
We are writing our report and making our demo video!
Jerry’s Status Update for 04/25 (Week 11)
Progress
This week, I worked on the final version of the point model. To get the best performance, I included noise into the pointing dataset, used less keypoints to focus on the arms, and added location as a feature for point classification.
The best performing model on the newest dataset had a validation accuracy of 96%.
I also built a point trigger to let users choose where to activate the point in the final application. This allows the point to operate smoothly with the gesture recognition system at ~27 FPS, whereas running the point model on every frame is 28FPS.
We also planned what we needed for our demo video.
Deliverables next week
Next week, we will give our final presentation and put together our video.
Schedule
On schedule.
Jerry’s Status Update for 04/18 (Week 10)
Progress
This week, I kept working on getting the point to work with a 3×5 bin larger room. With the new dataset, the multitask model was getting 0.94 validation x accuracy and 0.95 validation y accuracy, but the results were not smooth when running it on a test video and panning the point around the room.
So, I tried using a regression output rather than a categorical output, such that the model would be able to relate information about how close the bins are instead of treating the bins as independent. This gave a much smoother result, but still has issues in the panning video.
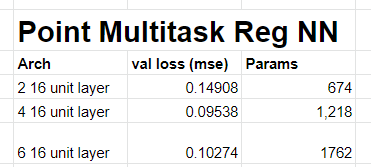
To address the smoothness in the testing videos, I added additional data of moving my arm around while pointing to a bin. This adds noise to the data and lets the model learn that even though I am moving my arm, I am still pointing to a bin. This worked well when I tried it on pointing to one side of the room. I will continue to try this method to cover more parts of the room.
I currently am manually evaluating the test videos, if I have time I will try to add labels to it so I can quantatitively test it.
Deliverables next week
Next week, I will have gotten the point to work on the entire room.
Schedule
On schedule.
Jerry’s Status Update for 04/11 (Week 9)
Progress
This week, I trained a few new models on the new dataset for the point. With evaluating validation accuracy on seperate videos, I found that the SVM method gave around 92% accuracy. So, I also tried a simple categorical neural net that gave around 93% validation accuracy. Additionally, I tried a multitask model that predicted the x and y categories individually. This gave the best results, with 97% validation accuracy for the x axis and 94% on the y axis.
Installing tensorflow on the Xavier board took some time, but I have recorded the installation steps for future reference.
I am also collecting the larger point dataset, with a room larger than just 3×3 bins.
Deliverables next week
Next week, I will apply some SVM tuning suggestions Marios gave us. I am also going to train the models on the larger point dataset. I will also work on a trigger for the dataset.
Schedule
On schedule.
Jerry’s Status Update for 04/04 (Week 8)
Progress
This week, I experimented with more methods to do the point. I wanted to get another webcam, but surge pricing due to the pandemic has caused webcams to go from $17 to $100. So, I am exploring solutions of using my phone or laptop webcam.
With pointing to 8 squares in a room, I was able to achieve 98% test accuracy and 98% validation accuracy with a SVM OVR model trained on 2700 poses. However, there were still error running it on a test video. I believe this is because I calculated the validation metrics from a held out percent of frames from the original video for training. So, I collected separate videos for train and validation. Also, I wanted to collect new data for the point to include pointing with both left and right hands.
The SVMs currently do not relay the fact that bins closer together are more similar, so I hope to try other model architectures like one neural net to predict the x and y coordinate of the bin separately. I could not have done this with the old dataset because there was not enough data.
I also built a visualization for the point to show in the demo.
Deliverables next week
I will train some new models with the dataset that I collected, and hope to get better results for the point on the test videos.
Schedule
On schedule.
Jerry’s Status Update for 03/28 (Week 7)
Progress
I finally received my parts and can access the xavier board via ssh now.
Streaming
I wanted to first try streaming video to the xavier board from my local webcam for the hopes that we can run in live time. I encoded the image into bytes and sent them via websockets between the server and the computer. However, this results in a super slow 2FPS. So, I decided it would be best to use videos to train and test the gesture recognition. RIP live time.
