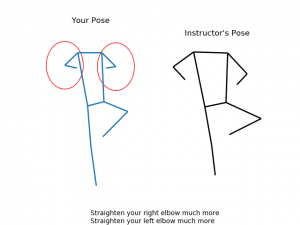
Team
This week was spent on the final polishing and integration to prepare for the final demo. We ran into a pretty big issue with our UI/script integration, so we decided to move to the Flask framework to fix our issues. We also added quality of life features like displaying saved videos and images for the user to see before corrections, and options like redoing a move if they were unsatisfied with how they performed. We also tested timing differences between running on different AWS instances, as well as different flags for the various functions to give the fastest corrections without sacrificing speed.
Kristina
After realizing that our Node.js framework was getting over-complicated to switch over to and that the way I was calling a test python script wasn’t going to work with this implementation since the local file system couldn’t be accessed, we decided to shift our framework again. Luckily Brian did more research and had time, so he took over moving the framework for the second time so that I could focus on making the UI design more presentable and polished. Before, I was focusing on making all the elements there (viewing a demonstration of the pose or move, check. web cam access, check. viewing web cam feed mirrored, check. etc) but now I had to focus on not making it an eye sore. I worked on making sure all pages could be navigated to simply and intuitively and focused on styling and making elements look nice. I also helped with testing the final product and specifically with editing the styling to make sure that everything displayed nicely on a different laptop size and still worked with the user flow, where the user has to step away from the laptop screen in order to perform their movement. It’s wild that the semester is over already and that demos are so soon!
Brian
We realized this week that we had created the UI for the different poses and were able to run the scripts separately and display them in the UI, but were not able to run them together. This is due to the fact that our UI could not access files in our local file system. Since we needed to download the user images and videos, and send them over to be processed on AWS this was an issue. After doing some quick searching, I decided that a Flask framework would solve our issues easily. Therefore I ported over our existing UI, and defined all the functions necessary to get our website to access and interact with local files.
I ensured that each page had separate accesses, and that all user files were disposed of after being used in order to prepare for the next batch. In order to make the website work with the way Flask calls functions, I had to make slight changes to the structure of the website, but was able to integrate it in a way that wasn’t noticeable to the end user.
Finally I did a lot of the testing of the final integrated product, and caught a few small errors that would have messed up the execution during the demo.
Umang
This week was the final countdown to demo day. Our goal was to get an end to end pipeline up and running, while fully integrating it with the UI. While others worked on the front end, I wanted to optimize the backend for an even smoother experience. Rather than taking 29 seconds for a video and 15 seconds for an image, I wanted to break sub-20 for a video and sub-10 for an image. The best place to shave off time was in the pose estimation by increasing the speed of AlphaPose and decreasing the frame rate of the original video.
It turned out that the UI saved the video as a *.webm file and AlphaPose did not take in this type. As such, I had to automatically a conversion function (ffmpeg was the one I picked) to convert it from *.webm to *.mp4. Unfortunately, this conversion actually expanded instead of compressed the video which led to even slower pose estimation by AlphaPose. By setting a reduced frame rate flag, I was able to subsample in the video and then run the shorter video through the pose estimation network (with the relaxed confidence, lower number of people, and a increased detection batch). With these changes, I got the video estimation down to 1 second for a 4 second long *.webm file (with added time for the ffmpeg call with the subsampling).
This updated video pipeline ran in ~11 seconds total (including up-down to the instance and the longer ffmpeg) and ran in ~8 seconds for an image. Unfortunately, the AWS instance we used for this was a P3 instance (which had an unsustainable cost of $12/hr). So we settled for the normal P2 instance (which had a cheap cost of $0.90/hr). This pipeline on the P2 ran a video through in ~15 seconds and an image through in ~9 seconds. Both of these times far surpassed our original metrics. We look forward to the demo 🙂