This week I mainly worked on the network driver and microphone board hardware.
Last week, there was a problem that emerged with the network driver dropping up to 30% of the packets being transmitted from the FPGA, I spent most of this week working on resolving that. The library being used previously was the “hypermedia.net” java library, which works well for low-speed data, but does not buffer packets well, and this was causing most of the drops. By switching to linux and using the regular C network library, this problem was eliminated, though it required rewriting the packet processing and logging code in C.
The next problem was moving this data to a higher-level language like java, python, or matlab to handle the graphics processing. Initially, started looking into ways to give both programs access to the same memory, but this was complicated, not very portable, and difficult to get working. Instead, I ended up deciding on using linux pipes/fifos, as they use regular file I/O, which c and java of course support very well. One small problem that emerged with this had to do with the size of the fifo, which is only 64kB. The java program had some problems with latency relative to the C program, so the FIFO was getting filled, and it was dropping readings. To get around this, I modified the C program to queue up 50,000 readings at once, and put them into a single call to fprintf, and the java program reads in a similar way before processing any of the readings. In this way, the overall throughput is improved, by having just 20 large, unbroken transfers per second, rather than several thousand smaller ones. This does introduce some latency, though only 1/20th of a second which is easily tolerable, and takes more memory, but only a few megabytes.
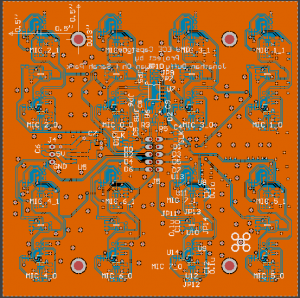
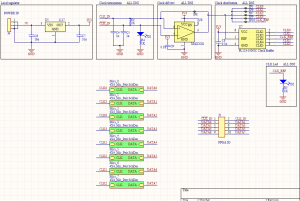
