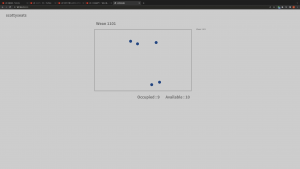
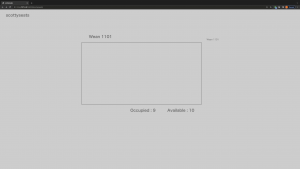
The basic framework has been built, creating a full pipeline image -> yolov5 -> outputs coordinates and size information in txt file (yolov5 default output format) -> the server parses through the file -> data post-processing adjusting the perspective -> display on the website interface
The current server works as whenever the front end sends a post request, the server parses through the output file. This will be changed to whenever the front end sends an http request, the server responds with the information of the room it’s requesting in a later update with the completion of the database, fulfilling the purpose of scaling the project to multiple rooms.
Additionally, the distance threshold will be applied in the later update to calculate availability.
This report also covers the week before fall break.
Before fall break, I spent most of my time working on the design report. I was in charge of writing up the use-case requirements, design requirements, hardware design studies, bill of materials, summary, testing, verification and validation and adding relevant implementation information. Writing these various parts of the report took 6+ hours as we were iterating and reworking various parts along the way.
This week, my main goals were to look into preprocessing for the model, to decide the type of data to collect and to start data collection. This changed a bit after Monday once the question around image subtraction as an alternative to deep learning-based object detection came up. I didn’t have much knowledge of non-deep learning methods, so I switched gears a bit to research more into it. I found that what we are looking for is background subtraction and looked into different feature detection methods and classification models we could use in tandem with it.
I went through a textbook for a bit to learn more about non-deep learning based object detection and some comparative studies as well. I mainly found HOG, SIFT, SURF, ORB and BRISK. So far I am finding that ORB and BRISK seem to have a good tradeoff between computational complexity and being able to pick up features in an image. Out of classification models to run on the feature extraction output, Naive Bayes and SVM, along with a few others are popular. As far as data collection, I found a dataset we can use preliminarily to train the model before moving into using footage of the study space itself.
With some midterms and coming up, I didn’t get to work as much to get a model of one of these systems up and running, so I’ll be getting to that next week along with starting data collection of the study space itself.
This week, I worked on setting up the Jetson Nano. I was able to successfully flash the microSD, connect the Jetson to my computer and complete the headless setup. I was quite busy this week, so I did not manage to complete the camera setup for the Nano. I plan to work on that this coming week as I have more time. I also decided what additional purchases we will need for the Nano like ethernet cables and researched and decided on a WIFI dongle that is compatible with the Jetson.
The implementation of our project did not change much this week. We worked on our individual parts this week. Integration is definitely a worry for the team so we are going to try and get some initial integration done by next week. We have switched to the Jetson Nano and was able to bring it up. After getting some questions from our presentation this week, we researched more into image subtraction and discussed our motivation for using hardware versus AWS. This was a slower week for our team as we all had other deadlines.
I was the presenter this week for design review, so that was part of my focus. During the preparation, we were able to determine the details of implementation. This includes determining whether or not to use overhead cameras versus side cameras, as overhead cameras are easier to transform into coordinates but might not be accurate in terms of cv algorithm, while side cameras might be more accurate in recognizing seats, but really hard to translate into 2d maps, and we decided on the latter, as accuracy is the most important. For this week, my main progress if building up the environment for the webapp, and finishing front end, and part of the back end.
I expect to finish and have some psuedo map showing for next week, and I expect to finish displaying seats and tables assuming we have the coordinate data soon. Further work after this would be assisting Mehar with CV algorithm and data processing.
This past week I focused on implementing and testing various neural network-based object detection architectures and working on the design documentation. My goals this week were to pull up a fully functional Faster R-CNN model to test with, have the rough CV pipeline laid out and study Open CV further.
The bulk of my time was spent pulling up the models and performing preliminary testing. In my research, I found a promising Object Detection library – Facebook Detectron 2 with support for various Faster R-CNN architectures. Briefly, Mask R-CNN became a consideration since the object masks could help with object occlusion for our use case (ie table covering chairs), but I ultimately decided against it as Faster R-CNN would work sufficiently and the object masks would add significant overhead in labeling training data.