Setting up remote environment
Without streaming, we had to work with videos. I changed the OpenPose scripts (gesture recognition and feature extraction) to use videos instead of the webcam.
To get videos, I wrote a python script to record videos with the webcam and OpenCV, with features like automatic recording after a wait time and stopping recording after a certain length was reached. This was helpful for gathering data later on and I shared the script with the rest of the team.
I built a bash script so I could send videos to the server, execute code remotely, and copy the results back to my local computer. In addition, I set up the webcam in my room. I tested the existing gestures (to me, go home, stop, and teleop commands) in my room and they worked great. It was nice seeing that the teleop gesture data I collected at CMU generalized to both my room and the video recorded in Sean’s room.
Gesture recognition
I cleaned up alot of our gesture recognition logic to make it most understandable, as we were using multiple methods of detection (model and heuristics). Also, running gesture recognition on video showed some errors in the gesture stream output. The gesture stream output should only return a gesture if the gesture is changed. However, there is noise with running OpenPose that return bad results for a frame, causing gesture recognition to think a gesture changed. For example, if an arm is raised for 4 frames, there may be noise on frame 3. So the gesture stream may be [arm raised at frame 1, no gesture at frame 3, arm raised at frame 4]. However, we only want one arm raised output in the action, or else the gesture will trigger on the robot twice. To resolve this, we use a gesture buffer. Commands like “no gesture” or teleop gestures require to be seen for 10 frames (1/3 sec) before they count as a detected gestures. Gestures like left arm raised, right arm raised, and both arms raised are detected immediately, but only if the previous gesture detected was no gesture. This helps remove noise between transitions of gestures and give us the desired output of the gesture output stream.
One vs all (OVR) SVM methods
As mentioned in the post on week 4, I did work earlier to setup both multiclass and OVR SVM methods. I found that they did not make much of a difference between teleop gesture classification (3 classes) but improved the model on testing point data (pointing along 1 horizontal row of the room with 6 classes). I added the ability to run both OVR and multiclass models in gesture recognition. Also, I experimented with the class weights parameter in SVM training to prevent too much of an imbalance of positive and negative data.

Teleop SVM methods beating out heuristics for recognizing straight teleop gesture.
Point
I also wanted to do more work on gesture recognition for detecting pointing in a room. Previously, we wanted predict which bin in a room a user was pointing to, without taking into account the position of the user. However, this is hard to generalize to a different room, so I wanted to explore predicting pointing to a bin relative to the user. So, I collected data pointing to 7 bins to the left, right, and front of the user. On early datasets this method achieved around 0.9 mAP and 0.975 test accuracy, (with test set being randomly sampled from the same video as training data) but it still is iffy on the test videos. I want to have automated evaluation the system on different videos and collect more training data. The system can easily detect if a point is to the left, right, or center (x dimension), but has trouble seeing how in front a user is pointing to (y dimension). This is because the data for how in front you are pointing to is very similar from a front view camera. This could potentially be solved with another side camera.

Early point data, detecting i’m pointing to a bin to the 2 ft right and 2 ft in front of me.
Deliverables next week
I want to continue to gather data for the point problem and work on different models. Additionally, I want to have separate videos to train and test on. I also want to work with the side camera data if it can arrive next week.
I also want to start on the visualization for the point recognition.
Risk management
Most of our risks of the parts not arriving have been resolved, as they arrived this week. Also, being able to work on videos removes our risk for not having enough time to run everything remotely.
The major risks left is not being able to detect the point, but that can potentially be resolved with additional hardware (another camera perspective) and limiting the point problems by the size of the bins we choose.
