
Kevin’s Status Report for 12/10/22
This week started with final presentations, for which I prepared slide content and updated graphics:
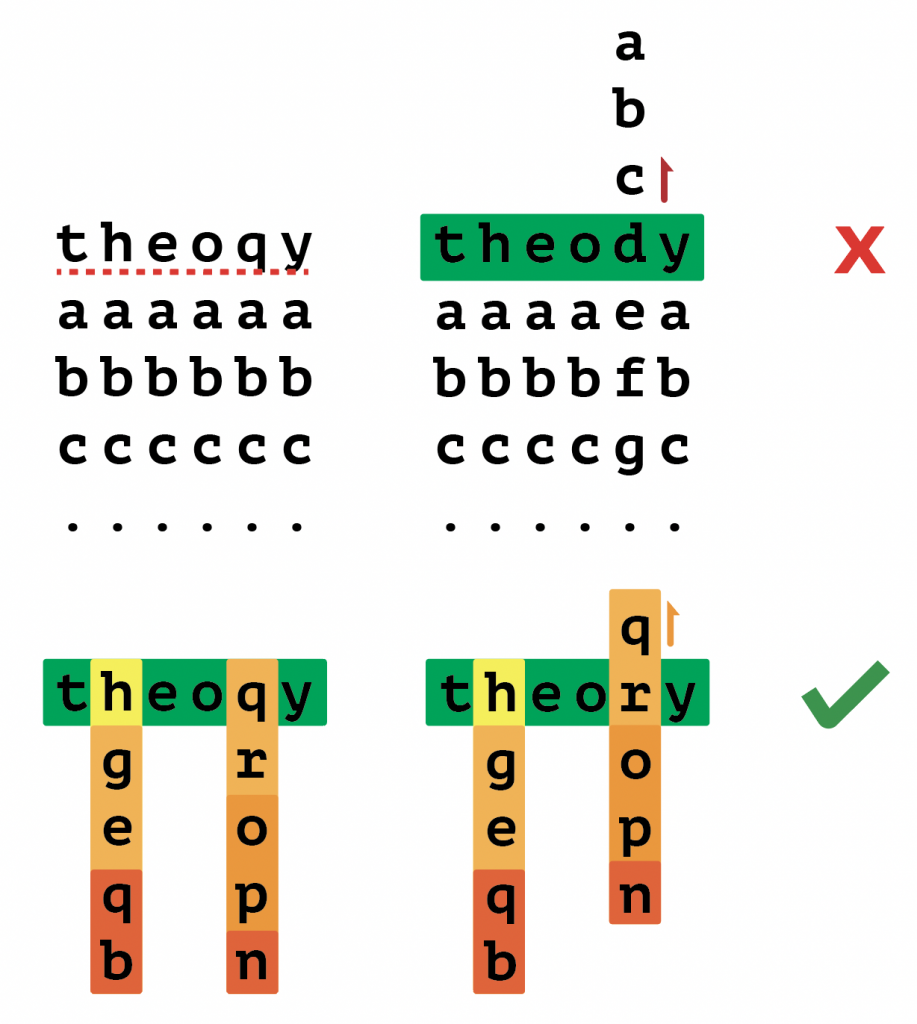
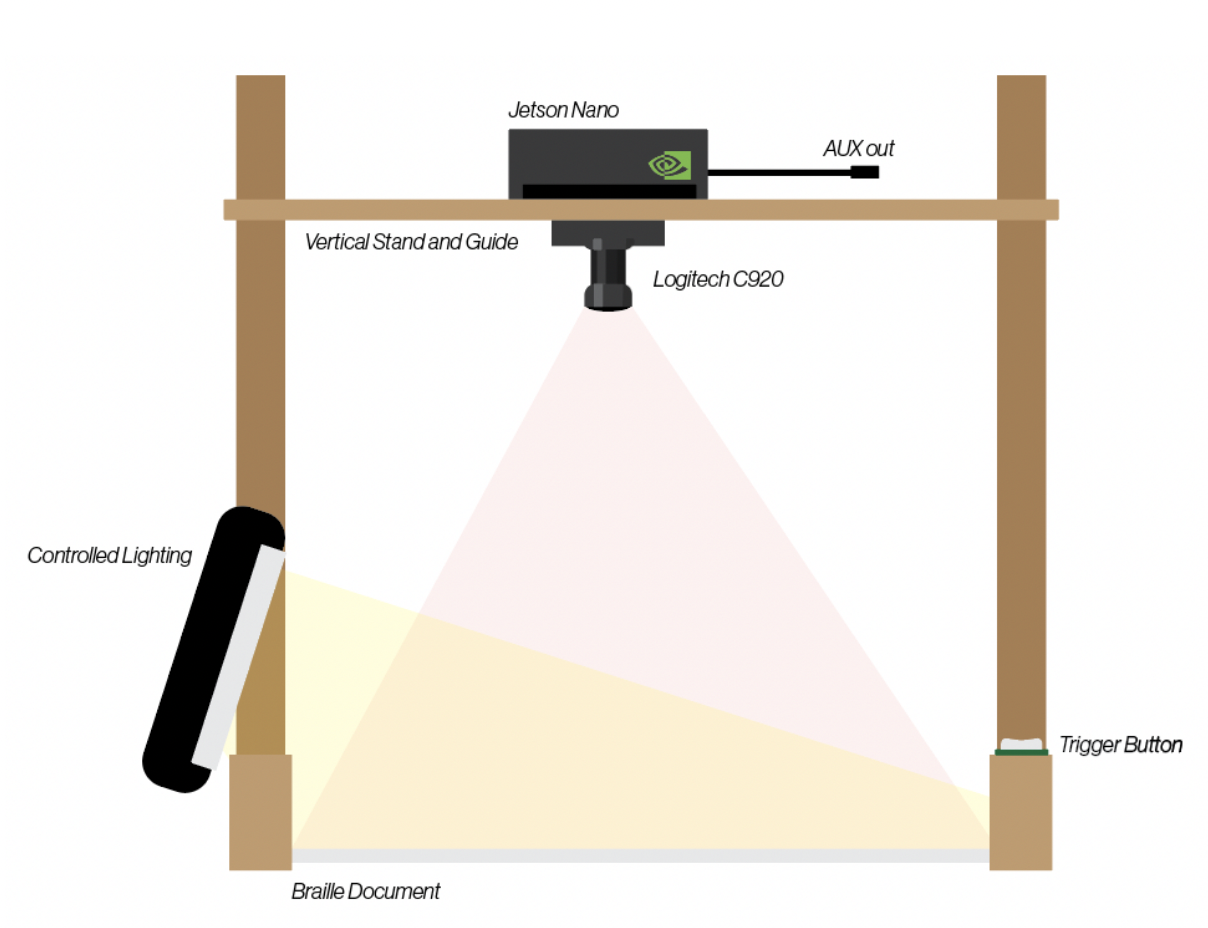
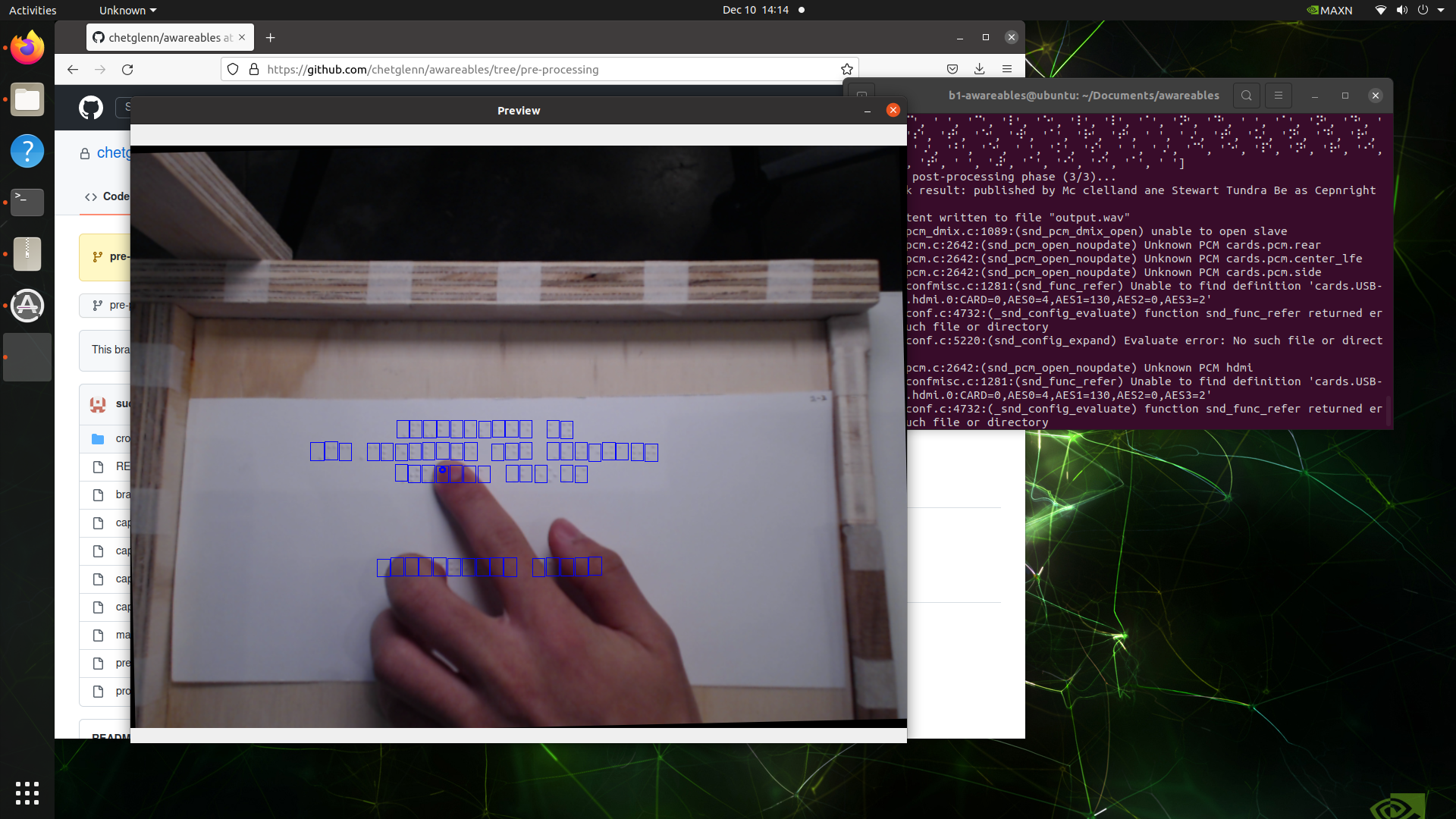
Following presentations, I continued to work on integration and was able to put all our software parts together and verify functionality on the AGX Xavier.
AGX Xavier
This week, I was able to get TensorRT working on the AGX Xavier by re-installing the correct distribution of onnxruntime from NVIDIA’s pre-built Jetson Zoo. I was also able to install drivers which enabled us to use a USB Wi-Fi dongle instead of being tethered by Ethernet. Once the Xavier was set up, I was able to measure inference performance for my classification dataset:
