Progress
I finally received my parts and can access the xavier board via ssh now.
Streaming
I wanted to first try streaming video to the xavier board from my local webcam for the hopes that we can run in live time. I encoded the image into bytes and sent them via websockets between the server and the computer. However, this results in a super slow 2FPS. So, I decided it would be best to use videos to train and test the gesture recognition. RIP live time.
Setting up remote environment
Without streaming, we had to work with videos. I changed the OpenPose scripts (gesture recognition and feature extraction) to use videos instead of the webcam.
To get videos, I wrote a python script to record videos with the webcam and OpenCV, with features like automatic recording after a wait time and stopping recording after a certain length was reached. This was helpful for gathering data later on and I shared the script with the rest of the team.
I built a bash script so I could send videos to the server, execute code remotely, and copy the results back to my local computer. In addition, I set up the webcam in my room. I tested the existing gestures (to me, go home, stop, and teleop commands) in my room and they worked great. It was nice seeing that the teleop gesture data I collected at CMU generalized to both my room and the video recorded in Sean’s room.
Gesture recognition
I cleaned up alot of our gesture recognition logic to make it most understandable, as we were using multiple methods of detection (model and heuristics). Also, running gesture recognition on video showed some errors in the gesture stream output. The gesture stream output should only return a gesture if the gesture is changed. However, there is noise with running OpenPose that return bad results for a frame, causing gesture recognition to think a gesture changed. For example, if an arm is raised for 4 frames, there may be noise on frame 3. So the gesture stream may be [arm raised at frame 1, no gesture at frame 3, arm raised at frame 4]. However, we only want one arm raised output in the action, or else the gesture will trigger on the robot twice. To resolve this, we use a gesture buffer. Commands like “no gesture” or teleop gestures require to be seen for 10 frames (1/3 sec) before they count as a detected gestures. Gestures like left arm raised, right arm raised, and both arms raised are detected immediately, but only if the previous gesture detected was no gesture. This helps remove noise between transitions of gestures and give us the desired output of the gesture output stream.
One vs all (OVR) SVM methods
As mentioned in the post on week 4, I did work earlier to setup both multiclass and OVR SVM methods. I found that they did not make much of a difference between teleop gesture classification (3 classes) but improved the model on testing point data (pointing along 1 horizontal row of the room with 6 classes). I added the ability to run both OVR and multiclass models in gesture recognition. Also, I experimented with the class weights parameter in SVM training to prevent too much of an imbalance of positive and negative data.

Teleop SVM methods beating out heuristics for recognizing straight teleop gesture.
Point
I also wanted to do more work on gesture recognition for detecting pointing in a room. Previously, we wanted predict which bin in a room a user was pointing to, without taking into account the position of the user. However, this is hard to generalize to a different room, so I wanted to explore predicting pointing to a bin relative to the user. So, I collected data pointing to 7 bins to the left, right, and front of the user. On early datasets this method achieved around 0.9 mAP and 0.975 test accuracy, (with test set being randomly sampled from the same video as training data) but it still is iffy on the test videos. I want to have automated evaluation the system on different videos and collect more training data. The system can easily detect if a point is to the left, right, or center (x dimension), but has trouble seeing how in front a user is pointing to (y dimension). This is because the data for how in front you are pointing to is very similar from a front view camera. This could potentially be solved with another side camera.

Early point data, detecting i’m pointing to a bin to the 2 ft right and 2 ft in front of me.
Deliverables next week
I want to continue to gather data for the point problem and work on different models. Additionally, I want to have separate videos to train and test on. I also want to work with the side camera data if it can arrive next week.
I also want to start on the visualization for the point recognition.
Risk management
Most of our risks of the parts not arriving have been resolved, as they arrived this week. Also, being able to work on videos removes our risk for not having enough time to run everything remotely.
The major risks left is not being able to detect the point, but that can potentially be resolved with additional hardware (another camera perspective) and limiting the point problems by the size of the bins we choose.
Schedule
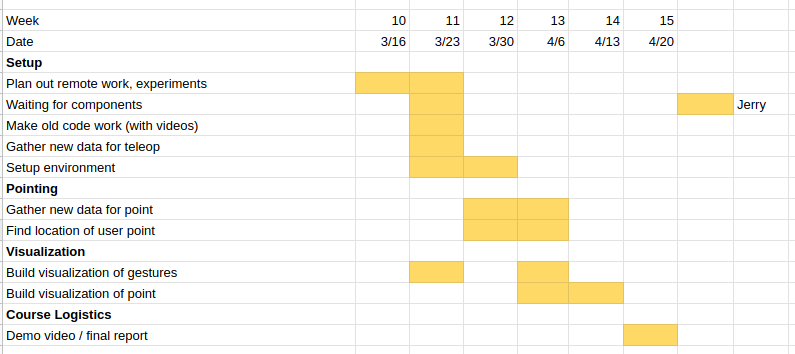
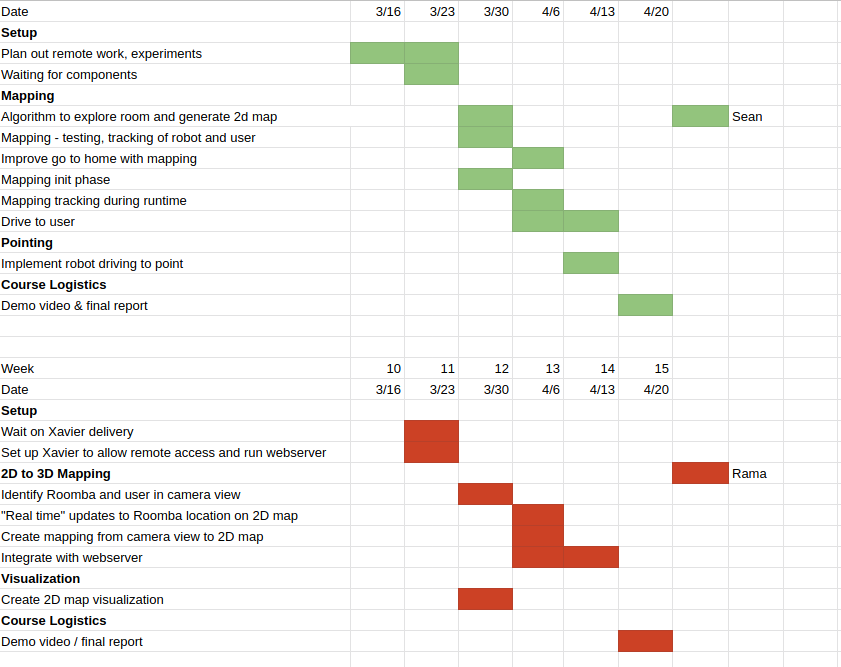
On schedule. Slightly ahead of the previous planned schedule as the parts arrived this week. However, more time needs to be spent on the point. I have attached the updated Gant Chart.