
As stated in the team status report, nothing much was done this week outside of the poster and the video. For me specifically, I just haven’t had the time to do any additional optimizations on the CV code. All of my work/finals except for this capstone should be complete as of May 3rd, so I expect that I will resume working on the capstone then, so we can have some better test results for the final paper.
Keaton’s status report 4/23
So, this week, I spent the majority of my time finalizing the last for secondary checks for the CV code, and actually did the testing. I started the actual testing itself far too late. I had hoped to finish by today, but even with Jay’s assistance, we were unable to get all of the taken/identified before the end of today.
There was a lot of just manually iterating, testing and retesting suitable HSV color bounds, which took more time than I expected. Also, I found that the dimensions of our image post localization generally were not very reliable. The SSIM method I was using for localization tends to pretty regularly overestimate the bounds, so it’s difficult to . The overinclusion of the background also had a cascading effect on the color tests, since it was harder to tell how much of an item was a particular color when we don’t know how much of the image is the background. As such, a lot of the secondary checks ended up being a lot less effective than I had hoped. I think we might possibly be able to mitigate this with a second localization pass using SIFT, but I’m not sure if it’s feasible at this point.
There’s not much to say about the testing, I just vastly underestimated the amount of time it would take. It’s not difficult to do, it’s just that our testing plan expects us to take >200 images manually, which takes a large amount of time. Preliminary results based on what we have done are mixed. We are well within the amount of time needed, and we get enough correct positives. However, we also misidentify objects (ID object A as object B) far more commonly then we fail to identify objects (ID object A as an unknown object). This is unfortunately exactly the opposite of what we wanted to occur.
Next week, and probably for all of the following weeks until the final live demo/paper, I will be working on trying to get the results such that we can meet our use case. I expect this to be fully possible given where we’re at, it’s literally the only thing left, and I can think of several possible secondary checks that I didn’t get to implement on the first p
Keaton’s Status Report 4/16
This week, I mostly worked on doing integration, specifically handling a fair number of edge cases with regards to unregistered items. This consisted mostly of work in the Django code, and a few minor updates to the CV code. Both Harry and Jay helped me quite a bit as I didn’t have much experience with Django prior.
The CV code previously just gave it’s best guess out of the approved iconic image classes, or none if it wasn’t sure. The CV code was changed to accept a set of items in the current inventory. This is used in the event that an item was removed, so we don’t have to check every possibility, which should help with accuracy. It also deals with the edge case where the cv code says that an item was removed, that it didn’t say was in the cabinet in the first place. The CV code was also modified to accept arbitrary sets of additional Iconic images, to support user item registration. Both of these changes were relatively minor, and mostly just involved filtering/adding to the set of iconic image checked against.
The majority of the code work was done in Django, dealing with user registered items. Essentially, we needed to be able to be able to add unidentified items to the cabinets, and later change their category when the user identified them. We also needed to be able to handle them, in the case that the user decided to place the items and removed them, all without manually identifying them. Long story short this was resolved by creating a Iconic Image model item, with an optional associated item field, that was assigned a UNKNOWN category be default. Essentially, we then treat it as an a regular iconic image, until the user manually identifies it, at which point, we can propagate the identified category to the associated item object. We can also easily generate the prompts the user by filtering iconic models by category/created user. This handles most of the edge cases, and doesn’t have a huge drawback unless the user has huge amounts of unregistered items in their cabinets concurrently, which is unlikely. We still need to do some UI/CSS work here (the alert/request to identify items needs to be placed in a few different places and made much more apparent), but we have the needed functionality. There was also some minor technical debt that I had to fix regards to categories (IE we were making every item have a unique category. instead of re-using them).
Overall, for not knowing Django very well before this week, I’d say I did a pretty good job. Again, I obviously had a large amount of help from Harry and Jay, but I think I learned fairly quickly and got a good amount done. For the next week, I plan to almost exclusively work on the CV component, and try and get it within our needed criteria, and get the testing done so we have it for the slides.
Keaton’s status report 4/2
On Friday, I discovered that my hardware wasn’t working. Taken from my post to general chat general chat:
I unplugged the ribbon from the camera module, just to see if I could, for purposes of potentially using a 15 pin CSI to 21 pin CSI-2 ribbon. When doing this, I accidentally reinserted the ribbon upside down. After realizing my mistake, I fixed it, but it no longer worked. I assumed at this point that the camera module was bricked, and used our spare, which also didn’t work. At this point, I assumed that I had bricked the CSI port, so we got another RPI from Quin (ty so much Quin). However, the new RPI still didn’t work with either camera module.
There was a little bit of floundering, but (as of 3PM on Apr 2nd) I’ve since gotten a new RPI/camera combination that does work, and will be using this for the demo. I don’t think the slightly different fisheye lens will have a significant impact, but I do have some concerns regarding the pixel diff. As I’m unable to securely attach the camera to a single unmoving position, we do get some fairly large areas of change just due to noise:


Overall, I’m pretty sure everything will be alright for the demo, but I definitely need to invest some time today/Monday to be sure . While I was waiting on backup hardware, I did some minor stuff, such as updating the gantt chart, and I did some bootstrap CSS on a few of the Django HTML templates. Overall, this was a pretty crap week in terms of progress, which comes on the heels of another pretty crap week. I definitely expect to be putting in some time during carnival weekend to fix these issues, and catch up on my work.
Keaton’s Status Report (3/26)
I got very little done this week, outside of some minor admin stuff, like writing a rough draft for the ethics section of the final report. I apologize for this, and expect to make up for it this week.
Keaton’s status report for 3/19
Mar 19th:
New, fully realized beautiful setup. Thank god for heavy weight bearing adhesive velcro straps and sticky putty.

Pixel diff is working, at least for all the situations I used it in excluding one (crushed tomatoes) (may still need fixed light if we’re doing it in different lighting conditions). No major issues to report there.
Tested two situations, one where the item was directly under the camera, and one where it was off to the side with anti-distortion of the image.


Overall results were fine, but definitely worse than the photos taken with the I-phone camera. also, the side shot was definitely worse then the center shots for most items Here is the confusion matrix based on the number of matches we saw for each situation. (the number shown is the number of (matches)/(number of matches for the best match for that particular query image))
Sideshot:
| Applesauce | Milk | CrushedTomatos | Shredded cheese | Spaghetti | BakingPowder | Yogurt | Beans | Cereal | Crackers | |
| Applesauce | 0 | 0 | 0.40678 | 0 | 0.147959 | 0.820513 | 0.869565 | 0.083333 | 0.7 | 0 |
| Milk | 0.462236 | 0.68254 | 0.20339 | 0.093023 | 0 | 0.846154 | 0.942029 | 0.375 | 0.766667 | 0.113861 |
| CrushedTomatos | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Shredded cheese | 0.954683 | 0.936508 | 0.559322 | 0.937984 | 0.908163 | 0.974359 | 0.956522 | 0.166667 | 0.772222 | 0.935644 |
| Spaghetti | 0.960725 | 0.952381 | 0.254237 | 0.984496 | 0.80102 | 0.974359 | 0.913043 | 0.458333 | 0.844444 | 0.970297 |
| BakingPowder | 0.845921 | 0.809524 | 0.694915 | 0.728682 | 0.739796 | 0 | 0.884058 | 0.125 | 0.811111 | 0.79703 |
| Yogurt | 0.867069 | 0.857143 | 0 | 0.806202 | 0.816327 | 0.871795 | 0 | 0 | 0.75 | 0.866337 |
| Beans | 0.975831 | 0.968254 | 0.644068 | 0.984496 | 0.97449 | 0.948718 | 0.971014 | 0.125 | 0.811111 | 0.980198 |
| Cereal | 0.975831 | 0.968254 | 0.644068 | 0.968992 | 0.969388 | 0.871795 | 0.898551 | 0.208333 | 0 | 0.985149 |
| Crackers | 0.97281 | 0.936508 | 0.237288 | 0.945736 | 0.954082 | 0.948718 | 0.913043 | 0.208333 | 0.783333 | 0.712871 |
Center Shot:
| Applesauce | Milk | CrushedTomatos | Shredded cheese | Spaghetti | BakingPowder | Yogurt | Beans | Cereal | Crackers | |
| Applesauce | 0.151487 | 0.139073 | 0.0261 | 0.028105 | 0.082428 | 0.001076 | 0.002422 | 0.004927 | 0.041316 | 0.295754 |
| Milk | 0.081465 | 0.04415 | 0.035048 | 0.02549 | 0.096742 | 0.000923 | 0.001076 | 0.003359 | 0.032135 | 0.262079 |
| CrushedTomatos | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Shredded cheese | 0.006865 | 0.00883 | 0.019389 | 0.001743 | 0.008885 | 0.000154 | 0.000807 | 0.004479 | 0.03137 | 0.019034 |
| Spaghetti | 0.00595 | 0.006623 | 0.032811 | 0.000436 | 0.01925 | 0.000154 | 0.001615 | 0.002912 | 0.021423 | 0.008785 |
| BakingPowder | 0.023341 | 0.02649 | 0.013423 | 0.007625 | 0.025173 | 0.005996 | 0.002153 | 0.004703 | 0.026014 | 0.060029 |
| Yogurt | 0.020137 | 0.019868 | 0.043997 | 0.005447 | 0.017769 | 0.000769 | 0.018568 | 0.005375 | 0.03443 | 0.039531 |
| Beans | 0.003661 | 0.004415 | 0.01566 | 0.000436 | 0.002468 | 0.000308 | 0.000538 | 0.004703 | 0.026014 | 0.005857 |
| Cereal | 0.003661 | 0.004415 | 0.01566 | 0.000871 | 0.002962 | 0.000769 | 0.001884 | 0.004255 | 0.13772 | 0.004392 |
| Crackers | 0.004119 | 0.00883 | 0.033557 | 0.001525 | 0.004442 | 0.000308 | 0.001615 | 0.004255 | 0.029839 | 0.084919 |
A few standout items that were confused with each other: Applesauce just generally had a larger amount of descriptors, so there were more matches. I think there was also an issue with crushed tomatoes where the pixel diff failed. Overall, I don’t think there’s anything that can’t be handled on a case by case basis. However, I’m somewhat concerned that our ability to recognize when we have an unsupported object will be more difficult.
Overall, I’m mostly happy with the state of the CV component, it’s at least minimally functional. I will likely move to help working on the other stuff to get the demo working. I may also try adding some checks for the stuff that was confused, if I can find something simple.
Keaton’s Status Report 3/12
During break, I managed to make some progress, but not as much as I ideally should have. I made progress in two area’s, the first being pixel diff localization, and the second being camera setup/image comparison.
Using just subtraction for the pixel diff didn’t really work, due to very minor changes in lighting conditions. To resolve this, I used a slightly more involved method that I got from stack overflow. I calculated the Structural Similarity Index, located contours, and got the bounds from them worked pretty well:

I initially figured that the largest contour region will likely always be the object we are looking for, but this proved to be false (the shadow was bigger both in the example with my hand and the example with the applesauce farther down), so we may need some overhead lighting to prevent that from happening. Overall, I’m pretty happy with the localization code itself, with the correct lighting, it’ll work fine.
The actual setup stuff was a mixed bag. I made a exceptionally high tech setup for the camera apparatus, shown below:

As you can see, it’s the camera module, sticky putty’d to an empty hand sanitizer bottle, with some velcro strips attached. There are equivalently spaced velcro strips on the ceiling of my cabinet, so I can attach/rotate the angle of the camera as needed. This worked fairly well for the camera itself, but I had to manually hold the RPI in place, which led to a bit of shifting/jiggling, which screwed the pixel diff. The RPI belongs to Harry, I didn’t want to attach the velcro strips (which are really hard to remove and leave a lot of sticky gunk behind) without his permission. I also wasn’t certain that the velcro strips would hold the weight of the RPI, and I didn’t want to break something that wasn’t mine. Despite this, I had one decent photo of the applesauce where the pixel diff worked pretty well (omitting some changes in the RPI/background outside of the cabinet, and the shadow)

I manually cropped the image, and did a quick pairwise comparison using only the applesauce image, and the results were REALLY bad. We got at 5 matches (on shredded cheese), out of several hundreds of possible features. So, it seems that we’ll likely need to enforce either facing the products so that the label is directly towards the camera, or we’ll have to move the camera to be on the door, and prevent the user from placing large objects in front of smaller ones.
To summarize, while I made a fair bit of progress, I think that I’m still behind where I probably should be at this point in time. Thankfully, I think that most of the blockers are just some design stuff about how to handle label visibility, the code that was used to do the initial algorithm comparison was fairly easy to extend now that I know what I’m doing.
Keaton’s Status Report 2/19
When I left last week, I was still scrambling to determine what algorithm(s) we would use in order to perform object detection/classification, which I continued into this week. As of the end of this week, we have finalized our algorithm choice (SIFT) and the grocery list which we will be supporting. I think we have a strong plan moving forward into design week, and I feel confident in my ability to actually implement the CV component of this project.
For review, at the start of the week, I failed to find any effective answers to the issues we were facing using SIFT/ORB, those being:
- Label visibility was paramount, as the majority of key points were found on the labeling for the majority of the items we were testing
- Every nutritional label was largely identical to every other nutritional label, which led to a large number of misidentifications (specifically when looking for milk, as the nutrition info was in the iconic image)
As such, I began exploring some alternative methods to doing object classification. I looked into YOLO, as it was mentioned during a previous abstract presentation, and I found a paper that used YOLO on an open source grocery dataset to good effect, so I figured it might work for our purposes. For a proof of concept I found another similar dataset, and converted it to YOLO format (this ended up being most of the work, surprisingly). I then trained the smallest available model for ~10 epochs on the open source dataset just to make sure that I could (you can see the trained model in the cloned YOLOv5 repo, in runs/train). I also set up an account on CVAT, which we could use to split the work while annotating images, which would be needed if we were going to pursue this. However, the process of generating enough data to make it viable was a large amount of work, and it didn’t guarantee our ability to resolve the issues we had already encountered with SIFT/ORB/BRIEF. Thankfully, I waited until after Wednesday before delving further.
On Wednesday, we met with Prof Savvides and Funmbi, and they recommended that we decrease the scope of this project by imposing the following requirements on the user:
- The objects must be stored such that the label is visible to the camera
- The user can only remove/add one item at a time
With the first requirement, the majority of the issues we were facing with SIFT/ORB/BRIEF became a non issue. The second rule is to allow for unsupported object detection/registration of new items via pixel diffing. This is something which we need to implement later, but isn’t a concern as of right now.
I re-did an eye test on various common items in my kitchen (requiring their label was front and center) and I found that the following items seemed to work well with the given restrictions: Milk, Eggs, Yogurt, Cereal, Canned Beans, Pasta, and Ritz crackers. We will be using these moving forward. SIFT also continued to perform the best on the eye test.
Overall, I’m fairly satisfied with both my performance this week, and where we are as a group. I think the scope of the project is no longer anywhere near as daunting, and we should be able to complete it fairly easily within the given timeframe. Major tasks for the next week include finishing the design documentation (this obviously will be split among all of us, but I expect it to still take a fair amount of work), and working with images from the rpi camera which is arriving, to find optimal angle/height for taking photos.
As mentioned in the team post, we also moved everything to a shared github group, CV code can be found at:
Keaton Drebes’s Status Report for Feb 12
My major task for the week was to benchmark the various potential CV algorithms, and determine which to use moving forward. Unfortunately, I failed in this regard. While I was able to benchmark the various algorithms, I was unable to draw any sort of meaningful argument as to which is superior.
My process for doing benchmarking was fairly simple. I manually took a number of photos of the items on our list, with an iphone camera. These will vary slightly from the images which will be taken with the RPI (fisheye lens from a slightly different angle) but should be sufficient for testing purposes. The inside of the fridge I used for an example also has a small amount of visual clutter. I manually created a bounding box for each of the images I took, in order to determine what number of good matches we observe. Since Sift/Fast/Orb all inherent from the same superclass, the algorithm to use could simply be passed as an argument. After creating the code and debugging, I ran into an immediate problem. All the algorithms seemed to have vastly more failure matchings for the less geometrically complicated items then what I was expecting going in. The items with labels also were performed quite poorly when the labels were obscured (which was expected). I made a simple sanity check that highlighted the matches, the results of which I show below:

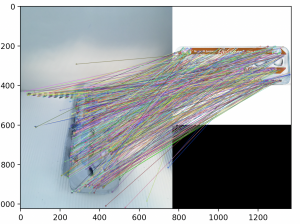
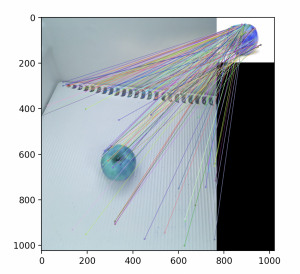

I’ve only shown the results with SIFT, but the results for FAST/ORB were generally as bad if not worse. I expect that the errors are likely due to what I previously had considered “very minor” background clutter, judging by the number of false matches with the ridges in the back. SIFT won for most of the categories, but I can’t feel confident with the results until it’s repeated in an environment with less background noise, and we are able to get something resembling the number of correct matches required for our use case. In the future, I will do an eyeball check before bothering with manually adding bounding boxes. I did a few eyeball checks while using various preprocessing tools, but none had a significant effect as far as I could see. I’m uncertain how to handle the label being obscured/non-visible, as this will likely pose a greater problem going forward.
Ultimately, I think this week was a failure on my part, and has in no way helped our being behind. The issues encountered here must be addressed quickly, as all other aspects of the project are dependent on it. As such, both myself and Harry will be working on it come next week. I hope, by next week, to have actually finished this, and have a solid answer. Concurrent with this, I hope to develop a standardized testing method, so we can more easily fine tune later. I hope to also investigate how best to mitigate the labeling issue, and provide a reasonable fix for this.
Current code/images used can be found at: https://github.com/keatoooon/test_stuff