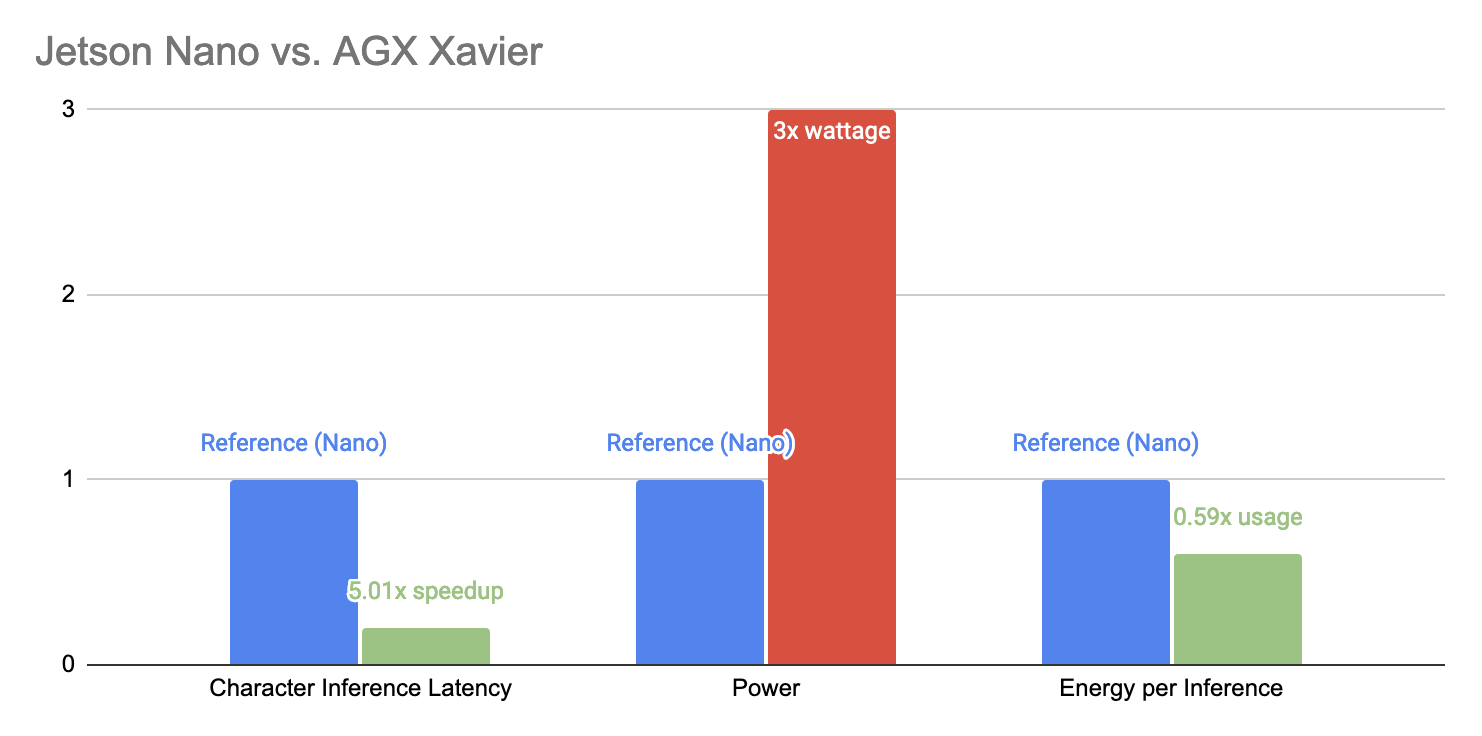
It quickly became clear that Xavier had a huge performance advantage over the Nano, and given our new stationary rescope, it seemed reasonable to pivot to the Xavier platform. Crucially, the Xavier provided more than 7x speedup over the Nano when running inferences with TensorRT. This meant that we could translate 625 characters in one second’s latency – more than 100 words – far exceeding our requirements. Combined with only 3x the maximum power draw, we felt that the trade-off favored the Xavier.
Integrating software subsystems was fairly straightforward once again, allowing me to perform some informal tests on the entire system. Using the modified AngelinaReader to perform real-time crops, we were able to achieve 3-5s latency from capture-to-read. Meanwhile, our own hardcoded crops / preprocessing pipeline was able to reach under 2s of latency, as we had hoped.
Experimental Feature: Finger Cursor
Because I had some extra time this week, I decided to implement an idea I had to address some of the ethical concerns that were raised regarding our project. Specifically, that users will become overreliant on the device and neglect learning braille on their own. To combat this, I implemented an experimental feature that allows the user to read character by character at their own pace as if they are reading the braille themselves.
Combining the bounding boxes I can extract from AngelinaReader and Google’s MediaPipe hand pose estimation model, I was able to prototype a feature that we can use during demo which allows users to learn braille characters as they move their fingers over them.
Using the live feed from the webcam, we can detect when the tip of a user’s index finger is within the bounding box of a character and read the associated predictions from the classification subsystem out loud. This represents a quick usability prototype to demonstrate the educational value of our solution.
Team Status Report for 12/03/22
What are the most significant risks that could jeopardize the success of the project?
