I meet with Oscar today (As planned in previous status report) and finish the testing of radio+gyro. Here is a Demo Video: Gyro+Radio
Thanks!

Team D1: The Emperor’s New Instrument
Carnegie Mellon ECE Capstone, Spring 2023: Oscar Chen, Yuqi Gong, Karen Song
I meet with Oscar today (As planned in previous status report) and finish the testing of radio+gyro. Here is a Demo Video: Gyro+Radio
Thanks!
I finished the code for radio transmitter and tested it this week.
I am behind schedule. To make up for the progress, I will meet with Oscar tomorrow and fix the radio circuits.
I am hoping to test the radio transmitters with gyroscopes. I will also build the glove circuit next week. (might be able to finish it by tomorrow.)
This week I changed the color detection system to only detect one color at a time to avoid the chaos caused by different lighting levels (especially for green and yellow in dimmer light settings). I also added a classification section that tells the system which quadrant the majority of the colored box is in, so that the synthesizer can produce music accordingly. I also worked with my team on the final presentation ppt.
My progress is behind because I need to update the UI for gesture selection. I did not think it was needed earlier, but then my friend who tested this told me it is hard to read.
Integrated product with other sections (hardware/synthesizer)
The most significant risk at this moment is the radio circuits. According to Yuqi, they work when they are powered by Arduino Unos while connected to the laptop. However, it is not working when I tried to power it using the Arduino Nanos. Yuqi and Oscar will be testing the radio chips with power supplies and power regulators+battery tomorrow. There are two contingency plans. First, we might end up putting Arduino Unos on the gloves to power the chips. Second, we could also buy several power regulator chips and power the radio chips directly.
There was no change to our design, but we might change the way we power our radio chips. This might mean we would either buy extra Arduino Unos or power regulator chips in the future.
The schedule has not changed.
The radio chips are now working. Two transmitters can successfully send one integer each to the receiver. However, the transmitters are all powered by Arduino Unos, which are in turn powered by the laptop.
I was trying to integrate the radio chips with my synthesizer last week. However, I could not get them to work. I have checked that they are neither faulty nor my Arduino Nano. Also, since they worked when Yuqi tested them with Arduino Uno and bypass capacitors, I think the problem lies with the Arduino Nano’s current draw limit. I think the radio chip might need to draw current directly from the batteries, instead of from the Nano.
Update (Sunday, 4/23)
After some debugging, the radio chips are working and they can be powered directly by the Nanos. Here’s a demo video. Although in the video, the Nanos are powered by USB cables, we’ve also verified that they can be powered by two 3.7 LiPO batteries in series. Since the radio chip now works when using shorter wires to connect them and the Nanos, I think that it was the long wires and the breadboard that I previously used that caused too much noise.
I am behind schedule. I thought I could debug and integrate the radio circuits with my synthesizer this week. To make up for the progress, I will meet with Yuqi tomorrow and fix the radio circuits.
I hope to debug and integrate the radio circuits and build one glove next week.
I finished the radio transmitter code. The receiver can receive data from other transmitters. I will post a video later(on Sunday).
It is on schedule. I will work with the team and start integration.
The most significant risk at this moment is our integrated system speed not meeting our time metric requirements. The latency between gesture input and sound output is relatively high, and there is a clear lag that can be felt by users. Currently we are changing to a color-based hand tracking system to reduce the lag of the hand tracking part, and wavetable synthesis to reduce the lag of the synthesizer. Because we are essentially using convolution and a filter to track colors in a video frame, we can lower the resolution of the image and/or search patches of image to speed up the process.
Instead of using a hand tracking model via mediapipe, we end up reverting back to the initial design where we use color to locate the hand. We reduced the number of colored targets from 3 to 1 because it is easier for classification and the user can figure out what sound they are producing earlier. We also bought a webcam so that we don’t have to tune our color filters based on individual laptop webcam. Besides the financial cost, there were no additional costs as the webcam has already been integrated into our system (both on Windows and macOS)..
