
As I mentioned in my previous status report, my goal for this week was to finish custom loss function implementation, then work towards getting the MCTS training data generation working, given that the framework was already there.
With regard to the former of the two goals, that work is all complete. I had actually misunderstood my needs, I don’t actually need a custom loss function, as the two networks are trained on mean-squared error (MSE) and binary cross-entropic loss (BCEL). Nevertheless, I have built the framework for the training of the two networks (Policy & Value), in addition to the data generation section of the MCTS code (where the board states and MCTS visit counts are stored as npz files.
With regard to the latter, there was a bit more involved than I originally anticipated. While I have all the Go gameplay functionality for training built, I am specifically not finished for the code for the MCTS expansion phase, where the leaf to expand is determined and children are generated. That being said, I have built out all other functionality, and am working to finish the expand() function by Monday in order to stay ahead of schedule. A brief schematic of the training structure is shown below.
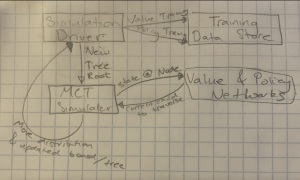
Once the expand() function is finished, the next step is finding a dataset of expert go matches to use as training data for the value network pre-simulation. While this is not strictly necessary, and self-play could be used for this, giving the value network a strong foundation with expert-generated data improves the quality and function of the initial training data much faster. My goal is to have expand() finished and this dataset found by the end of the week. If that goes according to plan, I would be able to commence network training and MCTS generation immediately afterwards.
To accomplish my task, I had and will have to learn a few new tools. While not really a tool, I had to fully understand Monte Carlo Tree Search in order to program it correctly. More presciently, I have never used PyTorch before, or worked with Convolutional Neural Networks. While I have worked with similar technologies (fully connected deep neural networks and TensorFlow) I have had to do a lot of research into how to most effectively utilize them.
