
This week was fairly uneventful, as it was the week of Spring break, and the week prior we were primarily focused on finishing the design document. During the current week, some very minor prototyping/testing occurred with the fish eye lens camera, with the camera in bird’s eye position. The localization/pixel diffing worked pretty well (with one caveat) but the results when performing sift on the images were pretty bad, so will likely need to iterate as a group (see Keaton’s status update).
Keaton’s Status Report 2/19
When I left last week, I was still scrambling to determine what algorithm(s) we would use in order to perform object detection/classification, which I continued into this week. As of the end of this week, we have finalized our algorithm choice (SIFT) and the grocery list which we will be supporting. I think we have a strong plan moving forward into design week, and I feel confident in my ability to actually implement the CV component of this project.
For review, at the start of the week, I failed to find any effective answers to the issues we were facing using SIFT/ORB, those being:
- Label visibility was paramount, as the majority of key points were found on the labeling for the majority of the items we were testing
- Every nutritional label was largely identical to every other nutritional label, which led to a large number of misidentifications (specifically when looking for milk, as the nutrition info was in the iconic image)
As such, I began exploring some alternative methods to doing object classification. I looked into YOLO, as it was mentioned during a previous abstract presentation, and I found a paper that used YOLO on an open source grocery dataset to good effect, so I figured it might work for our purposes. For a proof of concept I found another similar dataset, and converted it to YOLO format (this ended up being most of the work, surprisingly). I then trained the smallest available model for ~10 epochs on the open source dataset just to make sure that I could (you can see the trained model in the cloned YOLOv5 repo, in runs/train). I also set up an account on CVAT, which we could use to split the work while annotating images, which would be needed if we were going to pursue this. However, the process of generating enough data to make it viable was a large amount of work, and it didn’t guarantee our ability to resolve the issues we had already encountered with SIFT/ORB/BRIEF. Thankfully, I waited until after Wednesday before delving further.
On Wednesday, we met with Prof Savvides and Funmbi, and they recommended that we decrease the scope of this project by imposing the following requirements on the user:
- The objects must be stored such that the label is visible to the camera
- The user can only remove/add one item at a time
With the first requirement, the majority of the issues we were facing with SIFT/ORB/BRIEF became a non issue. The second rule is to allow for unsupported object detection/registration of new items via pixel diffing. This is something which we need to implement later, but isn’t a concern as of right now.
I re-did an eye test on various common items in my kitchen (requiring their label was front and center) and I found that the following items seemed to work well with the given restrictions: Milk, Eggs, Yogurt, Cereal, Canned Beans, Pasta, and Ritz crackers. We will be using these moving forward. SIFT also continued to perform the best on the eye test.
Overall, I’m fairly satisfied with both my performance this week, and where we are as a group. I think the scope of the project is no longer anywhere near as daunting, and we should be able to complete it fairly easily within the given timeframe. Major tasks for the next week include finishing the design documentation (this obviously will be split among all of us, but I expect it to still take a fair amount of work), and working with images from the rpi camera which is arriving, to find optimal angle/height for taking photos.
As mentioned in the team post, we also moved everything to a shared github group, CV code can be found at:
Team Status Report for Feb 19
Feb 19
This week has mostly been finalizing the details of our project in preparation for the design presentation/documentation. At this point, we feel fairly confident in the status of our project, and our ability to execute it.
Major design decisions:
- Cut back on the scope of the project/increased the burden placed on the user.
- Scale back scope of website
- Commit to SQLite
- Reorganized Gantt chart
- Finalized overall design
1) On the advice of Prof. Savvides and Funmbi, we decided to decrease the scope of this project by imposing the following requirements on the user:
- The objects must be stored such that the label is visible to the camera
Originally, it was near impossible to identify an item using ORB/SIFT/BRIEF unless the label was facing the camera. We initially tried to resolve this by resorting to using some sort of R-CNN/YOLO with a dataset which we would manually annotate. However, the process of generating enough data to make it viable was too much work, and it didn’t guarantee our ability to resolve the issues. As such, we are adding this requirement to the project, to make it viable in the given time frame.
- The user can only remove/add one item at a time
This is a requirement which we impose in order to handle unsupported items/allow registration of new items. When the user adds a new item which we do not support, we can perform a pixel diff between the new image of the cabinet and the previous image before the user added the unknown item. We are not currently working on this, but it will become important in the future.
- Finalized the algorithm (SIFT) and finalized supported grocery list
Baseline SIFT performed the best in our previous experiments, and continued to perform better this week when we were adjusting the grocery list. We may experiment with manually changing some of the default parameters while optimizing, but we expect to use SIFT moving forward. When basic eye tests with various common items, we found these items to perform well with the label visibility restriction: Milk, Eggs, Yogurt, Cheese, Cereal, Canned Beans, Pasta, and Ritz crackers.
2) Additionally, with input from both Prof. Savvides and Funmbi, we’ve majorly cut back on the stretch goals we had for the website. Given that this project is meant more as a proof of concept of the computer vision component rather than an attempt to showcase a final product, we’ve used that guideline to scale back the recipe suggestions and modal views of pantry lists. The wireframing for the website isn’t as rigorous anymore, though I (Jay) still want to explore using Figma (more in my personal blog post).
Account details won’t be as rigorous of a component as we had initially envisioned, and, given that performance isn’t as much of a concern for a few dozen entries per list, we’ve decided to stick with SQLite for the database.
3) Minor housekeeping: after seeing what other groups did for their Gantt charts, we decided that converting our existing Gantt chart into a format requiring less proprietary software would be beneficial for everyone and make updating it less time consuming. Updates to the categories (for legibility) and dates (for feasibility) have been made. New Gantt chart can be found here.
We also moved to a shared github group, code can be found at: https://github.com/18500-s22-b6.
