This week I met with the team to finish discussing the design choices that needed to be made regarding our individual contributions. These are some of the questions we answered regarding my work and the project at large:
Where is everything going to be hosted?
We have three options:
- A large portion of the processing and scheduling can be hosted on AWS
- The remote server communicates to a Raspberry Pi that sends power to the solenoids that press the keys
- Pro: We gain access to more compute power
- Con: Communicating between the users computer and the raspberry pi will be bottle-necked by the internet upload and download speeds of each device
- All of the computation is hosted on a raspberry pi
- Pro: We no longer are bottle-necked by transmission rates between devices
- Con: We lose the compute power necessary to host everything
- All the computation is hosted on a Jetson Nano
- Pro: We no longer are bottle-necked by transmission rates between devices
- Pro: We gain access to more compute power
Were we completely set on implementing the physical device, we would implement it on Jetson Nano. However, if our proof of concept experiment doesn’t go well and we pivot towards a virtual piano, the need for speed goes away, and AWS becomes the best option. With this in mind, we’ve chosen to go with the AWS model, it provides the compute power necessary to host a majority of the processes, and also gives us room to pivot these processes onto a Jetson if the physical interface does finally get built.
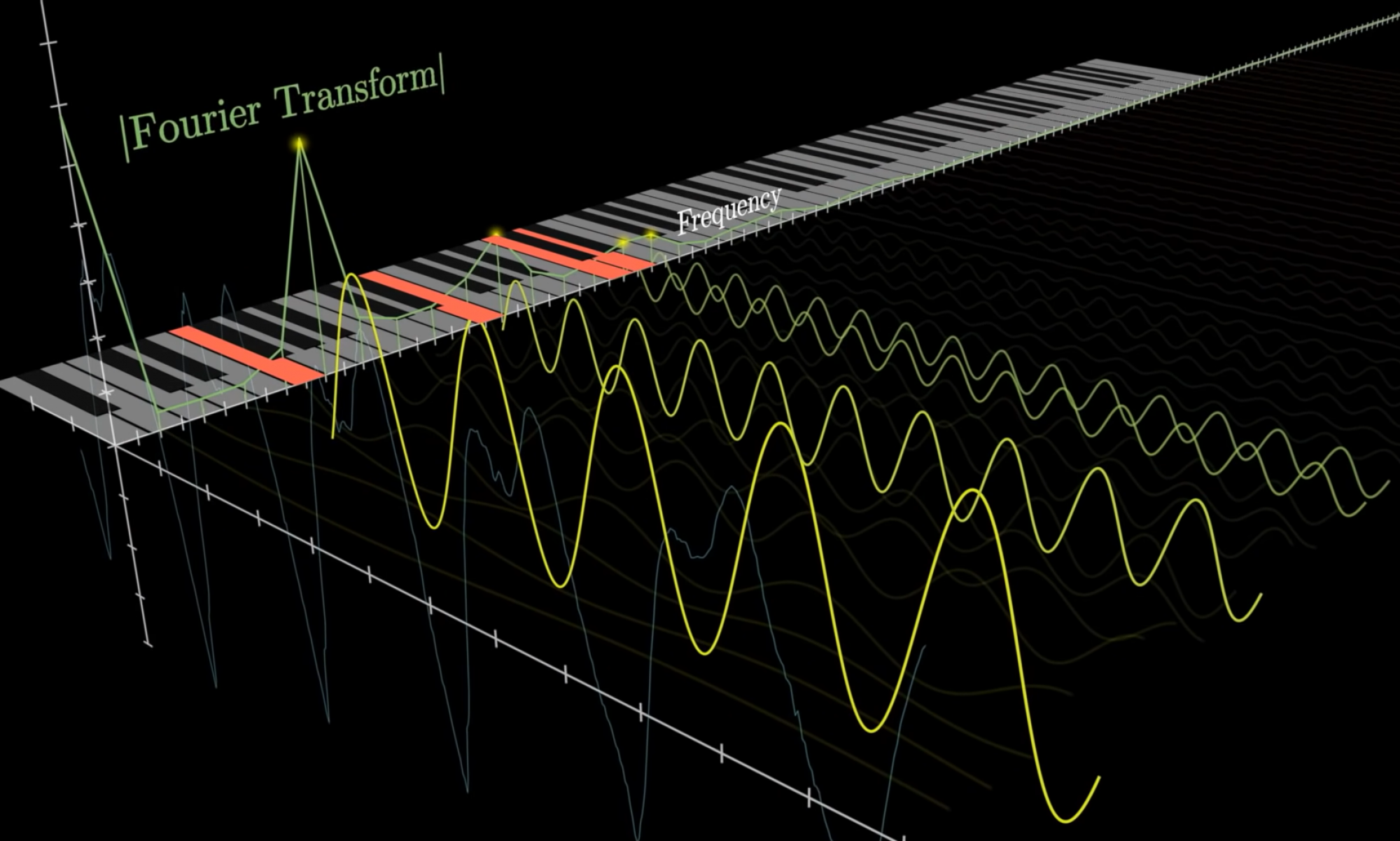
How are the frequencies for each sample going to be gathered?
