For this week, I worked on readying up the stethoscope for the final demo. We all worked together on the final integration portion. We discovered an issue where the sample rate that the Raspberry Pi was recorded in was different from the sample rate that the testing data was. The frequency sample rate was 2000 Hz for the testing data, but the recorded data from the stethoscope was 44.1 kHz. Therefore, once we fixed this issue, importing the audio issue was now in the same format as the dataset. We also had issues where the recorded samples were at different amplitudes than the dataset sound files. Therefore, we added a gain setting on the Raspberry Pi, that amplifies the speaker/heart sound when recording on the stethoscope, so that the amplitudes would match. After fixing both of these, the testing samples on the speaker setup worked well. We also had to hand select some files from the testing dataset, so that we would ensure that it would work for the final demonstration. This is the final week so there are no updates for next week.
Ryan Lee – Week 10 Status Report
Since last week, we have all been working on integrating the ML portion with the Rasberry Pi. Although the code ran well on Ari’s local computer, there were a lot of importing module issues on the Pi. Therefore, this week I had to work on fixing the ALSA audio issues on the Pi to successfully record directly from the stethoscope.
Aside from fixing the import issues on the Pi, I also worked on checking the sensitivity vs specificity on the ML testing algorithm by using a Confusion Matrix. Eri and I initially found that only 65% of our abnormal test sounds were being classified as abnormal, so we decided to use more abnormal heart sounds in the training algorithm because there was previously a lot more normal heart sounds than abnormal in the dataset. After we fixed this, we saw that we were now getting around a 85% true positive rate and 85% true negative rate, which is what our specifications originally aimed for. The overall validation accuracy was also 89%.
For next week, we as a team have to finish the integration portion as well as ensuring that it also works with the speaker using a double-blind experiment.
Ryan Lee – Week 9 Status Report
For this week, our main focus was improving our CNN since in the last few weeks we hit a bump at about 75% accuracy. With improvements in preprocessing it actually decreased the accuracy, so we had to explore other methods. First we added more audio data to train on since we weren’t training on the entire Physionet dataset yet. Also, we played around with the architecture by changing the number of channels in our last two convolutional layers. We are still using in total 5 convolutional layers with a filter size of three for each one, but in the last two convolutional layers, we switched the number of filters from 48 each to 24 and 12 respectively. Once we tested the CNN with these changes, we consistently achieved an accuracy of above 85% as shown by the image below.
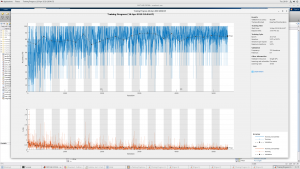
However once we tested again the next day, the CNN was consistently achieving an accuracy of above 80% but not always above 85%. Therefore, more testing has to be done to make the final leap above the 85%. We plan on testing with increasing the total number of filters that occur in each convolutional layer as well as increasing the number of epochs/batch size, although that will increase our training time significantly.
However, since our final demo is coming up, we are putting a hold on improving the CNN and have it communicate with the actual stethoscope to read real time data and classify the sound. Our team is meeting on Sunday to finish this task.
Ryan Lee – Week 8 Status Report
This week I worked on training the CNN with extra preprocessing. First, the audio files were previously trimmed to be 5 seconds long, and also passed through Eri’s Shannon Expansion noise removal algorithm. I then took the spectograms of this new processed audio data and trained my CNN on it. Since the spectograms were now all of the same time frame of 5 seconds, we expected our accuracy to go up. However, the newly trained CNN produced an accuracy of around ~65%, so it was a decrease from the previously trained CNN’s with the same number of audio files. More testing has to be done on how to improve this algorithm.
I was travelling last week and this Sunday-Monday for interviews and Spring Carnival was this weekend, so I could not invest too much time into this project this past week. However, more time will be invested in future weeks to ensure that we reach the desired 85% accuracy by final demo. Next week I want to research LTSM to preprocess the data instead of trimming at a random 5 seconds length.
Ryan Lee – Week 7 Status Report
Earlier this week I worked on sending data from Ari’s stethoscope to my ML algorithm. There were difficulties with this portion because we tried to send in real time data at first. There are no libraries or packages for this in Matlab so it was all experimental. The stethoscope was inputting weird audio data at first, so we switched our method to a more simpler method of just reading audio data from the stethoscope and saving it locally. I then trained my network on the training data and tested our stethoscope data on it to classify. Every time we tested it on our own heartbeat, it was classified as ‘normal’ which is a good sign, but we had no subject with an abnormal heart sound to also test on. Therefore, this is something we must test more thoroughly once Ari has finished making the testing setup with the speaker. I also plotted the input so that the heart sound could be visualized to the viewers during the demo. I was not able to make any improvements to the ML algorithm because I was busy travelling this week, but I will be working on that for this coming week.
For next week, I want to improve the ML portion by adding Eri’s denoising algorithm to the preprocessing. I also want to improve the communication between Matlab and the stethoscope to analyze data directly from the input instead of having to save it locally.
