
This past two weeks, I worked on both text detection and image classification.
The main problem of text detection was time and accuracy. I explored several different options other than Tesseract, and decided to use EasyOCR. Unlike Tesseract, which doesn’t automatically draw bounding box around the text, EasyOCR has such feature, which leads to better accuracy than Tesseract, but it is slow without GPU. When I locally ran EasyOCR on my computer (only CPU enabled), it takes ~13 seconds to detect and extract the text; however, when I run it on Colab with CUDA enabled, it takes ~4 seconds for same image.
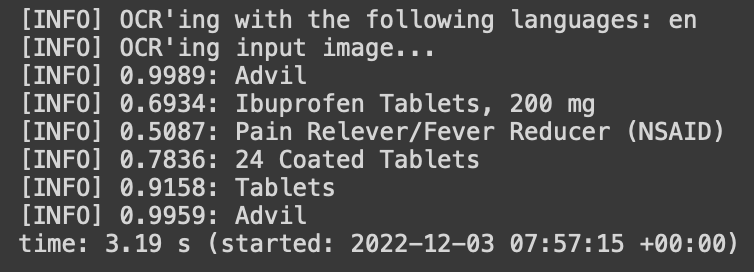
As shown above, it accurately extracted most of the text.
It is still very slow when we think of applying it in the checkout system because the customers wouldn’t want to wait ~4 seconds per item. Additionally, I wasn’t sure using NVIDIA Jetson will have better performance than