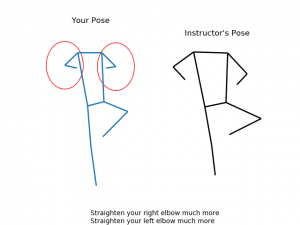
Team
Integration obviously means bugs, problems, and uncovering issues, as we have been warned so many times at t he beginning of the semester. This week, we continued the integration process by tackling the problems that arose. We realized that our UI needed a framework change in order to integrate with the way our back end was implemented and its in inputs and dependencies, so we focused on fixing the front and back end so that it could be properly integrated. We also continued looking into other ways to get the speed up we required, so we continued investigation into AWS and looking into possibly using a different pose estimator in order to get accurate but more efficient results. Our final presentations are next week, so we also spent time working on and polishing our slides.
Kristina
After realizing my big mistake of not looking ahead to HOW the back end would connect to the UI when designing and starting work, I had to move our front end code to a different framework. Initially I was using basic HTML/JavaScript/CSS to create web pages, but I realized that calling our python correction script and getting results back wouldn’t really work, so I decided to use Node.js in order to create a server-side application that could call the correction algorithm when an event that the user initiates happens. I honestly just chose the first framework that seemed the simplest to migrate to, and this ended up not working out as well as I had hoped. I ran into a lot of problems getting my old code to work server-side, and still need to fix a lot of issues next week. Since I’m also the one giving our presentation next week, I also spent some time preparing for it and practicing since I’m not great at presentations.
Brian
This week was a constant tug and pull between the UI side of the project and the backend. Some of the outputs that we thought were going to be necessary ended up needing to be changed to accommodate some of the recent changes in our app structure. A lot of the week was trying to get things formatted in the right way to pass between our separate parts of the project. In particular I was having issues with sending information to and from the AWS instance, but in the end was able to solve it with a lot of googling. I also worked on refactoring the code to be more editable and understandable, as well as on the final presentation.
Umang
This week I helped with the final presentation. Then, I decided to run a comparison between AlphaPose and OpenPose for running pose estimation on the AWS instance. We have a ~8 second up and down time that is irreducible but any other time is added due to the slow pose estimation. As such, I wanted to explore if OpenPose is faster for our use case on a GPU. OpenPose runs smoothly but has much overhead if we want to retrofit it to optimize for our task. Running vanilla OpenPose led to a respectable estimation time for a 400 frame video (on one GPU), but was still over our desired metric. Though the times were comparable at first, when we added flags to our AlphaPose command to reduce the detection batch size, set the number of person to look for, and reduce the overall joint estimate confidence, we were able to get blazing fast estimation from AlphaPose (~20 seconds + ~8 seconds for the up down). This means we hit our metric of doing to end to video pose correction in under 30 seconds 🙂 Final touches to come next week!