Schedule
On schedule. Slightly ahead of the previous planned schedule as the parts arrived this week. However, more time needs to be spent on the point. I have attached the updated Gant Chart.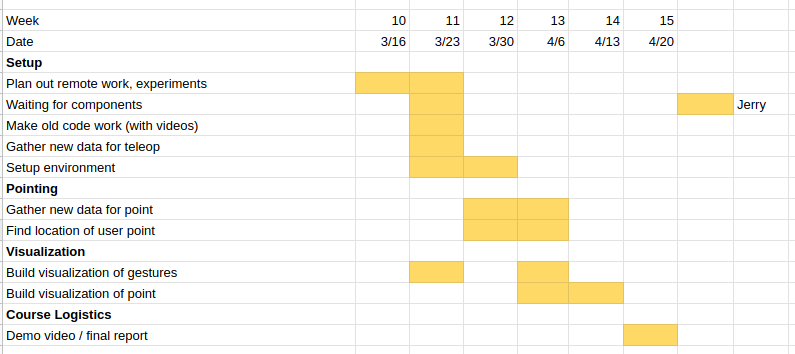
Jerry’s Status Update for 03/21 (Week 5, 6)
Progress
These past two weeks were hectic as we tried to deal with transitioning our project to work remotely. Alot of time was spent to bouncing around different ideas for how we could change our project and doing research to see what of the methods were visible. We originally wanted to move the project to simulation, so we were looking into methods like Webots and Gazebo. After further discussion with Marios, we decided to still have the robot run locally at Sean’s place and have Rama and my parts run remotely, integrated with video editing.
On the technical side, I’m looking into streaming my webcam footage to the xavier board to process the gestures. Even though latency is not as much of a concern, I want to make sure that is is fast enough for development. I am also working on evaluating the code to see how much we can reuse with the new project.
Deliverables next week
Next week, I want to make sure all the existing gestures can be recognizing through the home environment. (Everything except for the point) And I want to start gathering data again for the gestures and the point with my new home environment. I don’t know if I will receive the webcam and hardware from Quinn, but I’ll try to set that up if it arrives.
Schedule
Behind schedule, but we have readjusted it for remote work.
Jerry’s Status Update for 03/07 (Week 4)
Progress
This week, I explored machine learning methods for gesture recognition. We originally used heuristics in order to recognize gestures, but found that heuristics often fail when the user is not standing directly facing the camera or standing on the left or right edge of the camera view. For example, an arm extended straight forward on the right edge of the screen has a large difference between shoulder X and wrist X compared to an arm straight forward on the center of the screen.
In order to collect more training and testing data, I improved our data collection pipeline to collect features by finding the x and y distances from each keypoint to the chest and normalizing the distances for a 22 feature vector. The system has a warm up time of 200 frames before it starts recording data and then records every 5th frame of the keypoints as training data.
Because the amount of data we were using were low (~1000 examples), I chose to use SVM (support vector machine) models because of the promise they were converge with low amount of training data. I built infrastructure to support multi class SVMs to take in a config file of hyper parameters and feature names, train multiple models, and measure the average performance. Online research showed that multiclass SVMs were not reliable, so I also implemented infrastructure for training and running one versus all (OVR) SVM models.
Because the model only recognizes teleop commands, the model is only used when heuristics detect that an arm is raised horizontally. I first tried using a multi class SVM to detect if the keypoint vector was left, straight, or right.
I tried the following hyperparameter combinations, with each row representing one run.
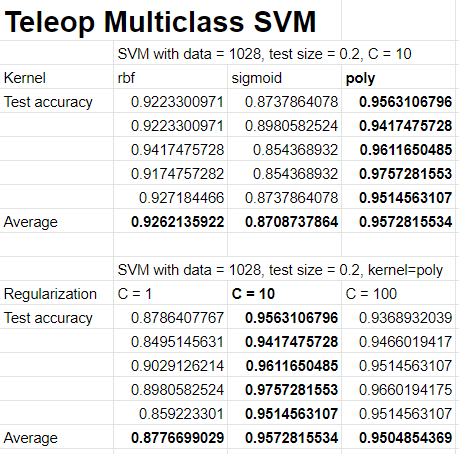
The SVM multiclass model worked great for the teleop commands, with an average test accuracy of 0.9573 over 5 runs. The best parameters were polynomial kernel and regularization constant C = 10. The regularization constant is inversely proportional to the squared l2 penality. After testing with the live gestures, it worked reasonably well and was able to handle many edge cases of not directly facing the camera and standing on the edge of the room.
