

Team Status
We successfully integrated our system and ran it end-to-end with decent results for the April 4 demo. The two major accomplishments were
1. Integrating all of the individual processors and persisting speaker data (ie speech embeddings) for easy lookup in our database. We faced a number of challenges completing this process due to race conditions and serialization problems, but eventually we got the system to run correctly.
2. Successfully implemented speaker classification by training speaker on our own data (we used friends and family to get ~10-12 internal speakers) along with the external held-out set from Voxceleb.
In its current form, the Yolo app currently accepts “registration” of a new user and also “authentication” of an already registered user. There isn’t much change made to our system diagram. We updated our schedule slightly to accommodate the setting up for Baidu Deep Speech for speaker presence verification and also for fine-tuning our model to improve speaker EER and accuracy.
After our demo and based on how we are looking at the moment, we had to update some tasks in our Gantt Chart in order to get everything good and going for our Final Project Demo in May.
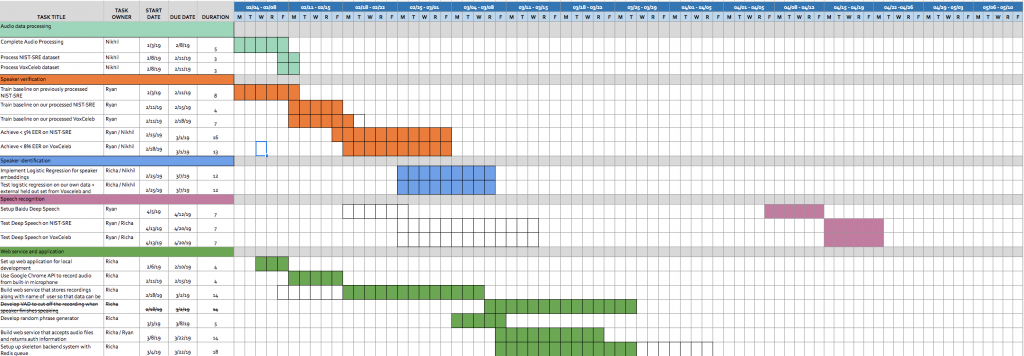

Updated Gantt Chart
Team Member Status
Nikhil Rangarajan
