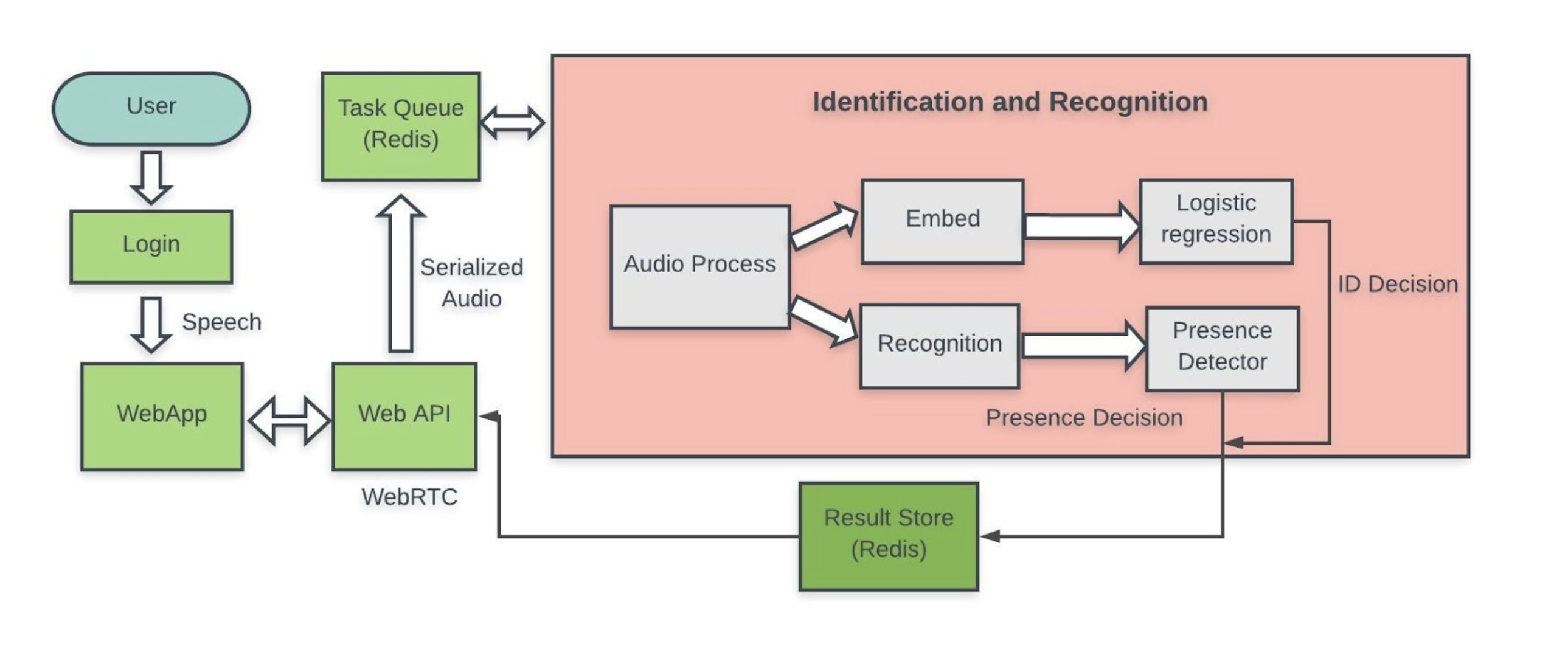
In two weeks of work, we as a team have made significant progress toward our minimum viable product (MVP) that we will demonstrate on April 4. The primary objective is to have the entire system integrated by that time so that we can spend the remainder of our development in optimizing individual components in order to have the system achieve sufficient performance.
The three most significant achievements this week were implementing the speaker classification (logistic regression) module, implementing the bare-bones processor (backend), and finishing a working web application that can accept audio data over the network.
The biggest unknown that we resolved was designing the specifics of the speaker classification system. The entirety of the speaker classification (logistic regression) system was built and tested in the past two weeks. In brief, the system learns a distinct set of logistic regression parameters for each speaker in the database. The motivation for this is twofold. For one, it helps us leverage both internal (from our speaker database) and external (from 3rd party datasets) data to derive a confidence score and threshold tuned to that speaker. Secondly, it is a simple and transparent model with low resource cost to run.
The greatest challenge we face in the next week is integrating the speaker embedding system with the speaker classification system and testing it on our own collected dataset.
Team Member Status
Ryan Brigden
I made progress on both the speaker embedding model and the processor (backend) system these past two weeks, as well as working with Nikhil to develop the speaker classification (logistic regression) training and evaluation process. I also collected 2 minute audio samples from 10 individuals that have been stored with those collected by other team members.
Here are some more specific updates on what I have completed.
Speaker Identification System
While this module is currently the most mature, we have made some more progress on refining the current model. The new features are
- Alternative bidirectional LSTM based model that exploits the sequential structure of the data. Achieved comparable results on Voxceleb to our ConvNet model by reducing the complexity of the original LSTM model described in the prior status report. The benefit of the LSTM model is that it handles variable length sequences more simply and efficiently. Hopefully if this model performs better with refinement we can use it over the ConvNet.
- Enforcing our embeddings to be unit vectors. Our metric for speaker similarity is inverse cosine distance so we decided to normalize the embedding layer activations during testing so that the learned representation of the embedding lies on a unit hypersphere and the embeddings can only differentiate based on the relative angle between one another. In practice this improves the discriminative nature of the embeddings leading to a gain of approximately 2% EER on Voxceleb.
Processor (Backend) System
This past week I built the bare-bones backend system, which we now call the processor to disambiguate it from the web application’s backend. The bare-bones processor:
- Deques a request (JSON) from the Redis requests queue (currently hosted locally) and reads binary audio data the same Redis server using the key from the request.
- Converts the audio to wave format.
- Converts the wave file to a mel-spectrogram using our parameters that we decided in our model development process.
- Stores dummy results back in Redis storage using the same ID passed in the initial request, which web server reads and returns to the user.
Noticeably the system is currently missing the internal “guts” of the processing, although these have all now been implemented independently. This bare-bones system validates that we can successfully queue request information from the web server, pass that data through our inference system, and write a result that the web server can read.
Nikhil Rangarajan
- What did you personally accomplish this week on the project?
Implemented “One vs Rest” Logistic Regression on a sample of utterances from 34 speakers from our VoxCeleb Dataset. Learnt weight parameters for each speaker.

Then tested on our held-out set to see how an utterance performs for our learned parameters.
A probability value is outputted for each class (in this case, probability it belongs to a certain speaker and probability it doesn’t belong to that same speaker).
![]()
After obtaining probability scores for each utterance in our held-out set after testing against our learned Logistic Regression models, we pass these scores into our Equal Error Rate Function to note performance.
![]()
We obtained EER between 0.01% to 10% depending on the speaker. Some speakers’ models performed better than others. We will need to explore this and fine-tune better.
- What deliverables do you hope to complete in the next week?
Tune Parameters in Our CNN as well as Logistic Regression models to see what gives us the most optimal results. Additional we hope to train and obtain the EER and required threshold for speakers outside of our VoxCeleb dataset. We hope to obtain 20-30 recordings from our friends on campus to see how our model performs on internal data.
Richa Ravi
I finished the MVP web application over the past two weeks and can successfully record and push audio to a remote webserver. I have deployed the application to EC2 and have demonstrated that users can record and submit audio given a phrase prompt. Although the application will be used for login in registration, we are already making use of the deployed system to collect data for our own dataset.