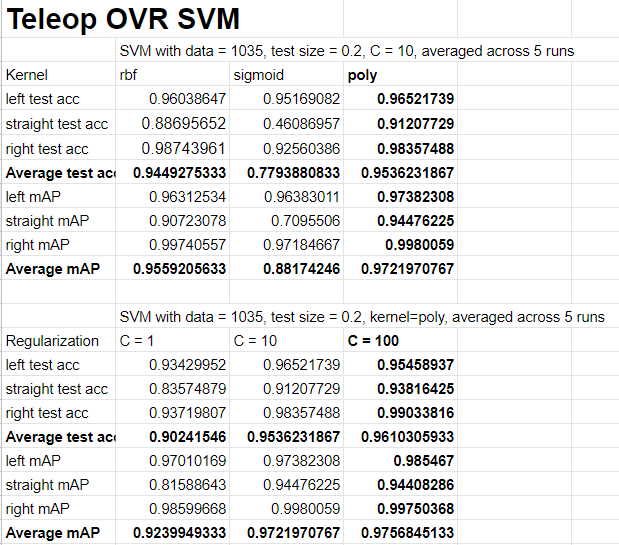
I tested the OVR SVM method on teleop commands, building a SVM for detecting left, straight, and right. The test accuracy and mean average precision is measured over an average of 5 runs. I saw slightly higher accuracy using a polynomial kernel using C = 100 with a test accuracy of 0.961. It was interesting to see a dropoff in performance for the straight data. there may have been some errors in collecting that data so I may try to collect more.
SVMs worked well for teleop data, so I wanted to try it for pointing data as well. The idea is to divide the room into bins of 1ft by 1ft and use a model to predict which bin a user points to based on the user’s keypoints. I didn’t have enough time to collect data for the entire room, so I only collected data for a row of the room. Here are the results of experiments I tried:
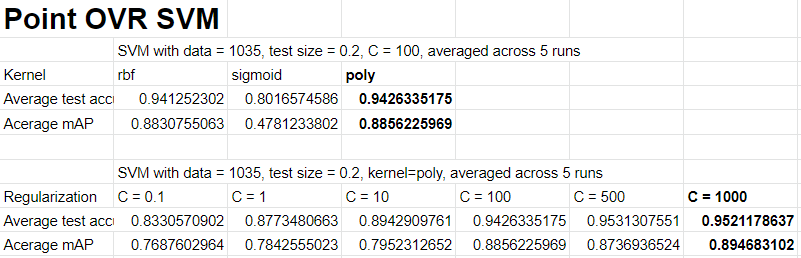
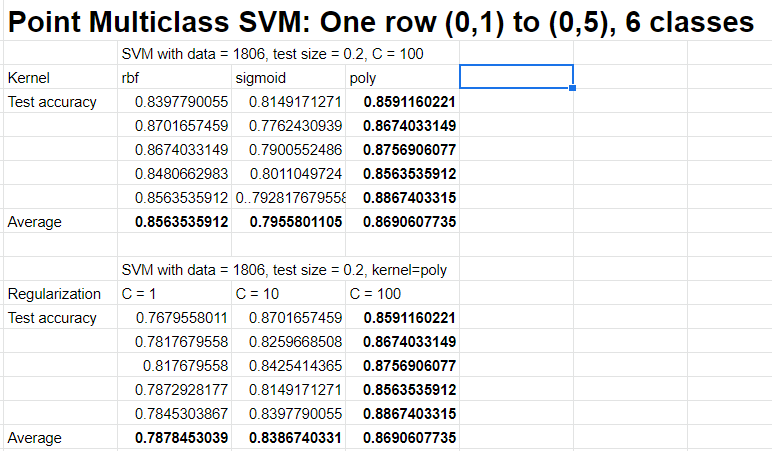
The results for point were also pretty good at 0.95 test accuracy, but the spatial data is only along one dimension, it would be interesting to see the performance across two dimensions. It is also interesting that the performance between OVR and multiclass is more noticeable with more classes, as it’s harder for one SVM to optimize many decision boundaries.