I tested a number of Faster R-CNN architectures on some test images we took after class Monday. Ultimately, I found the larger Faster R-CNN – Reset 101 architectures had higher accuracy and were able to detect more objects. During this testing, I tested out Ultralytics Yolov5. Yolov5 surprisingly performed similarly to the larger Faster R-CNN architectures despite the smaller model size and faster computation time. For this reason I decided on working with the Yolov5 instead of the Faster R-CNN.
Ultralytics Yolov5 on iPhone ImageDetectron’s Faster R-CNN w:ResNet-50 on iPhone ImageDetectron’s Faster R-CNN w:Resnet 101on iPhone ImageDetectron’s Faster R-CNN w:ResNeXt-101-32x8d on iPhone Image
From there, I spent some time determining the rough overall CV pipeline – discussing with Chen how to translate the object detection output into the seat occupation data. I added this final pipeline to the Design Review powerpoint slides.
Design Review Presentation Computer Vision
I didn’t research as much about Open CV – I fell sick during the week so I lost some time that I might have used to research Open CV. Based on what I was finding with model testing though, I’ve found I mainly need to look into noise reduction, contrast increase and some potential image segmentation for preprocessing.
Next week, I’ll research the Open CV needed for the image preprocessing layers to catch up in that area and will start putting together the image preprocessing with the model. Besides that, next week’s goals include deciding what training data to collect and starting to collect training data using the camera setup.
I ordered the parts late Sunday night, and was able to pick them up during the week. This week a lot of our energy was spent on doing the design presentation. I was in charge of the hardware implementation slide, the testing and validation slides and the implementation plans. I also redefined the use-case requirements. This took a while as I needed to figure out how we were going to implement some of our testing and think of a new test case for one of our use-case requirements. I attempted to get the Jetson TX2 up and running but I was not able to download the SDK onto the ECE machines due to some user privileges. I also realized that the TX2 was too large and would be difficult to mount. After doing some research, I realized that the Nano can fit most of our requirements but we would have to switch to USB cameras. I did a trade study and looked at the average accuracy and FPS on some of the other options like using smaller YOLO framework, using a Raspberry Pi and support for multiple cameras. The setup for the nano also has a simpler headless setup so hopefully I can get things moving this week. I also reviewed all of our feedback, and gave each person on the team their relevant feedback.
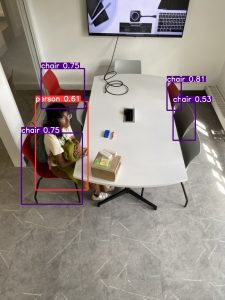
The implementation of our project changed slightly again this week and some more details were figured out. Instead of using a NVIDIA Jetson TX2, we will use a NVIDIA Jetson Nano. The TX2 was much larger in its form factor than we expected and the Nano has enough compute power for our use case. We have also decided on using YOLOv5 for object detection after doing some testing on preliminary images. There is some risk that we won’t be able to detect chairs when people are sitting on them, and in this case we may just ignore those objects and only identify empty chairs as it still will meet our use case requirements. Identifying chairs which are occluded also may be difficult and we may try and preprocess the image by filtering by known colors of chairs in the room. We have changed the delegation of tasks slightly, and Chen (instead of Mehar) will be working on counting the number of chairs and interpolating the middle of each of the bounding boxes outputted from Yolov5.
Here is a picture of Yolov5 working on an image we took of a study room we hope to use for MVP:
I am leading the hardware component of our project. Since last week, our hardware implementation has changed. After discussion with the professors, they thought it would be out of scope to implement the project with a tool I’m unfamiliar with. I spent many hours this week researching alternatives and settled on using the NVIDIA Jetson TX2. I additionally decided on the cameras we will be using for the project after researching various communication protocols that the Jetson supports. Additionally, I helped out on making and revising the slide deck before our proposal presentation. The progress is on schedule but the schedule needs to be revised as we are using a GPU instead of an FPGA. By next week, I hope to have reserved and received they necessary hardware components and be able to capture a live video stream and display it.