Progress on the hardware has mainly been in figuring out the process for manufacturing all the microphone boards. There were initially some problems with the reflow oven blowing microphones off the board while the solder was still molten. The fan used to circulate air to cool the chamber after it has reached its peak temperature has no speed control, and is strong enough in some areas to blow around the relatively large and light microphones. So far, I have gotten the first few test microphones to work by reflowing them by hand with hot air, which worked but took a significant amount of work per microphone, so it may not be a viable solution for the whole array. I have started working on adding speed control and/or flow straighteners to the reflow oven fan as well, though I suspect I’ll be in for a long day or two of soldering.
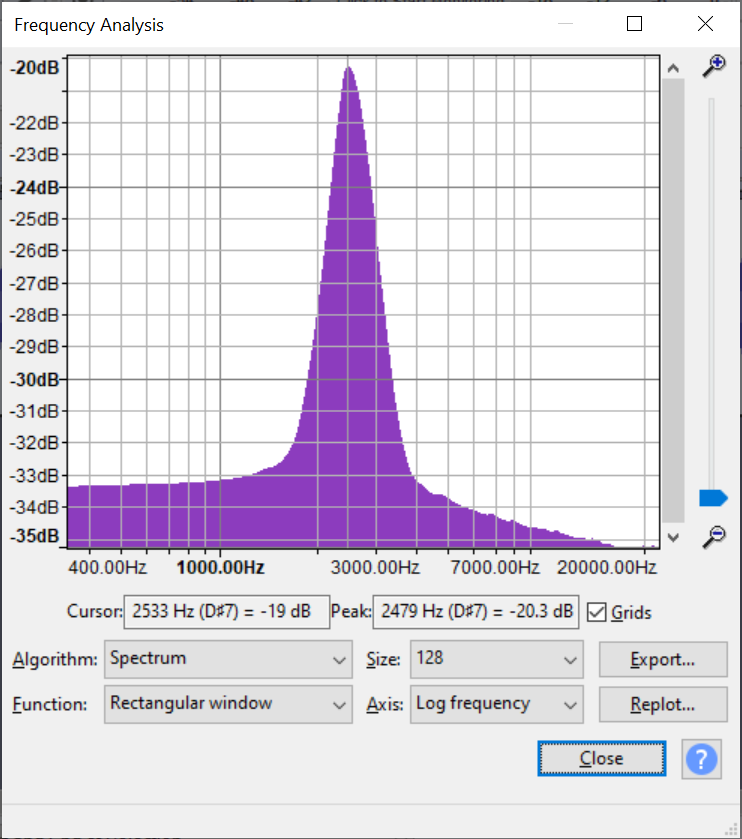
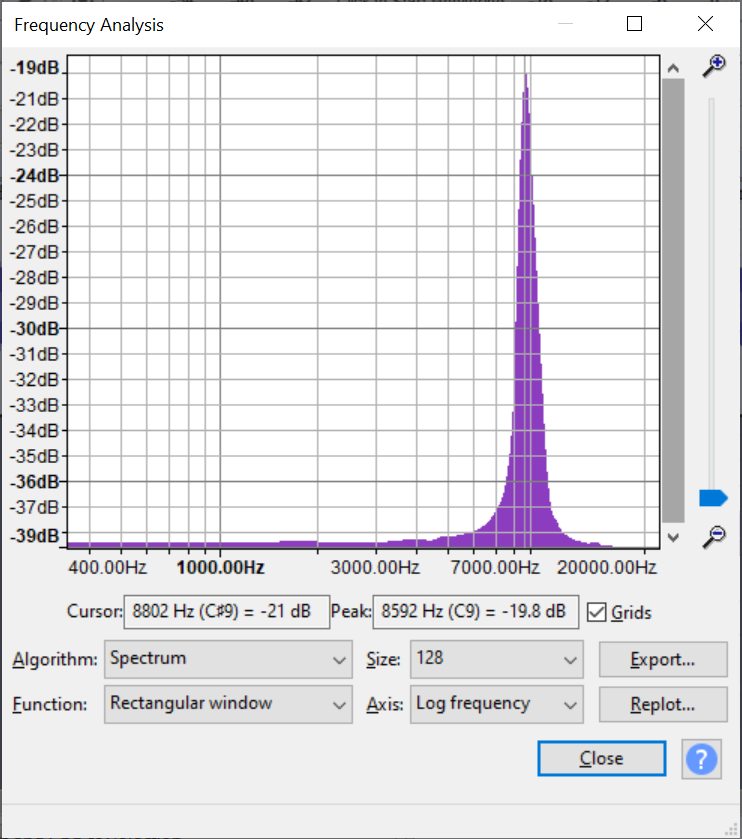
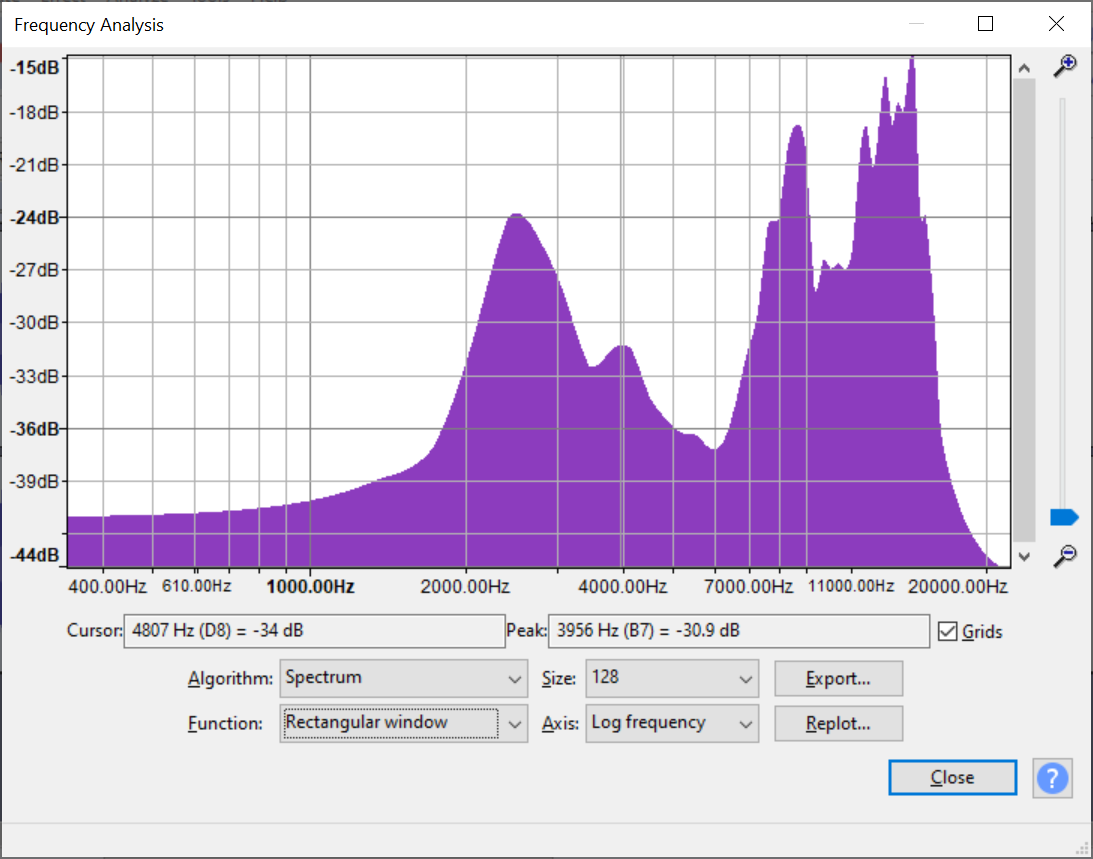
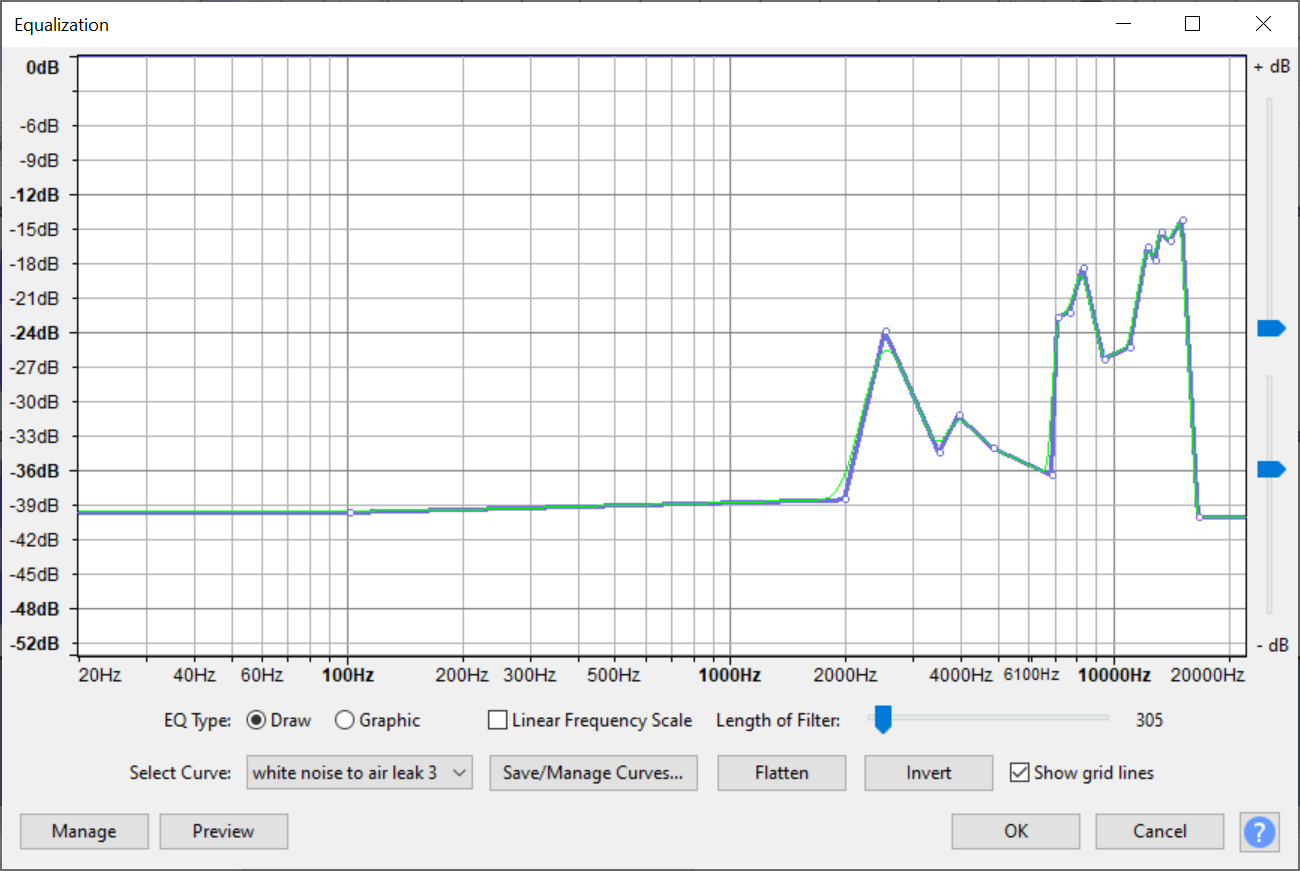
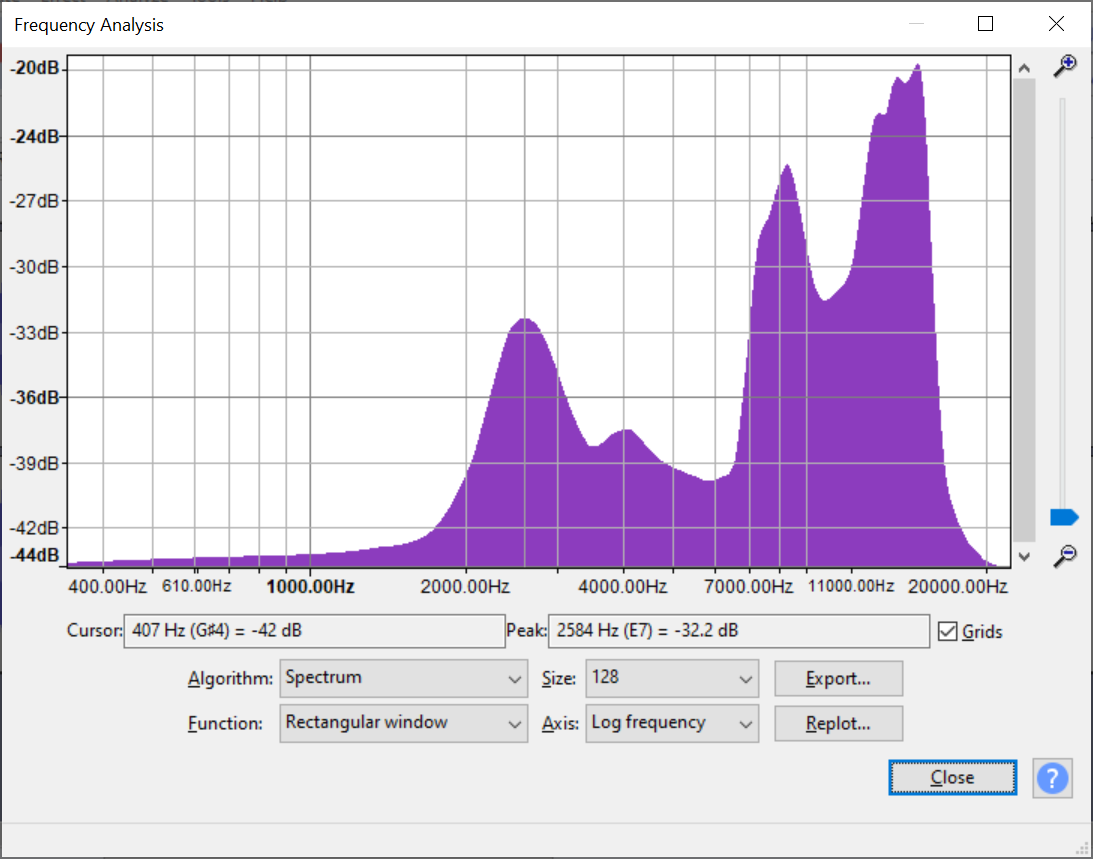
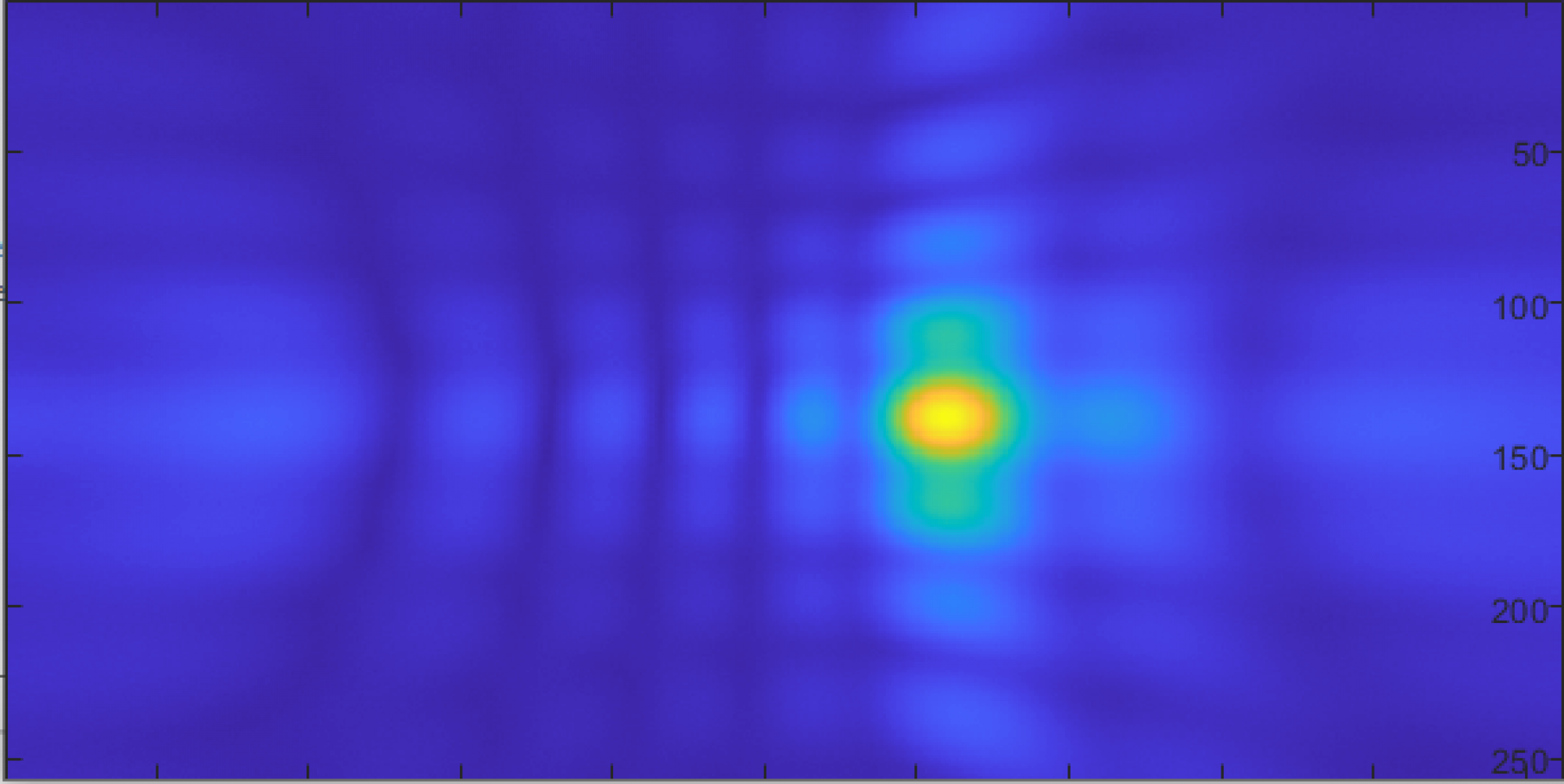
With the working test board, I was able to use the real-time visualizer to do some basic direction finding for a couple of signals, which were extremely promising:
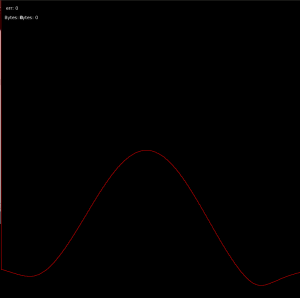
