
Model Finalization
Since Thanksgiving break, having finally established a workflow for testing trained models against a large dataset, I was able to measure my model and tune hyperparameters based on the results. However, my measured results were shockingly poor compared to the reference pytorch implementation I was working with online. Despite this, I made efforts to keep training models by adjusting learning rate, dataset partitioning ratio (training/validation/testing), and network depth. I also retrained the reference implementation using braille labels rather than the English alphabet. Comparing results from 11 AWS-trained models using various parameters with this “fixed” reference implementation, it was clear that I was doing something wrong.
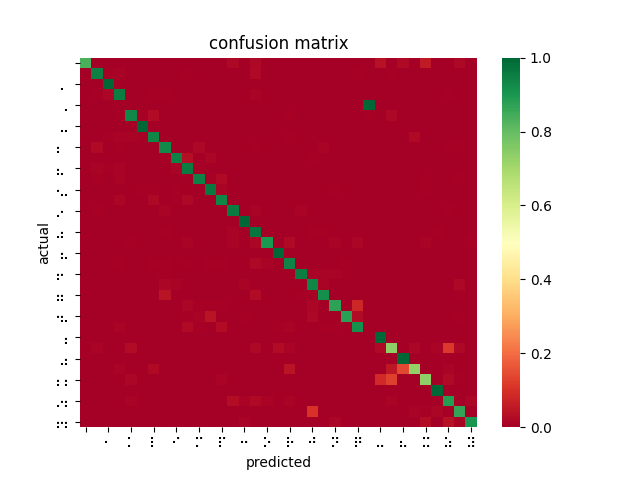
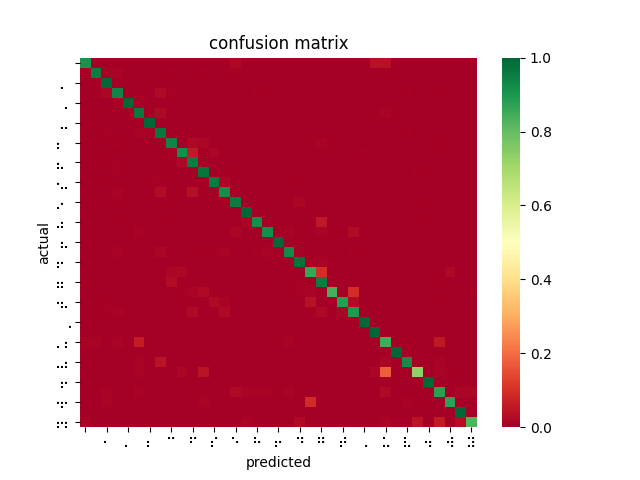
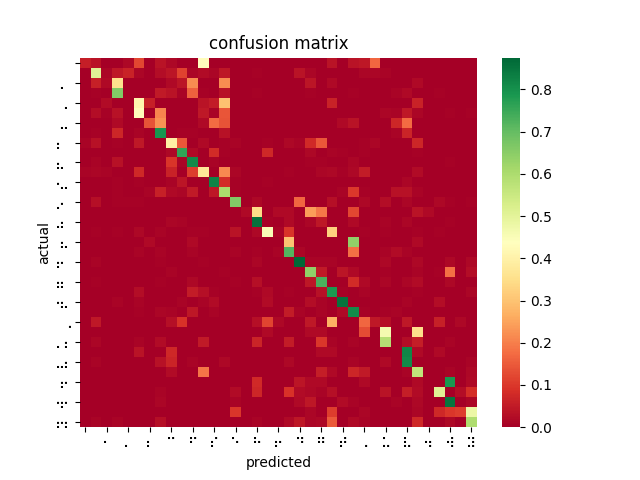
After poring over my code and re-examining the online documentation, I discovered that SageMaker’s image_shape parameter does not resize images as I was expecting and had been doing for inferences — instead, it performs a center crop if the input image is larger than the image_shape parameter. In fact, SageMaker offers no built-in function for resizing dataset images for input. This explains why braille symbols with more white space performed less favorably to denser braille symbols, and also why the model took longer to converge than I had seen described in related OCR papers. Modifying my testing harness to center crop rather than reshape, the models performed much better. However, it is not feasible to center crop all inputs since this would mean losing a lot of relevant data and likely using incorrect landmarks to overfit the classification problem. While wasting so much time and computation on invalid models was disappointing, I was able to upload a new dataset that was converted to 28×28 beforehand, and retrain a ResNet-18 on 85% of the dataset, yielding 99% accuracy on the dataset and 84% accuracy on the filtered dataset.
