
This past week the majority of my time was spent cleaning uo our custom dataset, further training the model and tying together the computer vision pipeline as an independently running module.
The past few weeks before I had tried to retrain the YOLO model using transfer learning with various existing image datasets. Looking between ImageNet and OpenImages and running a few test runs on the existing dataset, i found that existing datasets actually didn’t prove to be extremely helpful in training.
Both datasets have many more classes than those we need to train for. While it is possible to run a simple script to relabel the training data only for our target classes, the image sets themselves are also too varied to help with training for our specific use cases. As the models are already pertained, training on a custom dataset for our use case is what will help with further increasing accuracy and the confidence level of the system’s detections.
One other thing that came of note was that YOLO was initially pertained with 80 classes instead of our target 3, the change in the output dimensions is also something extra training will need to count for. One consideration was to maybe continue training with the 80 class scheme and to add an extra output layer to only consider the results of the target three classes. However, I also noted that this introduced more overhead in creating the custom dataset – as instances of all 80 classes will need to be labeled for training. So I determined it was best to use transfer learning with only our custom dataset with just the 3 classes.
After collecting the data as a group, I went through and labeled the data for training purposes using roboflow – a cv platform with functionality to label data. Our initial dataset was only around ~40 images, so as per TA suggestion – I looked into Data Augmentation to introduce noise, contrast change (etc) to artificially produce more data. One issue that came up was looking into how the bounding box detection txt files in the training could be augmented as well. I found a Github codebase https://github.com/Paperspace/DataAugmentationForObjectDetection
with functionality to augment the images and the txt detections. Writing a script to augment our data, I used the codebases augmentation features to artificially increase the dataset to 264 images.
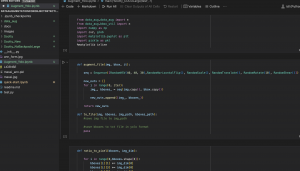
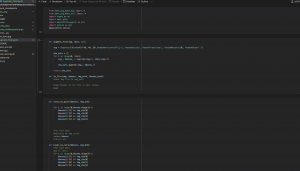
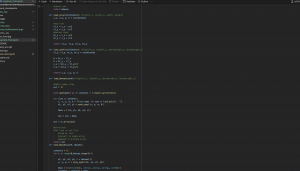
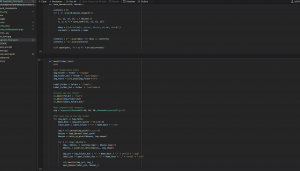
For the training itself, I noted that he YOLO architecture has a 10-layer base a s backbone for feature detection and an additional 13-layer head for object detection and classification (in the same step). So for training, I tested freezing just the backbone and also leaving the last 1/2/3 layers unfrozen in training. Finding that training largely stalled at a precision (portion of detections that were true positives) of about 0.5 on most rounds.

This past week specifically, I committed this by removing our extraneous backpack class to try to we had initially put in to account for extra cases of people temporarily leaving a room (a backpack would then be used to indicate that the seat was occupied). The backpacks were easily conflated with some of the chairs and we were choosing to let go of this extra case in rescoping – so I removed the class. One other change in the dataset was limiting the data augmentation to in place changes (removing any changes that messed with scale/shear/tranlating the image data). With that I removed the backpack class and ran the dat augmentation script again to have the 264 training samples.
Training from there, I was able to achieve >0.90 precision with training just the backbone. This was all that I had worked on until Wednesday specifically, From there, I was mainly writing code to tie the CV module components into standalone module that could run on its own. This took about another 3-4 hours to write out and debug fully.