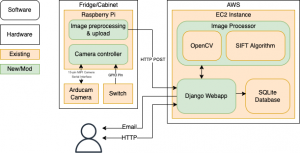
4) Finalized overall design. After some discussions, we finalized the design of the different components of our project. For the physical front end, we found appropriate hardware and placed the order. For the backend, we decided to use a single EC2 instance to run the webapp and the CV component. Although scalability is important for smart appliances, it is not the priority for this project. Instead, we will put our focus on the CV component and make sure it works properly. We do have a plan to scale up our project, but we will set that as a stretch goal.
Team Status Report for Feb 12
Unfortunately our team did not sort out all the details of our project before the proposal presentation so this week we have been playing catch-up. We discussed/decided on implementation details and performed benchmarks on different object detection algorithms. While we made progress, we failed to make significant headway and catch up to where we feel we ought to be.
Flow diagram for the website
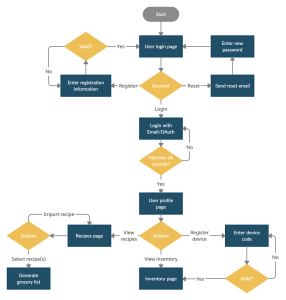
Flow diagram for a user of the system
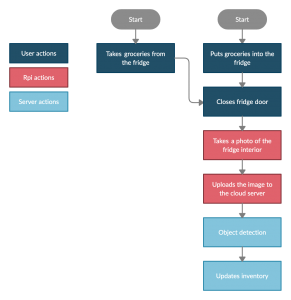
As shown above, we’ve decided against using a Jetson Nano for hardware. Instead, we will be using a cheaper RPI, which will snap photos, and send them to the cloud for processing. Our reasoning for this is that our use case is highly tolerant of delay, and has very low usage (a few times a day at most). As such, there’s no reason to have high power expensive hardware bundled with the application itself, when we could just as easily have the processing done remotely. We also don’t expect this to have significant downside, as the CV component already required internet access to interact with the web app component. This will become an issue, however, if the project needs to scale up and support thousands of users, where the computing power of the cloud server will become a bottleneck. In that case, we will turn to distributed computing.
We also decided on hardware for the Camera (Arducam OV5647, with a low distortion wide angle lens, to be mounted on the ceiling of the storage area). Lens can be removed/changed, if it becomes an issue while testing.
The work on benchmarking different object detection algorithms was a largely failure. SIFT currently seems to be the favored algorithm, but there were several issues while doing the benchmarking. A fuller list/description of the issues can be seen on Keaton’s personal post. Essentially, all the algorithms performed exceedingly poorly for geometrically simple items with no labels/markings (oranges, apples, and bananas). We expect this was likely exacerbated by some background noise which was thought to be insignificant at the time. Because of this, we didn’t feel confident in making a hard decision on the algorithm moving forward. Since this is the most important component and we are already behind, we likely devote two people the following week to work primarily on this, to ensure we get it up to speed. We will continue doing the benchmarks over the next week to decide what hardware components & algorithms to use. We will also talk with the faculty members to iterate our design.
Keaton Drebes’s Status Report for Feb 12
My major task for the week was to benchmark the various potential CV algorithms, and determine which to use moving forward. Unfortunately, I failed in this regard. While I was able to benchmark the various algorithms, I was unable to draw any sort of meaningful argument as to which is superior.
My process for doing benchmarking was fairly simple. I manually took a number of photos of the items on our list, with an iphone camera. These will vary slightly from the images which will be taken with the RPI (fisheye lens from a slightly different angle) but should be sufficient for testing purposes. The inside of the fridge I used for an example also has a small amount of visual clutter. I manually created a bounding box for each of the images I took, in order to determine what number of good matches we observe. Since Sift/Fast/Orb all inherent from the same superclass, the algorithm to use could simply be passed as an argument. After creating the code and debugging, I ran into an immediate problem. All the algorithms seemed to have vastly more failure matchings for the less geometrically complicated items then what I was expecting going in. The items with labels also were performed quite poorly when the labels were obscured (which was expected). I made a simple sanity check that highlighted the matches, the results of which I show below:

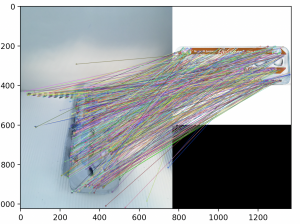
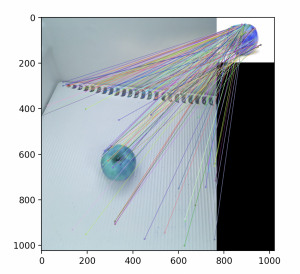

I’ve only shown the results with SIFT, but the results for FAST/ORB were generally as bad if not worse. I expect that the errors are likely due to what I previously had considered “very minor” background clutter, judging by the number of false matches with the ridges in the back. SIFT won for most of the categories, but I can’t feel confident with the results until it’s repeated in an environment with less background noise, and we are able to get something resembling the number of correct matches required for our use case. In the future, I will do an eyeball check before bothering with manually adding bounding boxes. I did a few eyeball checks while using various preprocessing tools, but none had a significant effect as far as I could see. I’m uncertain how to handle the label being obscured/non-visible, as this will likely pose a greater problem going forward.
Ultimately, I think this week was a failure on my part, and has in no way helped our being behind. The issues encountered here must be addressed quickly, as all other aspects of the project are dependent on it. As such, both myself and Harry will be working on it come next week. I hope, by next week, to have actually finished this, and have a solid answer. Concurrent with this, I hope to develop a standardized testing method, so we can more easily fine tune later. I hope to also investigate how best to mitigate the labeling issue, and provide a reasonable fix for this.
Current code/images used can be found at: https://github.com/keatoooon/test_stuff