This is a far better result and greatly outperforms the reference implementation even when being trained on fewer images, as I had originally expected. I then performed 4-fold cross validation (trained 4 models on 75% of the dataset, each with an different “hold-out” set to test against). The average accuracy across all four trained models was 99.84%. This implies that the ResNet-18 model is learning and predicting rather than overfitting to its training set.
I also trained models using four different datasets/approaches: the original 20,000 image dataset; a pre-processed version of the original dataset (run through Jay’s filters); aeye’s curated dataset (embossed braille only); and transfer learning on a model that was previously trained on ImageNet.
Finally, I chose the two best models from the above testing and trained incrementally using the pre-processed/filtered dataset as a validation step to tailor it to our software stack. This greatly improved performance on a small batch of test crops provided to me by Jay.
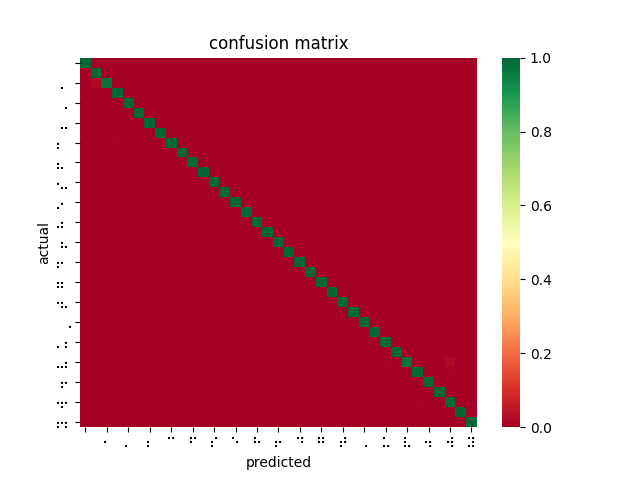
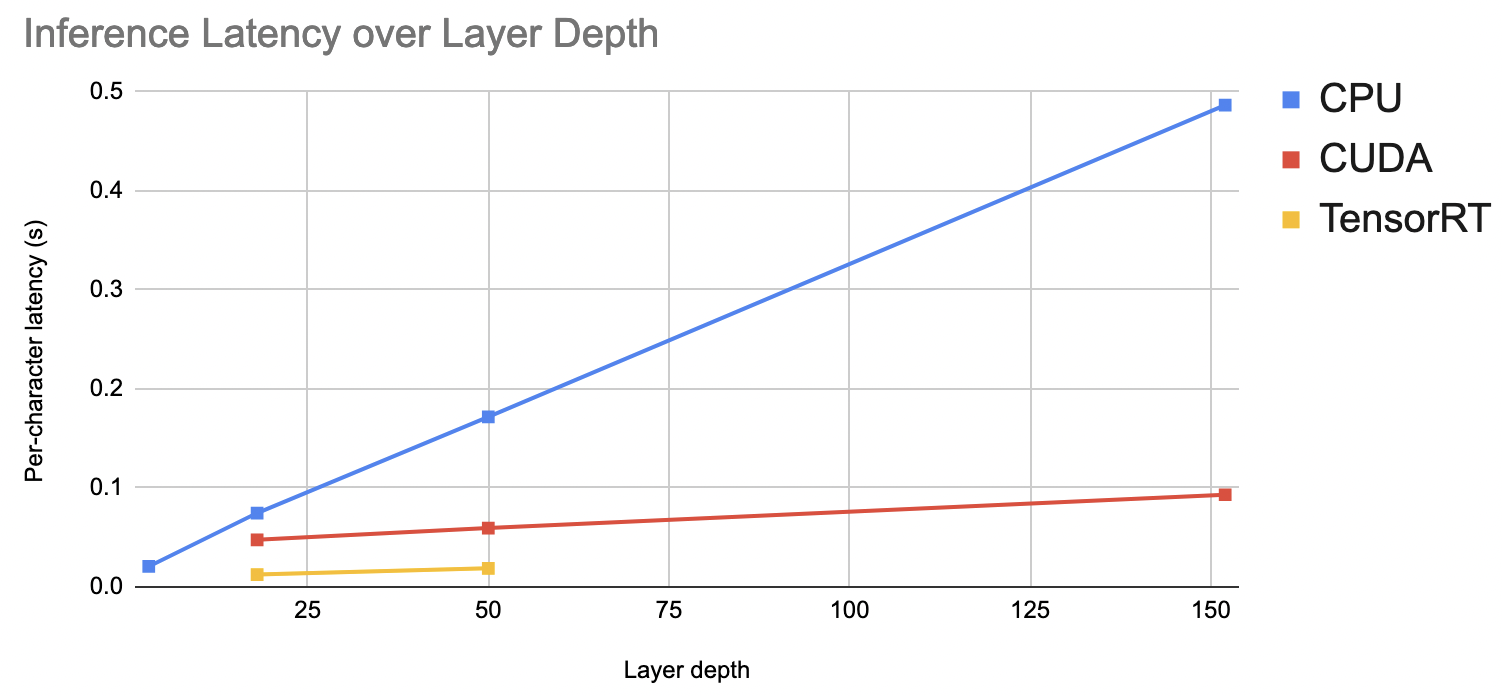
Finally, I was able to measure average per-character latency for a subset of models by running inferences on the Jetson Nano over a subset of the dataset, then averaging the total runtime. It became clear that layer depth was linearly related to per-character latency, even when increasing the number of images per inference. This is accelerated by using parallel platforms such as CUDA or TensorRT. As a result, our ResNet-18 on TensorRT managed to outperform the 3 convolutional block pretrained model on CPU (ResNet-152 failed due to lack of memory on the Jetson Nano).
Hardware
I was able to solder together the button trigger and program GPIO polling fairly quickly using a NVIDIA-provided embedded Jetson library. Integrating this function with capturing an image from a connected camera was also helped by third party code provided by JetsonHacks. I am also working on setting up the Nano such that we do not need a monitor to start our software stack. So far, I have been able to setup X11 forwarding and things seem to be working.
In addition, I have started setting up the AGX Xavier to gauge how much of a performance boost its hardware provides, and whether that’s worth the tradeoff in power efficiency and weight (since we’ve pivoted to a stationary device, this may not be as much of a concern). Importantly, we’ve measured that a given page has approximately 200-300 characters. At the current latency, this would amount to 2.5s, which exceeds our latency requirement (however, our latency requirement did assume each capture would contain 10 words per frame, which amounts to far fewer than 200 characters). I am, however, running into issues getting TensorRT working on the Xavier. It’s times like these I regret not thoroughly documenting every troubleshooting moment I run into.