- Pre-Processing: Currently, pre-processing has been fully implemented to its original scope.
- Classification: Classification has been able to achieve 99.8% accuracy on the dataset it was trained on (using a 85% training set, 5% validation set). One risk is that the model requires on average 0.0125s per character, but the average page of braille contains ~200 characters. This amounts to 2.5s of latency, which breaches our latency requirement. However, this requirement was written on the assumption that each image would have around 10 words (~60 characters), in which case latency would be around 0.8s.
- Post-Processing: The overall complexity of spellchecking is very vast, and part of the many tradeoffs that we have had to make for this project is the complexity v. efficiency dedication, as well as setting realistic expectations for the project in the time we are allocated. The main risk in this consideration would be oversimplifying in a way that might overlook certain errors that could put our final output at risk.
- Integration: The majority of our pipeline has been integrated on the Jetson Nano. As we have communicated well between members, calls between phases are working as expected. We have yet to measure the latency of the integrated software stack.
How are these risks being managed?
- Pre-Processing: Further accuracy adjustments are handled in the post-processing pipeline.
- Classification: We are experimenting with migrating back to the AGX Xavier, given our rescoping (below). This could give us a boost in performance such that even wordier pages can be translated under our latency requirement. Another option would be to experiment with making the input layer wider. Right now, our model accepts 10 characters at a time. It is unclear how sensitive latency is to this parameter.
- Post-Processing: One of the main ways to mitigate risks in this aspect is through thorough testing and analysis of results. By sending different forms of data through my pipeline specifically, I am seeing how the algorithm reacts to specific errors.
What contingency plans are ready?
- Classification: If we are unable to meet requirements for latency, we have a plan in place to move to AGX Xavier. The codebase has been tested and verified to be working as expected on the platform.
- Post-Processing: At this point there are no necessary contingency plans with how everything is coming together.
- Integration: If the latency of the integrated software stack exceeds our requirements, we are able to give ourselves more headroom by moving to the AGX Xavier. This was part of the plan early in the project, since we were not able to use the Xavier in the beginning of the semester.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
Based on our current progress, we have decided to re-scope the final design of our product to be more in line with our initial testing rig design. This would make our project a stationary appliance that would be fixed to a frame for public/educational use in libraries or classrooms.
Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
This change was necessary because we felt that the full wearable product would be too complex for processing, as well as a big push in terms of the time that we have left. While less flexible, we believe that this design is also more usable for the end user, since the user does not need to gauge how far they need to put the document from the camera.
Provide an updated schedule if changes have occurred.
Based on the changes made, we have extended integration testing and revisions until the public demo, giving us time to make sure our pipeline integrates as expected.
How have you rescoped from your original intention?
As mentioned above, we have decided to re-scope the final design of our product to be a stationary appliance, giving us control over distance and lighting. This setup was more favorable to our current progress and allows us to meet the majority of our requirements and make a better final demo without rushing major changes.
Kevin’s Status Report for 12/03/22
Model Finalization
Since Thanksgiving break, having finally established a workflow for testing trained models against a large dataset, I was able to measure my model and tune hyperparameters based on the results. However, my measured results were shockingly poor compared to the reference pytorch implementation I was working with online. Despite this, I made efforts to keep training models by adjusting learning rate, dataset partitioning ratio (training/validation/testing), and network depth. I also retrained the reference implementation using braille labels rather than the English alphabet. Comparing results from 11 AWS-trained models using various parameters with this “fixed” reference implementation, it was clear that I was doing something wrong.