Colab. With these challenges, it is critical to have CNN implemented in our project, and have text detection performed only when CNN can’t recognize the product.
While CNN was Rachana’s responsibility, she has dropped the class last week without any work done. After discussing with the professor, I have decided to take over her CNN part as well. I explored some options like YOLO and MobileNet that the professor suggested me, and decided to train YOLOv5 with my custom dataset.
As soon as I came back from the break, I took 200 images of Advil and another 200 images of Tylenol in different angles, and annotated them with Roboflow for better accuracy. I converted them into YOLOv5 compatible dataset, separated into train (70%), valid (20%), and test (10%), and trained the YOLOv5 model. The result was successful– the test set contains 40 images of Advil and Tylenol, and my custom trained YOLOv5 model classified them with 100% accuracy. I got a reasonable time as well– it only took ~8.5 milliseconds to classify each image.
Below are the result of my custom trained YOLOv5 model.
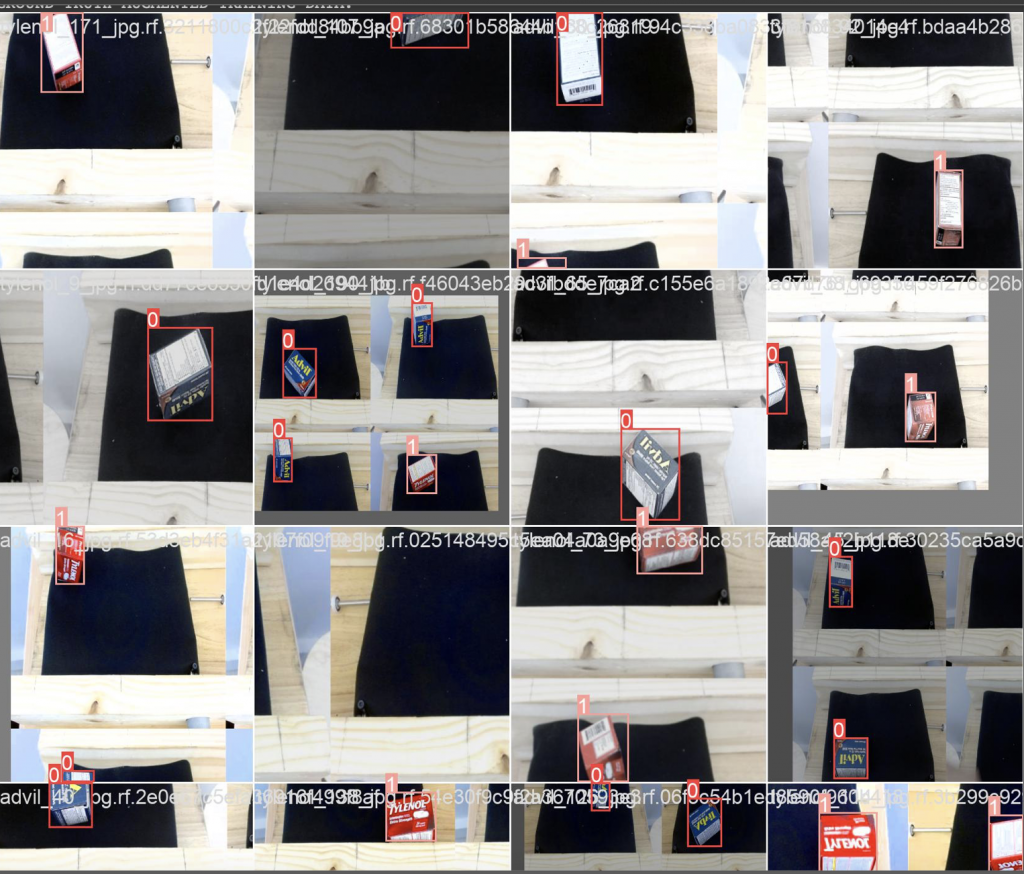
0 represents Advil and 1 represents Tylenol
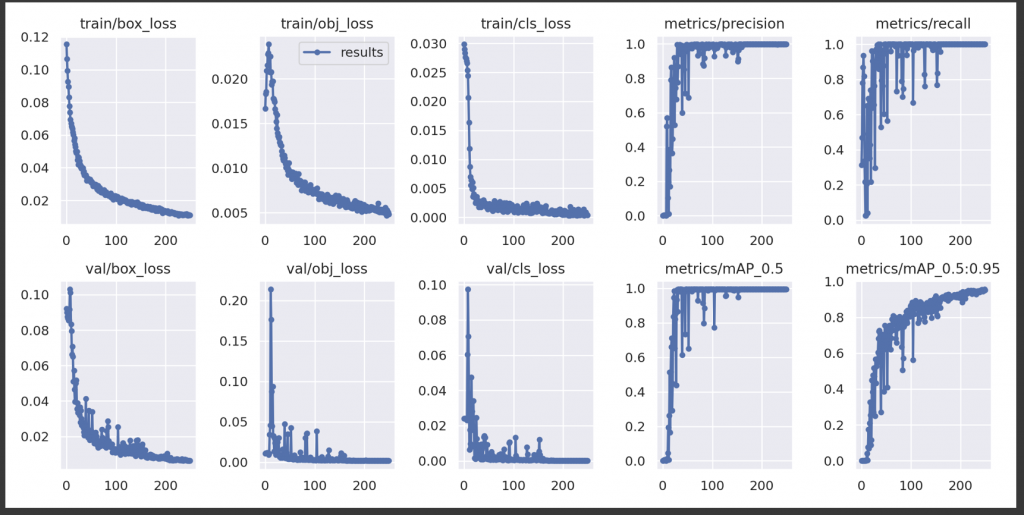
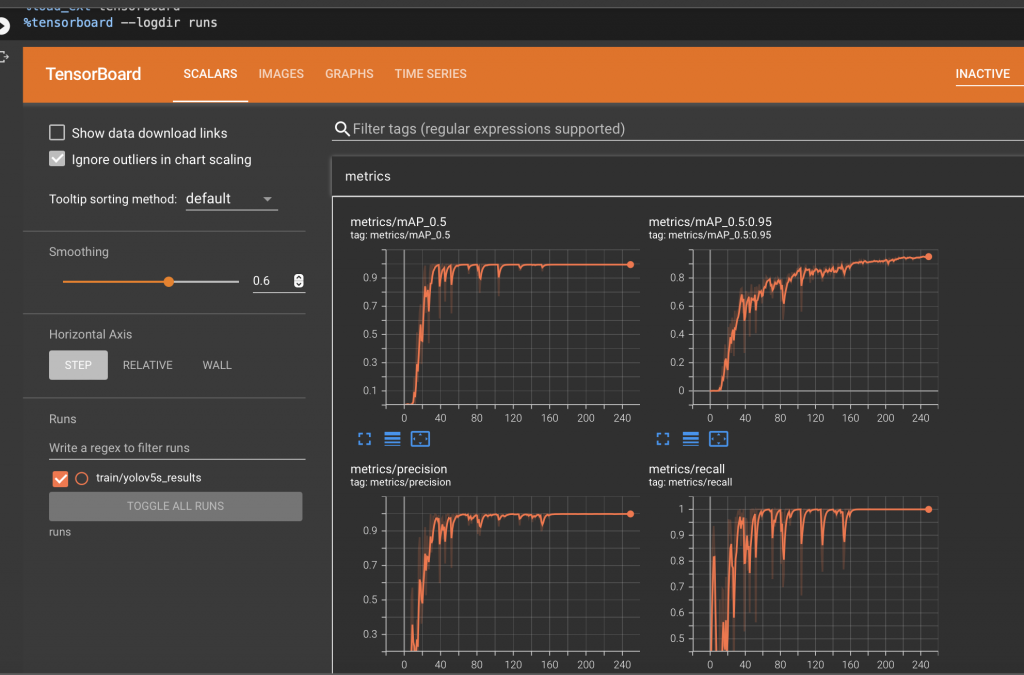
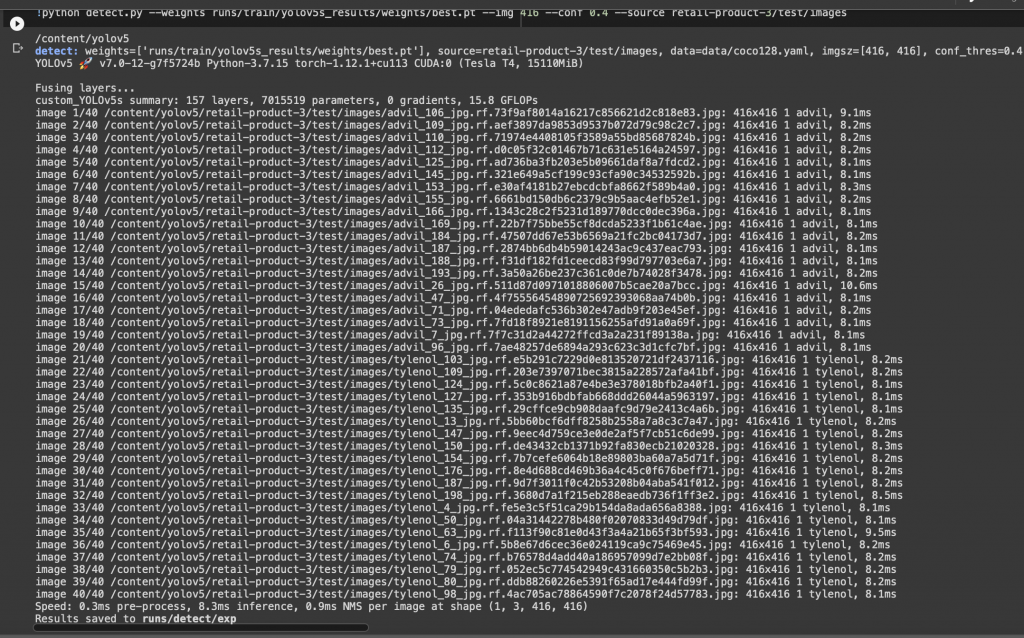
The above shows that it classified 40 test images of Advil and Tylenol with 100% accuracy.
Currently, my model can only detect Tylenol and Advil. Over the weekend, I will expand the model to detect more items like different types of chocolate bars, and add the result to our final presentation slides as well.
I think I made a good progress this past two weeks, but I think I am still behind on schedule due to unexpected work (CNN). I was hoping to finish web app this week, but I couldn’t. I hope to finish web app early next week, and start integrating with my model.