Also worked on documentation for how OpenPose / Xavier board / Roomba communicate.
Deliverables next week
I want to try to do point detection with more than one row of the room. I’m not sure if SVM methods will scale to cover the entire room or another neural network model is needed.
Higher quality data is also needed, I will continue to gather data. I want to explore other feature engineering techniques like normalizing the points but also letting the model know where the user is in the frame. I also want to experiment with using keypoints from multiple camera perspectives to classify gestures.
Schedule
On Schedule. More time needs to be allocated to gesture recognition, but it is fine because we need to wait for the mapping to be finalized to proceed.
Jerry’s Status Update for 02/29 (Week 3)
Progress
I started this week by finishing up the design presentation. I hooked up the camera system, image processing system, webserver, and robot to finish the first version of our MVP. We are now able to control the robot using teleop and also gesture for the robot to go home.
However, there are some issues with recognizing gestures using heuristics when the user is not facing the camera directly. So, I have built a data collection pipeline to gather training data to train a SVM classifier for if a teleop gesture means a person is pointing left, straight, or right. The features are normalized distances from each keypoint to the person’s chest, and the labels are the gesture. We started collecting around 350 datapoints, and will test models next week.
There are also some issues with the Roomba built in docking command, so we will have to overwrite its command to use our mapping to navigate close to home before activating the Roomba command that slowly connects to the charging port.
In addition, I installed our second camera. Processing two camera streams halves our FPS, since we have to run OpenPose on twice the frames. So, we are rethinking using multiple cameras and seeing what we can do with two cameras. Ideally we can still have a side camera so there is no one angle where you can gesture perpendicular to all the cameras in the room. I will have to keep experimenting with different angles.
I also have been working on the design report.
Deliverables next week
1. First pass of the gesture classification models
2. Finalize camera positioning in the room
Schedule
On Schedule.
Jerry’s Status Update for 02/22 (Week 2)
Progress
Rama and I got OpenPose running on the Xavier board this week. This allowed me to start playing around with the results OpenPose provides.
Gestures:
After first running OpenPose on images we took manually and videos, I was able to classify our 3 easiest gestures with heuristics: left hand up, right hand up, and both hands up. After we got our USB webcam, installed the webcam, and got the camera to work with the Xavier board (required a reinstall of OpenCV), I started working on classifying teleop drive gestures (right hand point forward, left, and right). I implemented a base version using heuristics, but the results can be iffy if the user is not standing directly at the camera. I hope to try to collect some data next week and build a SVM classifier for these more complex gestures.
OpenPose Performance on Xavier board:
Rama and I worked on optimizing the performance of the OpenPose on the Xavier board. With the default configuration, we were getting around 5 FPS. We were able to activate 4 more CPU cores on the board that brought us to 10 FPS. We also found an experimental feature for tracking that limited the number of people to 1, but brought us to 30 FPS. (0.033s per image) We were anticipating OpenPose to take the longest amount of time, but optimizations made it much faster than we expected. It should bring us below our time bound requirement of 1.9s for a response.

Openpose running with the classified gesture: “Both hands raised”
Deliverables next week
1. Help the team finish teleop control of the robot with gestures. Integrate the gestures with the webserver.
2. Collect data for a model based method of gesture classification.
3. Experiment with models for gestures classification.
Schedule
On schedule to finish the MVP!