This week, which was the last week of classes, we had a final presentation and presented what we have done during the semester and our final plans before the final demo. We also worked on the final poster and final video for next week’s deliverables.
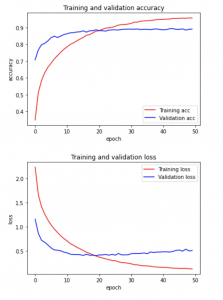
For the item recognition part, last week I decided to have as many epochs (50 epochs) to train. However, training as many epochs to train was a bad idea because the model started to get overfit. In other words, the model learns the details of the outliers and the noise in the training dataset, therefore resulting in lower classification accuracy. I went back with the range of 15-22 epochs, as that was the range of the epochs where the validation accuracy started to converge. After the test, I was able to achieve the increased accuracy of 88.08% with 18 epochs.
I also have tested the model with the images of Aaron’s student items because for the final demo, Aaron is the one who will be physically demonstrating the overall system, including the item registration. The most noticeable result was that among 21 student item labels, it was able to classify the water bottle with 100.0% accuracy. We can also see that the notebook gets correctly classified.
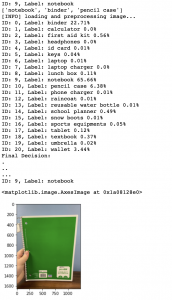

I also have tested the picture of Aaron’s pencil case with his hand taken and without his hand taken, which is a possibility when a user takes a photo when registering an item. The picture with the hand was correctly identified as an image to be a pencil case, but the picture without the hand was incorrectly labeled as a wallet. But, identifying the pencil case as a wallet is fine because both items are “pouch-like objects” which makes sense to classify a pencil case as a wallet and vice versa. To take account of this issue (which also applies to rectangular objects like a notebook, laptop, etc), we have decided previously to show the top 3 classification results, and this result is shown at the top of the image as a Python list. As we see, the result has [‘wallet’, ‘sports equipment’, ‘pencil case’], which also contains the correct result, ‘pencil case’. Thus, even though the image was incorrectly identified (if we only consider the top 1 result), the user can benefit from simply choosing from the top 3 classification results.


Although I have increased the accuracy and made sure that my model works with Aaron’s student item images, my progress on integrating this item recognition part to the web application is slightly behind because of the Tensorflow and Keras modules that throw an error to the deployment of the web application. Thus, to have enough time to integrate and test the deployed web application, I am more leaning towards the backup plan, which is to train the model in the local machine (of a team member doing the final demo) and have the model to communicate with the web application locally. To do so, I am working extensively with Aaron, who is responsible for the deployment, and the web application, and asked Janet to enable the image form feature, where the user can input the image for the item recognition.
For next week, I plan to integrate this model into a web application. Then, we will test the deployed web application and see how it is working with the overall system. Finally, our group will prepare for the final demo and work on the final report.