

Team Status
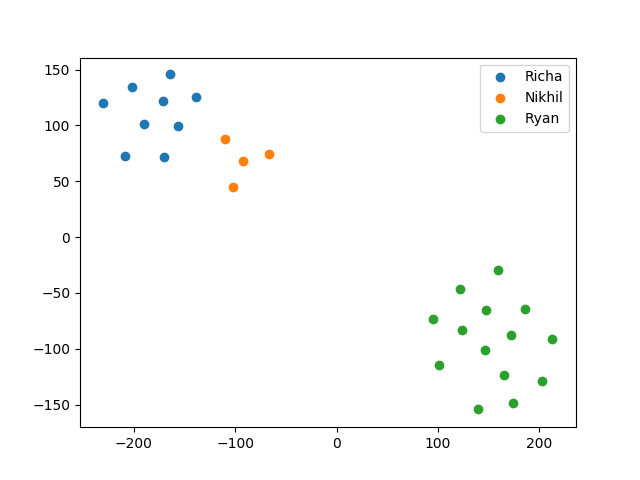
This week we made progress in demonstrating that our speaker verification system learns meaningful discriminative features beyond the dataset it was trained on. To do so, we showed that we can record audio in the browser, process it with our speech pipeline, and generate embeddings from the utterance spectrogram using our ConvNet model. We then used PCA and t-SNE dimensionality reduction techniques to visualize the 512 dimensional speaker embeddings in 2D space.
The main system design change this week was a shift from a KNN one-shot identification model to learning separate logistic regression parameters for each speaker in our database. The reason for doing so is that KNN is that it is difficult to reason about confidence with KNN and also leverage data beyond our systems database. We now plan on training separate logistic regression parameters for each speaker in our database. The logistic regression is a binary classification between a speaker in our database and all other speakers in our database as well as a held out set (our model is not trained on it) from an external dataset. This method allows us to reason about confidences and develop individual thresholds for each speaker (ie threshold that achieves EER on held out data).
Currently the most significant risk to the project so far is integrating the cloud processing system with the web backend. We plan on implementing a skeleton system that passes “dummy” data around this week so that we can verify the concept. Another risk is that we don’t fully understand how our verification metrics on external datasets extend to our system performance. We need to get a baseline system up running as soon as possible (before spring break) so that we can perform this evaluation.
Team Member Status
Nikhil
- A week ago, while extracting the Mel Coefficients and Mel Spectrogram from each voice recording, we were using a bunch of default parameters to do our signal processing (such as the sampling rate of our incoming signal and the number of FFTs to compute). Since the human ear is sensitive to frequencies between 20Hz to 20kHz, we decided to evaluate performance if we changed from the default sampling rate (which was 22050Hz) to 16kHz. There was a significant improvement in our EER rate after making this change. There’s a lot of scope over the next few weeks to adjust numerous parameters and see what gives us the best results.
- Additionally, over the next week, the goal is to implement the one vs all Logistic Regression model on our speaker embedding. The idea is to learn a new set of Logistic Regression weights for each user in our database in order to get a threshold for each speaker vs the rest of the speakers (using our held-out set too)
Ryan
- Adjusted model architecture and added contrastive training to improve our verification performance on the Voxceleb dataset.
- Added logic to process and perform embedding inference on our own speech samples.
- Performed dimensionality reduction on our embeddings to visualize them in 2 dimensions so that we can quickly know if the model is learning meaningful features on our own data.
- Came up with new one-shot identification method using N binary logistic regressions for N users in the database that will give us a way to reason about the confidence of our classifications as well as the ability to leverage data beyond our own database at test time.
Richa
- Worked on converting the webapp into a website that can be used for data collection. I added an input box where a user can enter their name and then when the user clicks the stop recording button the html calls a function from Django views to store the recording along with the users name. To store this data I created a Django model which has two fields – a Filefield to store the audio file and a Charfield to store the name of the user. The database I’m currently using is SQLlite which is the default database for a Django webapp.
- Next week, I want to work on creating the backend for the webapp. This will include setting up an EC2 instance for the webapp which will then queue up tasks on redis and send the individual tasks to another instance which hosts the GPU. Each task will be processed on this instance, which hosts the GPU, and return a probability of the speaker being similar to a speaker on the database (for login) or just a task complete indicator (for register).