Prior to the demo, Ryan and I worked a lot on integrating the identification and verification inferences and tie them all together along with the Logistic Regression model that we mentioned in the previous status report. We had to play around with a lot of the LR parameters to see what worked best and what gave us the best separation/results.
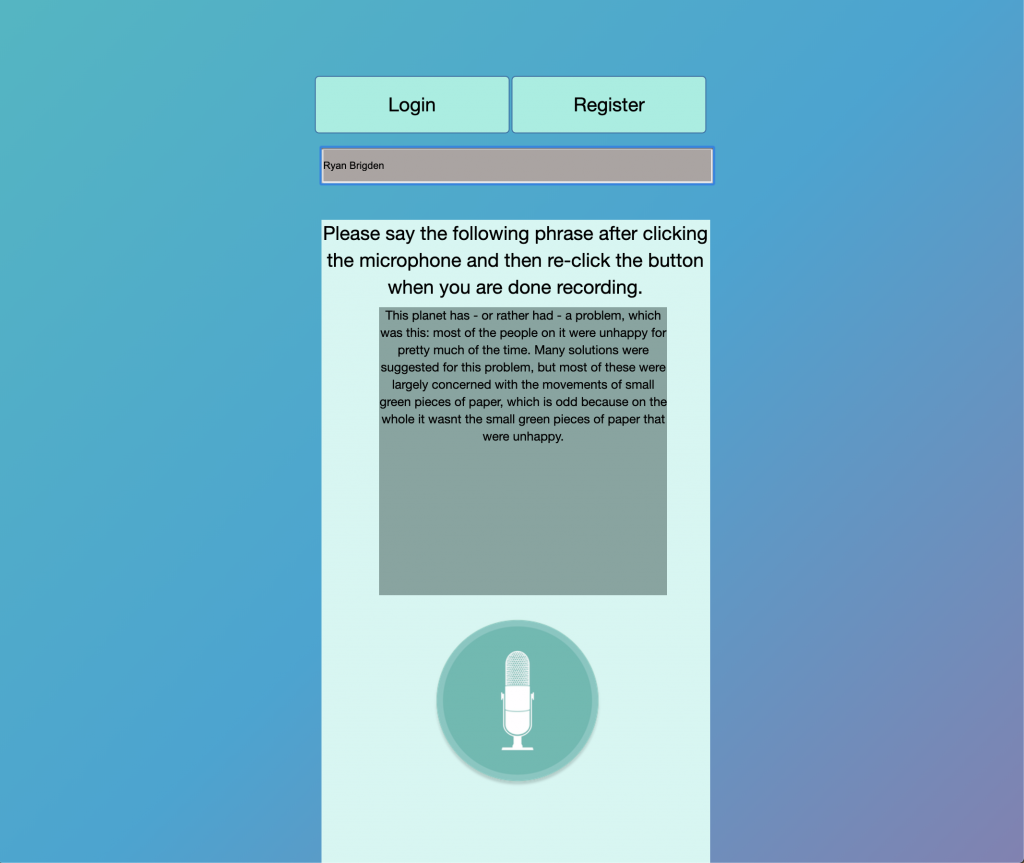
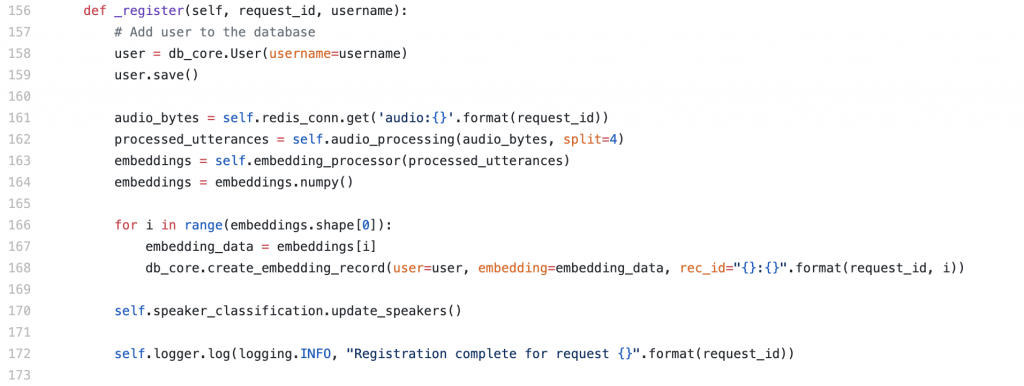
For registration, our Web App displays a random paragraph that a user reads, and this audio file is hashed and stored in our database. A completely new set of Logistic Regression parameters are learnt for each internal speaker in our database now that a new speaker is added (one vs rest binary classifications) and these weights are stored. A user has finally registered.
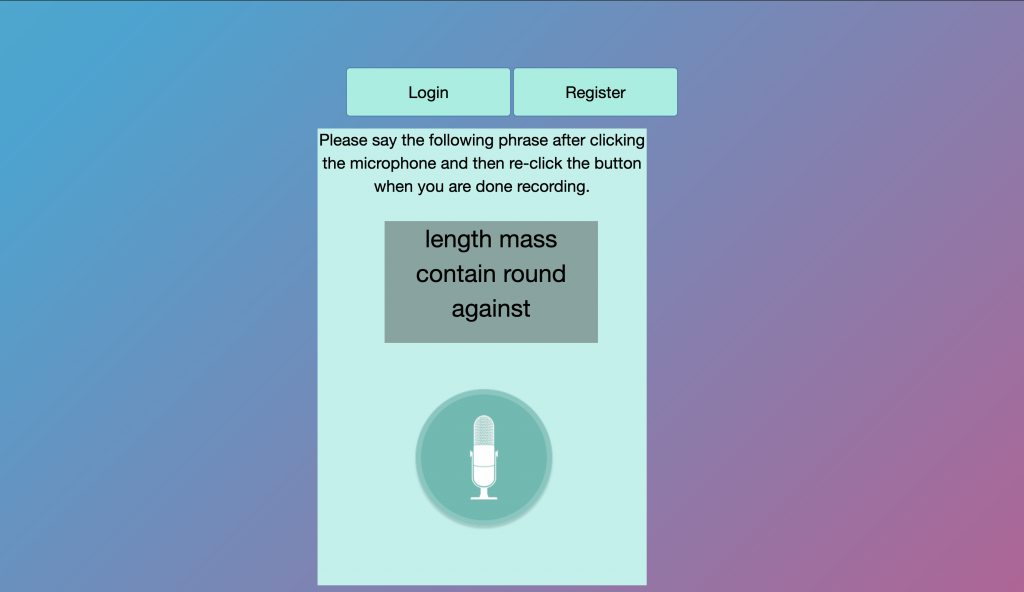
For login, a user utters 5 randomized words (which we will probably have to change in the upcoming weeks to more words, and also words that make more sense together that are not completely independent of each other) and the embeddings for this utterance is tested on all Logistic Regression parameters for each speaker. If the probability of a particular speaker is above a certain threshold the speaker’s name is outputted, else a None is returned.
