more, making it “fat”.
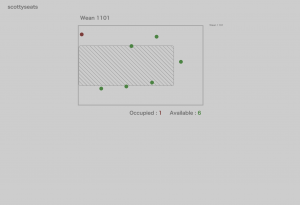
Figure 5: after only using the y value of the bottom vertex of the bounding box of the table(since its a rectangle)
- Seats might appear in the table. As a side effect of the problem above, seats could be in the table. This can be countered by either
- a. shortening the table : This means that the table is decreased in width and height based on the y and x coordinates of the seats that are in the table. This might be dangerous where there actually is a seat in the table, making the table look too thin.
- b. moving out the chairs.: This method is implemented. However, the problem is that we can only choose to move the seat either to the left/right/top/ or bottom. This is currently determined by the distance of the chair to the closest border of the table, so whichever is the closest, it will be moved out in that direction. This distance is determined by the pixel ratio, so a number between 1 and 0, so it does not perfectly reflect the actual distance. For example, if the image is super thin, then the same change in the x coordinate will have a much larger ratio than that in the y coordinate.
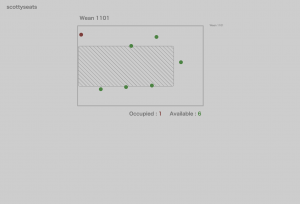
Figure 6: after moving out the seats
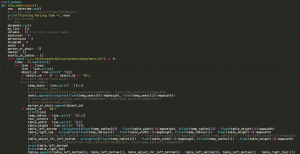
Figure 7: code for parsing the file and store seats and tables information
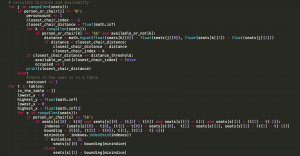
Figure 8: code for calculating the availability of seats and moving seats out of tables
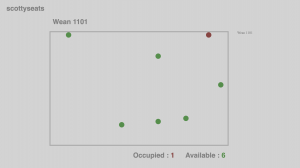
The availability is calculated according to the closest seat to a person. However, there are a few problems I encountered:
- We wanted so that if the person is far away from the seat, the seat won’t be occupied, thus we want a threshold. This is applied at first, but the threshold value varies from different rooms to different rooms, so it is likely impossible to have a fixed value for threshold.
- The distance is inaccurate due to perspective issues
- We can not differentiate between a standing and a sitting person, thus we would mark a standing person as sitting.
Other parts of the views.py file is not included since it is not the core/critical part but only performs systematic functions
Database will be implemented this/next week, so that we can proceed with multiple rooms. The database model:
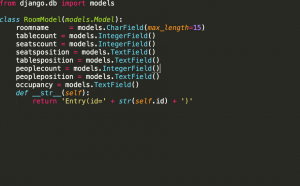
Figure 9: database model
sn.js file
This basically sends request to the backend and runs on load. Related functions are sendRoomRequest.

Figure 10: initialize(the setInterval function might change afterwards)
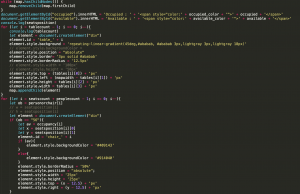
Figure 11: parsing the JSON response, and put a dot on whereever there’s a seat and drawing the table
Other functions include updatePage.
Figure 12: Other files. (html/css)
Plan: after we have data from different rooms, we can easily parse through all the files, store it in database, and when ever the frontend requests it will only be a “GET” method , the backend will only respond will all the information from the database, and then filter/search functions for rooms will be implemented.
This Friday will collect more training dataset and label images will LabelMe.