
This week, I dove deeper into understanding the CNN-LSTM model and got started working with some code for one implementation of this kind of network for image captioning. I worked through the tutorial on this site:
How to Develop a Deep Learning Caption Generation Model
This tutorial uses images from the Flickr8k dataset. The CNN-LSTM model has 2 parts: the first is a feature extractor, and the second is the sequence model which generates the output description of the image. One important thing that I learned this week while working through this tutorial is about how the sequence model works: it generates the output sequence one word at a time by using a softmax over all words in the vocabulary, and this requires an “input sequence”, which is actually the sequence of previously generated words. Of course, we can upper-bound the length of the total output sequence (the example used 34 words as the bound).
Since the sequence model requires a “previously generated” sequence as input, we also make use of <startseq> and <endseq> tokens. Here is the example given in the article of how the CNN-LSTM would generate the description for an image of a girl:
![]()
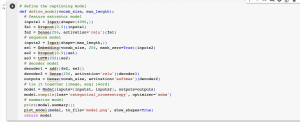
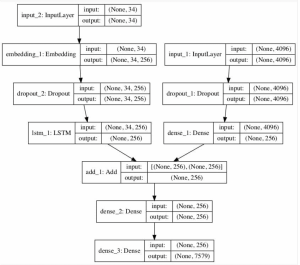
Here is a portion of the full code, which encodes the architecture of the CNN-LSTM model, as well as a diagram which is provided in the article which helped me to better understand the layers in the model. I need to do a little more research into how the feature extractor and the sequence processor are combined (the last few layers where the two branches join) using a decoder, as I didn’t fully understand the purpose of this when I read this article. This is one of the things I will be looking into next week.
I wasn’t able to train the model and test any sample images this week (the model has to train for a while and given the number of images, it would take a lot of GPU power, and my quota for this week has been exhausted) – however, this is something else I hope to do next week.
I am a little behind schedule as I was hoping to have a more comprehensive grasp of the CNN-LSTM as well as have tried out the standard version of the model (without the necessary tweaks for our use case) by this time; however, I am confident that I will be able to catch up next week, as next week is also devoted to working on the graph description model. In terms of actions I will take, I will make sure to work on the graph description model both during class-time as well as on Tuesday and Thursday to catch up.
For next week, I hope to have the test version of CNN-LSTM for image captioning fully working with some results on sample images from the Flickr8k dataset, as well as determine how to do the labelling for our gathered/generated graph data.