For the future, we need to fine-tune a lot of our parameters to see what works best with the highest accuracy and additionally, implement Baidu Deep Speech for the speaker presence verification.
Richa Ravi
I worked on changing the layout and design of the UI – changed a lot of the html and css and added some animations from codepen. Changed the usage so that the user only needs to click one button to start and stop recording themselves speaking. Wrote code to create database tables for the data. Used the peewee framework to define the database tables and classes – peewee framework is very similar to django models so it was easy for me to understand and use. I wrote some python code to wait for the redis queue to return a result about whether a user was found during login. If a user was returned I display this user on the template. I also added a check to see whether a username already exists during registering. To do this, I created a new model on the frontend to store all the usernames. If the username already exists, an error message is displayed and the username is not registered.
Ryan Brigden
I integrated and tested to end-to-end system for the demo we had on April 4. To reach this milestone and demonstrate a working, but not final or polished product, I accomplished the following tasks:
- Wrote the audio processor which converts the raw audio data received from the web backend into a WAV format, which is then processed into a mel-spectrogram. Optionally the audio processor can split a single audio sample into N evenly sized chunks. This is useful for registration when we want a number of different speech embeddings from a single long utterance when it would be inconvenient for the user to have to stop and start recording the individual samples.
- Wrote the speaker embedding processor, which efficiently performs network inference for our speaker model (ConvNet) using JIT compilation for acceleration.
- Wrote the database schema (written in the Peewee ORM). Specifically, I created the serialization tooling that lets us efficiently store the speaker embeddings (fixed length vectors).
- Developed the system initialization sequence, which performs two critical tasks:
- Loads the internal dataset (our collected set of speech samples from friends), generates the embeddings for these speakers, and adds these speakers to the database (serialize and store their embeddings and relate them to the respective User record).
- Loads the external data by first randomly sampling from a set of valid speech samples and then
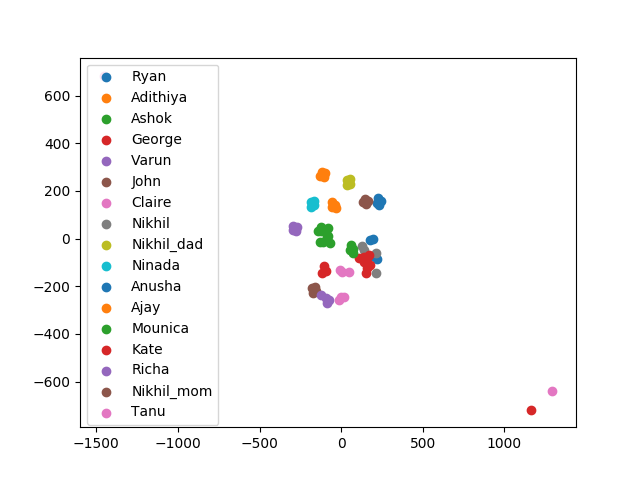
- Helped develop the speaker classification processor with Nikhil. This pipeline learns logistic regression parameters for each speaker added to the database. We encountered a number of challenges to getting this to work. Initially, used dimensionality reduction to visualize both the internal and external embeddings in the database to see how separable the data was. Once we confirmed that it was separable I realized that we needed to hold-out a subset of the data for each speaker in order to find a threshold for each speaker model that achieves minimum EER. After tuning the held-out proportion and sampling process, we achieved decent performance.
- Added a global logging system that aggregates logging info from all of the processors and the database into a single logging file.