






Carnegie Mellon ECE Capstone, Spring 2019 | Wenting Chang, Anja Kalaba, Nolan Hiehle
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
I finished the finalized our design concepts, created the design slides and have been working on the design review. I had to review presenting and practice the slides. I was also in communication with Professor Dannenberg and have settled we cannot contact the team members of Theme Extractor but will be in contact with his grad students to borrow melody extraction from MIDI files. We also finalized a division of labor, so next week I can start on the input discretization and type warping algorithm.
Definitely on schedule as long as implementation starts next week!
A database of theme extracted songs, probably about 3 songs to start. Some humming samples from all 3 team members. The ability to discretize vocal input. A sketch in C for how to begin the time warping algorithm on the data.
This week I began working on my arm of the project, the chroma feature similarity matrix analysis. Since the first step is building chroma features (also known as chromagrams), I’ve started looking into available toolboxes/code for creating these. Most of the existing work seems to be in MATLAB, so if I want to use an existing chromogram library I’ll have to decide between working in matlab and compiling to c++ or simply drawing inspiration from the libraries and building my own implementation. Even within chroma feature extraction, there are lots of design parameters to consider. There will be a choice between how the chroma vector is constructed (a series of filters with different cutoffs, or fourier analysis and binning are both viable options). On top of this, Pre and post-processing can dramatically alter the features of a chroma vector. The feature rate is also a relevant consideration: how many times per second do we want to record a chromagram?
Some relevant pre-and post-processing tricks to consider:
accounting for different tunings. The toolbox tries several offsets of <1 semitones and picks whichever one is ‘most suitable’. If we simply use the same bins for all recordings we may not need to worry about this? but also, a variation of this could be used to provide some key-invariance.
Normalization to remove dynamics–dynamics might actually be useful in identifying a song. We should probably test with and without this processing variant.
“flattening” the vectors using logarithmic features–this accounts for the fact that sound intensity is experienced logarithmically, and changes the relative intensity of notes in a given sample.
logarithmic compression and a discrete cosine transform to discard timbre information and attempt to get only the pitch info
Windowing different samples together and downsampling to smooth out the chroma feature in the time dimension–this could help obscure some local tempo variations, but its unclear right now if that’s something we want for this project. This does offer a way to change the tempo of a chroma feature, so we may want to use this if we try to build in tempo-invariance.
As it turns out, these researchers have done some work in audio matching (essentially what we’re doing) using chroma feature, and suggest some settings for their chroma toolbox that should lead to better performance, so that’s a great place for us to start.
an important paper from this week:
https://www.audiolabs-erlangen.de/content/05-fau/professor/00-mueller/03-publications/2011_MuellerEwert_ChromaToolbox_ISMIR.pdf
http://resources.mpi-inf.mpg.de/MIR/chromatoolbox/
http://resources.mpi-inf.mpg.de/MIR/chromatoolbox/2005_MuellerKurthClausen_AudioMatching_ISMIR.pdf
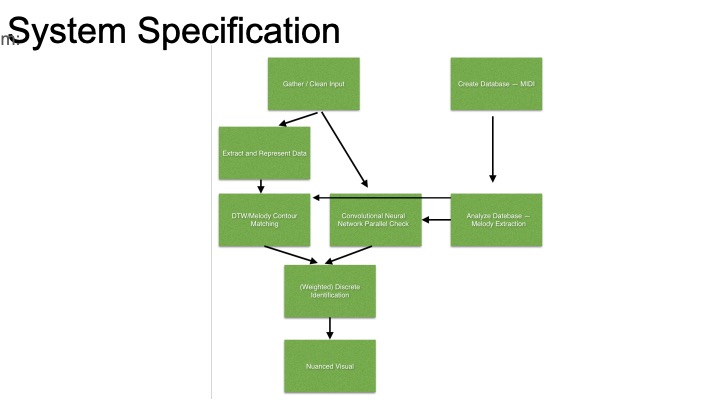
In the process of putting together the design presentation and design document, we have decided to take two parallel paths on our project, as described in our team status report. One will follow a similar path to the query by humming project that will match against a MIDI library, while the other will use chroma feature analysis to examine similarities between MP3s.
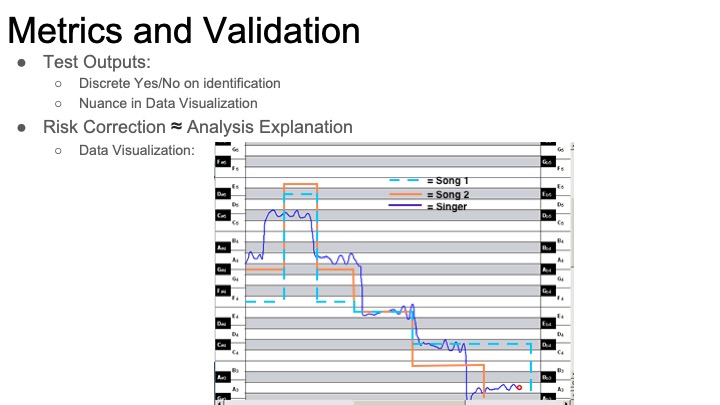
From the data visualization standpoint, the two approaches will be generating results in two different ways. Since the first approach will be borrowing work from other research, I am not completely sure how that will be able to be visualized – whether it will be a black box computation or whether I can extract out its process to display it. The second approach will follow what I mentioned last week with showing the similarity matrix.