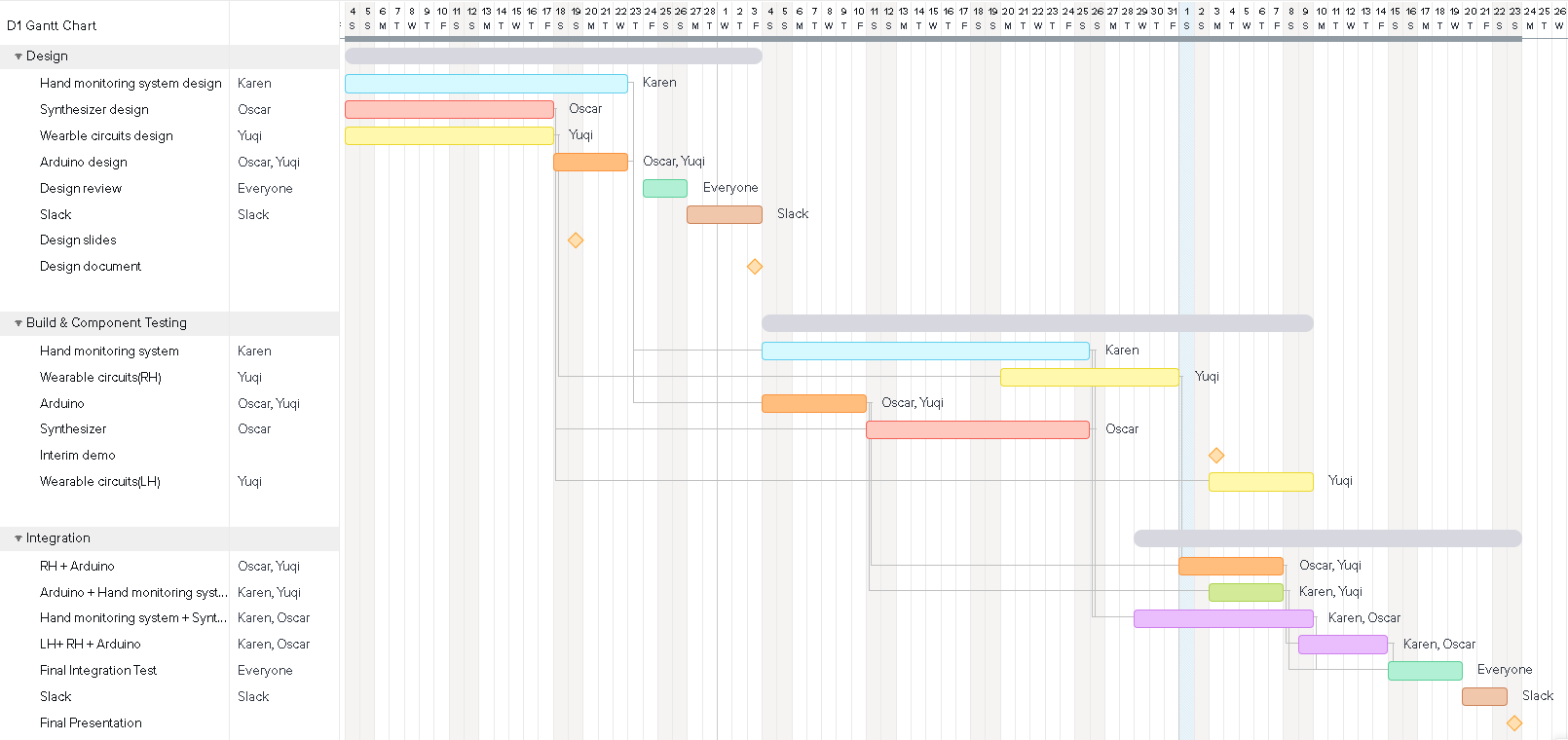
The schedule is the same as the new gantt chart from last week.
Now we have a basic system that allows the user to produce sound by moving their hands across the screen. The system will track the user’s middle finger through color differences (users will wear a colored finger cot) and produce the note corresponding to the finger location. So far the system supports 8 different notes (8 different quadrants on the screen). Compared to last week, this system now supports sampling arbitrary instrument sounds and dual channel audio.
I rewrote the synthesis section of my synthesizer. Before it uses additive synthesis (adding sine waves of different frequencies). Now it uses wavetable synthesis (sampling an arbitrary periodical wavetable). I also added dual-channel support for my synthesizer. With wavetable synthesis, I only need to perform two look-ups in the wavetable and linear interpolation to generate a sample in the audio buffer. Previously I have to add results of multiple sine functions just to generate a sample. Here’s a demo video.
In short, compared to additive synthesis, wavetable synthesis is much faster and can mimic an arbitrary instrument more easily.
I am a little behind schedule. This week, Karen and I decided to use color tracking instead of hand tracking to reduce the lag of our system, so we are behind on our integration schedule. However, I will write a preliminary color-tracking program and integrate it with my synthesizer tomorrow as a preparation for the actual integration later.
I am still hoping to integrate the radio transmission part into our system.
We ran a basic latency test after we merged our synthesizer and hand tracking program. Because the lag was unbearable, we decided to switch to color tracking and wavetable synthesis. For next week, I will be testing the latency of the new synthesizer. Using a performance analysis tool, I found that the old synthesizer takes about 8ms to fill up the audio buffer and write it to the speaker. Next week, I will make sure that the new synthesizer has a latency under 3ms, which gives the color tracking system about 10-3=7ms to process each video frame.
This week I worked on switching from a hand tracking model (tracking using mediapipe) to a color tracking model because mediapipe is relatively slow since it needs to keep track of many points on the hand, while we only need to know where the hand is. Instead, we used colorful tapes and finger cots to keep track of the user’s middle finger position and identify where it is. I worked mainly on adjusting the RGB value identified for each color (so far the system should support Red, green, yellow, blue, and purple). In the end, we probably won’t need that many colors, but this is just for testing purposes (and in the extended case where the user has specific colored clothes that will require a different color finger to be tracked)
I think my progress is still a little behind because changing from hand tracking to color tracking is not part of our intended schedule. However this does kind of solve the problem of time delay, so it is sort of progress speed up in a different place. Next week because of carnival there will be fewer classes so more time for work
Next week I will try to get the color recording fully integrated with the synthesizer (with note area classification) and continue to work on the gesture recognition section
Currently tests that I am currently running/have finished include color detection accuracy(using different color objects under different lighting settings to see if the system can still find the assigned color), color detection speed (time elapse between color input (middle finger locating) and sound output based on quadrant. Tests will be conducted in the following week include battery testing and gesture recognition accuracy, which are based on unfinished components.
Team Report for 4/1
The most significant risk at this moment is our integrated system speed not meeting our time metric requirements. The latency between gesture input and sound output is relatively high, and there is a clear lag that can be felt by users. Currently, we are thinking about using threads and other parallel process methods to reduce the latency created by processing the actual hand tracking command and the write audio buffer function, which contributes to most of the time delay. We are also possibly looking at different tracking models that are faster.
There were no changes to the existing design of the system. All issues so far seem resolvable using the current approach and design
The updated schedule is shown below in the new Gantt chart.
Now we have a basic system that allows the user to produce sound by moving their hands across the screen. So far the system supports 8 different notes (8 different quadrants on the screen). Here’s a demo video.