What are the most significant risks that could jeopardize the success of the project?
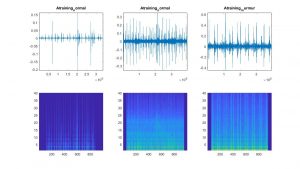
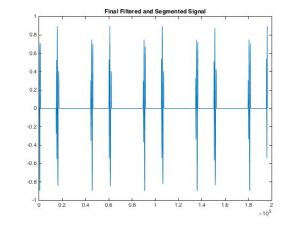
The most significant risk in our progress so far is still the CNN. Although we’ve made significant progress, it is still not yet at the 85% goal we set early on. We are hopeful that our improved preprocessing of the data will help improve results because the spectograms were very varied depending on the input length.
How are these risks being managed? What contingency plans are ready?
We have other methods such as LTSM to test in case our current methods do not work well.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
No changes made this week.
Provide an updated schedule if changes have occurred.
No changes made this week.