- The audio file contains information in the time domain
- We need to sample the audio file for some time in order to collect the frequencies that make up the sounds played within that time
- If that window is too short, then we get inaccurate readings into what frequencies make up that sound
- If the window is too long, then we won’t process the incoming sounds at a speed that is pleasurable to the user
- A natural compromise arises from the sampling requirements of the audio file and the play rate of the piano keys. An audio file is sampled at 44.1kHz (i.e 0.0268ms) and a piano key can be pressed at most 15 times per second (i.e 66.67 ms), check out Angela’s post for more information on how we arrived at that number! At those rates, there are ~2487 audio samples between the moments we can play a key. This window is large and within our timing constraints — exactly what we were looking for!
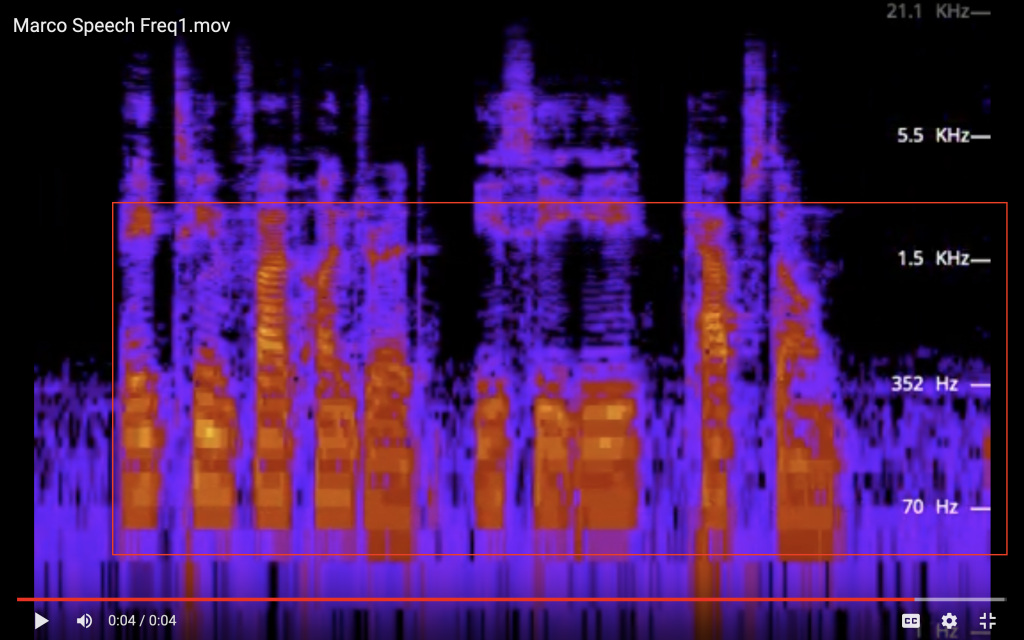
Are we ‘punching holes’ into the audio or ‘blurring it’ out around the frequencies of the keys?
- 5kHz is typically the highest energy considered in speech perception research, and 80Hz is typically the fundamental frequency of the adult voice [1]. That’s a range of 5k – 80 = 4920 frequencies that the human voice could be made up of. With only 69 keys (i.e distinct frequencies) if we simply filtered out the energy at those 69 frequencies from the human speech input we’d at best be able to collect (69/4980) = 2% of the frequencies that make up the human input. This is what I refer to as ‘punching holes’ through the input
- Instead we’ll use the 69 distinct frequencies to collect an average of the nearby frequencies at those values — this is what I refer to as ‘blurring’ the input. By blurring the input as opposed to punching holes in it, we’ll be able to collect more information about the frequencies that make up the incoming speech.
References
- Monson, B. B., Hunter, E. J., Lotto, A. J., & Story, B. H. (1AD, January 1). The perceptual significance of high-frequency energy in the human voice. Frontiers. Retrieved October 1, 2022, from https://www.frontiersin.org/articles/10.3389/fpsyg.2014.00587/full