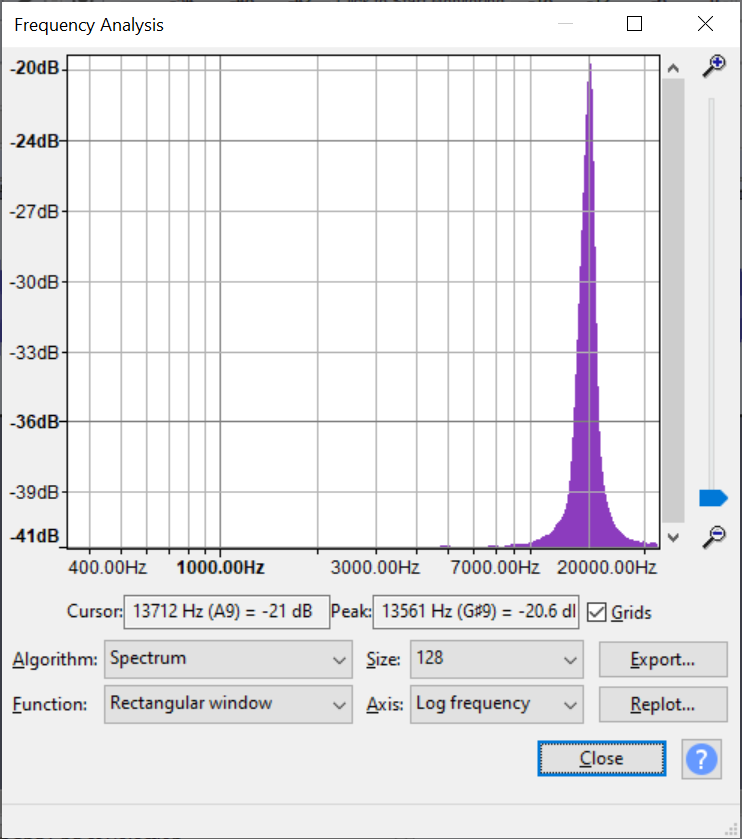
5KHz, high resolution, centered in front of the array (plot is amplitude vs direction)
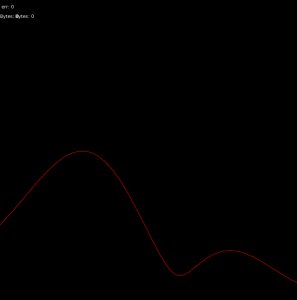
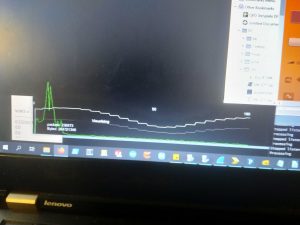
5KHz, high resolution, off-center (about 45 degrees)
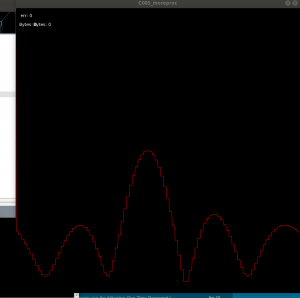
Low resolution, 10KHz centered in front of the array
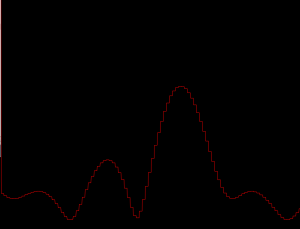
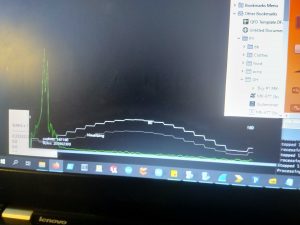
10KHz, low resolution, about 15 degrees off center.
Next week I mainly plan to focus on the hardware, mainly populating all of the microphones and making the wiring to the FPGA.