While the UI design of the app will be done later, I have begun the process of deciding on its functionalities and features. Similar to the existing Shazam, users will tap to begin singing and matching. We hope to have sliders for the user to weight melody and rhythm differently depending on what they are more confident in. Once our algorithm has finished processing, it will pop up with the matched song or no match if it could not find anything. Either way, the user will be able to see some of the work that was done to match the song. The level of detail that we will show initially is yet to be determined (for example, we can include a “see more” button to see more of the data visualization aspect). The app will maintain a history of the songs that have been searched and potentially the audio files that it has previously captured, thus also maintaining a history of what has been matched to the song before as well.
Now that our design is more concrete, we have reached the phase where we are going to begin implementation to see how our methods perform. I would like to begin data visualization with some test data to see how different libraries and technologies will fit to our purposes. Also, in conjunction with Nolan, I will be looking into chroma feature analysis and using CNNs to perform matching.
This week we decided to split our engineering efforts and pursue two song identification strategies in parallel. This will give us a greater chance of success, and it will let our two strategies cross-verify each other.
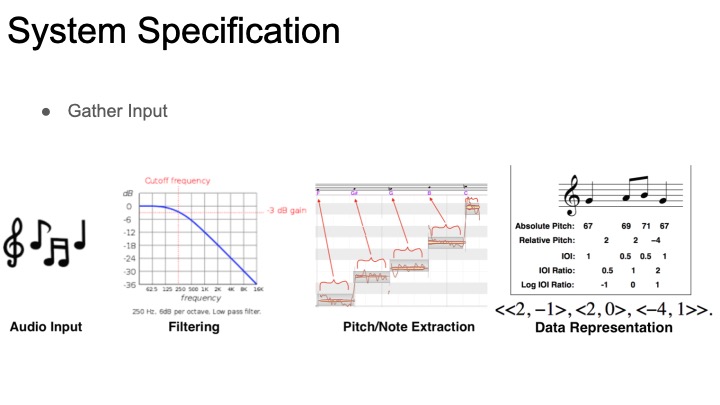
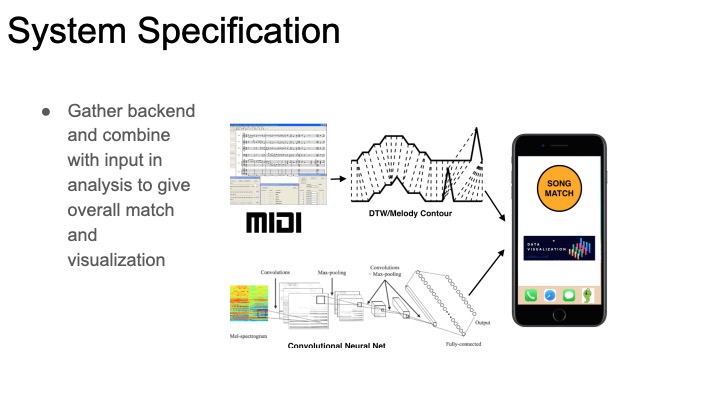
Our first strategy will draw from Roger Dannenberg’s MUSART query by humming work from ~2008. This will do some signal analysis of the sung samples and extract notes and rhythms. Then, these notes and rhythms will be matched against a library of MIDI files using some of the algorithms from the paper. In order to do this, we need to extract the melodies from each MIDI file. The query by humming paper we’re referencing used a program called ThemeExtractor that analyzes songs and searches for repeated patterns, returning a list of potential melodies. Unfortunately, ThemeExtractor is no longer available. We have found a CMU researcher (thanks professor dannenberg) who’s currently doing work with automated MIDI analysis, and has a program that should be able to extract melodies. This method will have the advantage of being key-invariant and and tempo-invariant: a user singing too fast and on the wrong starting note should still be able to find a match.
Our second strategy will be to match an mp3 file to the sung sample. This has the obvious advantage of being usable on any song–most songs don’t have a MIDI version of them easily available, and there’s no way to automatically convert a song into a MIDI file. This would let us expand our library to basically any arbitrary size instead of being limited to songs with available MIDIs. To implement this, we will use the strategy I outlined in my last status report: convert both the sung sample and original song into a chroma feature matrix and run some cross-similarity analysis. Some researchers have had success using Convolutional neural nets on cross-similarity matrices of songs compared with cover versions, but this problem is slightly different: we should expect to see much less similarity, and only across a small time window. We will definitely explore CNNs, but we will also explore some other pattern recognition algorithms.
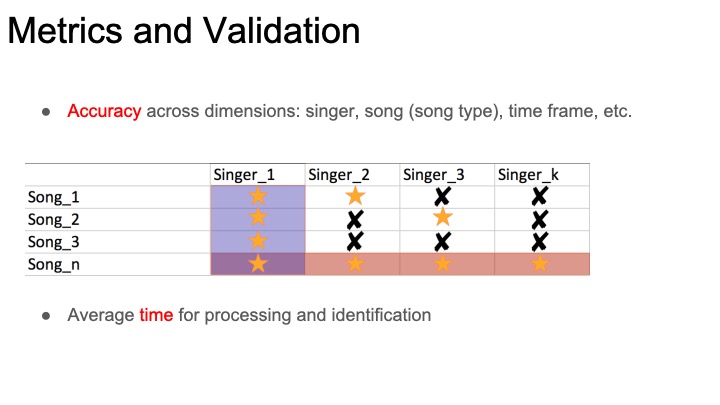
Once we have more data on how both of these algorithms are working, we can decide how we want to integrate them into an app and work on visualizations of our algorithms for our own debugging purposes and for the end user’s enjoyment (e.g. a cool animation showing you how we found your song).