Cropping Experiments
Having selected more-or-less a final model pending measurement, I was able to spend some time this week tinkering with other ideas for how we would “live interpret”/more reliably identify and crop braille. I began labeling a dataset for training YOLOv5 for braille character object detection, but given the number of characters per image, manual labeling did not produce enough data to reliably train a model.
While searching for solutions, I came across Ilya G. Ovodov‘s paper for using a modified RetinaNet for braille detection, as well as its accompanying open-source dataset/codebase. The program is able to detect and classify braille from an image fairly well. From this, I was able to adapt a function for cropping braille out of an image, then ran the cropped images through my classification model. The result was comparable to the RetinaNet being used alone.



AngelinaReader provides a rough training harness for creating a new model. It also references two datasets of 200+ training/validation images, combined. After making some modifications to address bugs introduced by package updates since the last commit and to change the training harness to classify all braille characters under a generalized class, I was able to set up an AWS EC2 machine to train a new RetinaNet for detecting and cropping Braille. Current attempts to train my own RetinaNet are somewhat successful, though the model seems to have trouble generalizing all braille characters into a single object class.


I trained two networks, one on the AngelinaDataset alone, and one on a combination of the AngelinaDataset and DSBI (double-sided braille image) dataset. After 500 epochs, I performed the opposite of Ovodov’s suggested method in the paper and moved the character classification contribution to 0 (we are generalizing braille characters) and trained the model for a further 3000 epochs. However, both implementations failed when given scaled images, unlike AngelinaReader’s pretrained model.


As a result, with so little time and having run out of AWS credits, we are considering adapting the pre-trained model for our pipeline (pending testing on the Jetson) and leaving room for fine tuning/training our own models in the future.