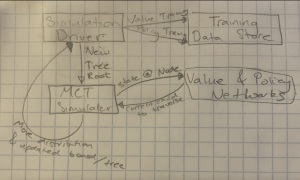
I am happy to say that not only is the engine fully ready for demo multiple days ahead of time, but also that the improvements from the MCTS training run in the past week were much larger than I originally anticipated.
Before switching to 9×9 board, the original (initial trained) version of the policy network had just above 1% accuracy. While that sounds extremely low, it in fact meant the policy network identified the “best” move in the position 4 time more often than randomly guessing (with 362 options), plus, there is a much higher chance that the “best” move is in its top 5 or 10 suggestions.
The second version, trained exclusively on 9×9 data generated from my MCTS runs, had an accuracy of around 9%, which represents performance about 8 times better than randomly guessing, as for 9×9 there are only 82 possible selections, not 362. With each increase in accuracy, the expansion factor of the tree search (i.e. how many candidate moves are considered from each node) can be reduced, as the probability that the best moves are some of the stronger recommendations of the policy network is higher.
Finally, with the third version, I was expecting something around 20% accuracy, however, much to my surprise the measured accuracy (on separated validation data) was just over 84%. Though this is probably not due to overtraining (due to the network architecture having multiple systems to prevent this, and considering the performance on “unseen” validation data), I suspect some of this marked increase is due to the policy network essentially predicting the value network’s response, with an extra layer of abstraction. That is, if the policy network identifies what traits in a position the value network “likes”, its suggestions will line up more evenly with the value network’s evaluations. However, this is indeed the point of MCTS, as assuming a degree of accuracy in the value network (which I think is safe due to the abundance of training data and past performance), the policy network’s job is to identify candidate moves that may or may not result in the best possible positions. Thus fewer candidate moves need to be explored, and deeper, more accurate simulations can be run in the same amount of time.
This 84% model is the policy network that will be utilized by our engine during demo, however, I am starting a simulation run tonight, whose results (if better), will be used in our final report. The engine is fully integrated onto the web app backend, and works exactly as intended.
Added note, the code for the engine itself (i.e. lacking the code for simulation which can be found on the Github I linked earlier in the semester) can be found here.