I’m happy to say that I accomplished everything I set as my goals last week and in fact am ahead of schedule at the moment. I was able to port my data over to the ECE machines and finish training (with about a 13x speedup) on there. I solidified both the weights and the architecture for the value network. I then utilized the design space exploration from the value network to solidify the architecture for the policy network. Finally, I began testing the MCTS process locally, and once I am sure it fully works, I will port it over to continue on the ECE machines as well.
Starting off with the relocation to the ECE machines, I was able to move 13 GB of training data (more than 3.5 million data points) over to my ECE AFS so I could train the value network remotely. This had the added advantage of speeding up training time by a factor of about 13, meaning I had more freedom with the network architecture. The architecture I ended up settling on took about 13 minutes per epoch on the ECE machine, meaning it would have taken ~170 minutes per epoch locally which obviously would have been impossible as even a lower bound of 50 epoch would have taken about a week.
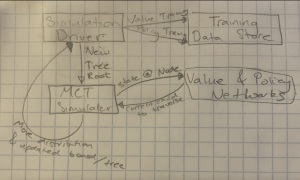
Secondly, my finalized architecture is shown below in listed form,

As you can see, there are three parallel convolution towers, with kernel sizes of 3, 5, and 7, which help the network derive trends in different sized subsections of the board. Each tower than has a flattening layers, and a fully-connected dense layer. These layers are concatenated together with the other towers, giving us a singular data-stream that passes through successive dense and dropout layers to prevent overfitting, culminating in a singular sigmoid output node, which provides the positional evaluation. This network was trained on 3.5 million data points, pulled evenly from over 60,000 expert level go matches. After training, the network was able to identify the winner of a game from a position 94.98% of the time, with a binary cross-entropic loss of .0886. This exceeded my expectations, especially considering many of the data points come from the opening of matches, where it is considerably harder to predict the winner as not many stones have been placed.
Using my design space exploration for the value network, I was able to solidify an initial architecture for the policy network, which will have the same convolutional towers, only differing in the amount of nodes in the post-concatenation dense layers, and the output form of a length 362 vector.
I have started testing MCTS locally, with success, once I am convinced everything works as expected I will port over to the ECE machines to continue generating training data for the policy network, in addition to tuning the value network. Fortunately, as for the first iteration of MCTS the policy network essentially evaluates all moves equally, the training data will be valid for further training, even if the architecture for the policy network needs to be changed.
In the next week, I plan to move MCTS over to the ECE machines and complete at least one iteration of the (generate training data via MCTS, tune value network and train policy network, repeat) cycle.
ABET: For the overall strength of the Go engine, we plan to test it by simply having it play against different Go models of known strength, found on the internet. This will allow us to quantitatively evaluate its performance. However, the Go engine is made of 2 parts, the value and the policy networks. Training performance gives me an inkling into how these networks are working, but even with “good” results, I still test manually to make sure the models are performing as expected. Examples of this include walking through expert games to see how the evaluations change over time, and measuring against custom-designed positions (some of which were shown in the interim demo).