Week 6 Team Report
What are the most significant risks that could jeopardize the success of the project?
The most significant risk in our progress so far is still the CNN. Although we’ve made significant progress, it is still not yet at the 85% goal we set early on. We are hopeful that our improved preprocessing of the data will help improve results because the spectograms were very varied depending on the input length.
How are these risks being managed? What contingency plans are ready?
We have other methods such as LTSM to test in case our current methods do not work well.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
No changes made this week.
Provide an updated schedule if changes have occurred.
No changes made this week.
Ryan Lee – Week 6 Status Report
I once again worked on improving the accuracy of my CNN network this week. I expanded the training set to now include training set A and B versus A from last week. On initial testing, the results actually decreased to a consistent 71% from 79% from last week. When analyzing the testing data more thoroughly, the data varies from 5 seconds to 120 seconds which is a huge variation. This affects the spectograms because when it is computed, I have to specify a segment duration since it compares frequency to time. If the sounds are not as long as the segment duration that portions of the spectogram will be blank. Therefore to improve the data, Eri and I decided to shorten all the sound files to 5 seconds long and test with these results before researching a more complicated LTSM method. We are also planning on using Eri’s Shannon Expansion method to reduce noise in the samples. Upon testing her code, we noticed that some samples weren’t normalized to be centered around the 0-axis, which messed with the calculations of the shannon expansion. Therefore, we also worked on normalizing the data to now be centered around 0. Tests have to be done tomorrow to see if any improvements to accuracy will happen before our mid-semester presentations.
We will be on schedule once we test the newly processed data.
Next week deliverables will depend on the results we get this week, but if improvements have to be made to the preprocessing, we will try and use LTSM’s instead of just segmenting to a strict 5 seconds.
Eri: Week 6 Journal
What did you personally accomplish this week on the project? Give files or photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
One problem we ran into this week was that we used a different dataset from Physionet so we could have more instances to train on. However, this meant that the heart sound files were different lengths, ranging from 5 seconds to 31 seconds. Also there were files that had heart sounds that did not have a central value of zero. To fix this, I cut all the files down to five seconds and normalized all the files so they had a central value of zero, with minimal noise. Ryan then trained the new files to get a higher percentage accuracy than last week.
This week we also used our actual stethoscope to collect Ari’s heart sound, and after putting it through my normalizing and denoising algorithm, it produced the final heart sound signal shown below.

Finally I updated my Gantt chart to reflect on Ryan and me working together from now on.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
My progress is on schedule this week
What deliverables do you hope to complete in the next week?
In the following week we hope to be able to collect heart sounds from our smart stethoscope and test whether it is normal or abnormal using our trained algorithm and get a final analysis. Even if the analysis is incorrect, this is our goal because it is a first step in putting all our different works together.
Week 5 Team Report
What are the most significant risks that could jeopardize the success of the project?
The most significant risk in our progress so far is the CNN not working. We have officially decided to not classify using SVMs anymore and switch to the CNN architecture, so we are investing all our efforts into this method.
How are these risks being managed? What contingency plans are ready?
Since we do not have SVM as a backup method in case CNN does not work, we would have to change our CNN method if the accuracy doesn’t reach the desired accuracy. We will be researching methods of LSTM since the input data from our new data set is varying in time length, so hopefully that will improve our accuracy.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
We have officially decided against using SVM, so we are now only using the block diagram with the CNN architecture.
Provide an updated schedule if changes have occurred.
Eri is now working on CNN with Ryan instead of working with SVMs now.
Ryan Lee – Week 5 Status Report
For this week, I worked on improving the accuracy of my CNN by training it on more data. I found a dataset through PhysioNet/CinC Challenge 2016’s dataset (https://physionet.org/physiobank/database/challenge/2016/), which contains a total of 3,126 heart sound recordings. Previously, there were only a little over a hundred instances of data in my previous dataset, I manually preprocessed the data to split the training/validation/testing set, so this time I had to code python scripts to do this for me since I am handling a larger dataset. I first tested on the training-a folder which contains 409 audio files, so the training/validation/testing set each contains around 136 sounds, which is a huge increase from the prior 60. When training my CNN on this data now, it consistently produced an accuracy of 79% accuracy which is a huge improvement and close to our goal of 85%. Although almost always around 79% accuracy, since the indices are being randomized at initialization, the accuracies reach 29% at times, which definitely has to be fixed. I have to improve the initialization of my CNN to prevent this issue. I also plan on testing it on the full dataset in the coming week. The reason I test on only the A set is because the description wasn’t very clear on the differences between the sets, so I’m not very sure if the audio between set A and set B were taken differently. This is something I definitely have to test with to increase the amount of data I can train my network with. I am currently behind schedule because I had to switch datasets midway through, but I should be on schedule next week once I finish training my network on the entire dataset.