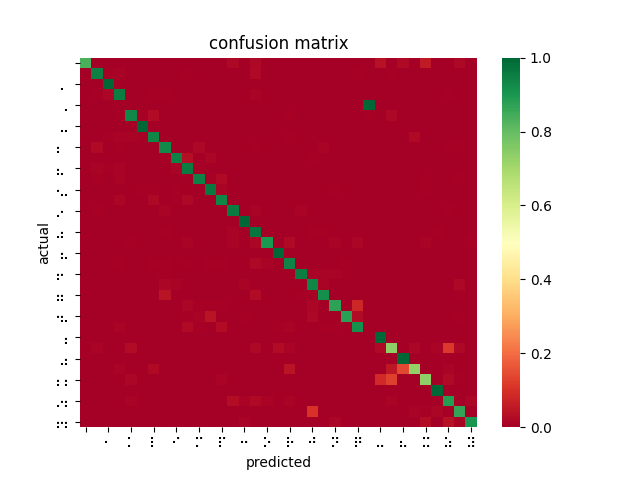
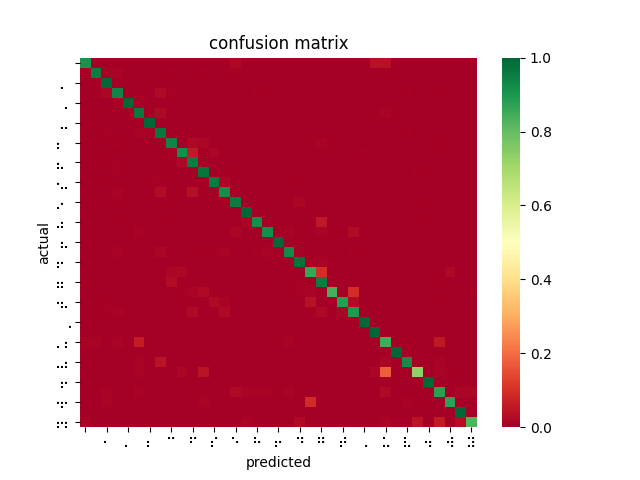
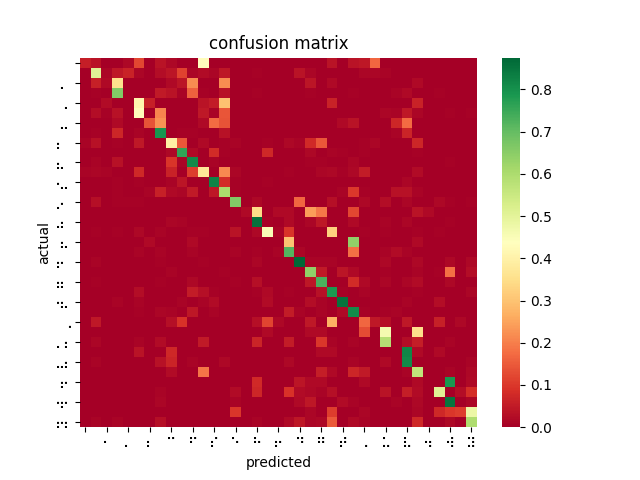
After poring over my code and re-examining the online documentation, I discovered that SageMaker’s image_shape parameter does not resize images as I was expecting and had been doing for inferences — instead, it performs a center crop if the input image is larger than the image_shape parameter. In fact, SageMaker offers no built-in function for resizing dataset images for input. This explains why braille symbols with more white space performed less favorably to denser braille symbols, and also why the model took longer to converge than I had seen described in related OCR papers. Modifying my testing harness to center crop rather than reshape, the models performed much better. However, it is not feasible to center crop all inputs since this would mean losing a lot of relevant data and likely using incorrect landmarks to overfit the classification problem. While wasting so much time and computation on invalid models was disappointing, I was able to upload a new dataset that was converted to 28×28 beforehand, and retrain a ResNet-18 on 85% of the dataset, yielding 99% accuracy on the dataset and 84% accuracy on the filtered dataset.
This is a far better result and greatly outperforms the reference implementation even when being trained on fewer images, as I had originally expected. I then performed 4-fold cross validation (trained 4 models on 75% of the dataset, each with an different “hold-out” set to test against). The average accuracy across all four trained models was 99.84%. This implies that the ResNet-18 model is learning and predicting rather than overfitting to its training set.
I also trained models using four different datasets/approaches: the original 20,000 image dataset; a pre-processed version of the original dataset (run through Jay’s filters); aeye’s curated dataset (embossed braille only); and transfer learning on a model that was previously trained on ImageNet.
Finally, I chose the two best models from the above testing and trained incrementally using the pre-processed/filtered dataset as a validation step to tailor it to our software stack. This greatly improved performance on a small batch of test crops provided to me by Jay.
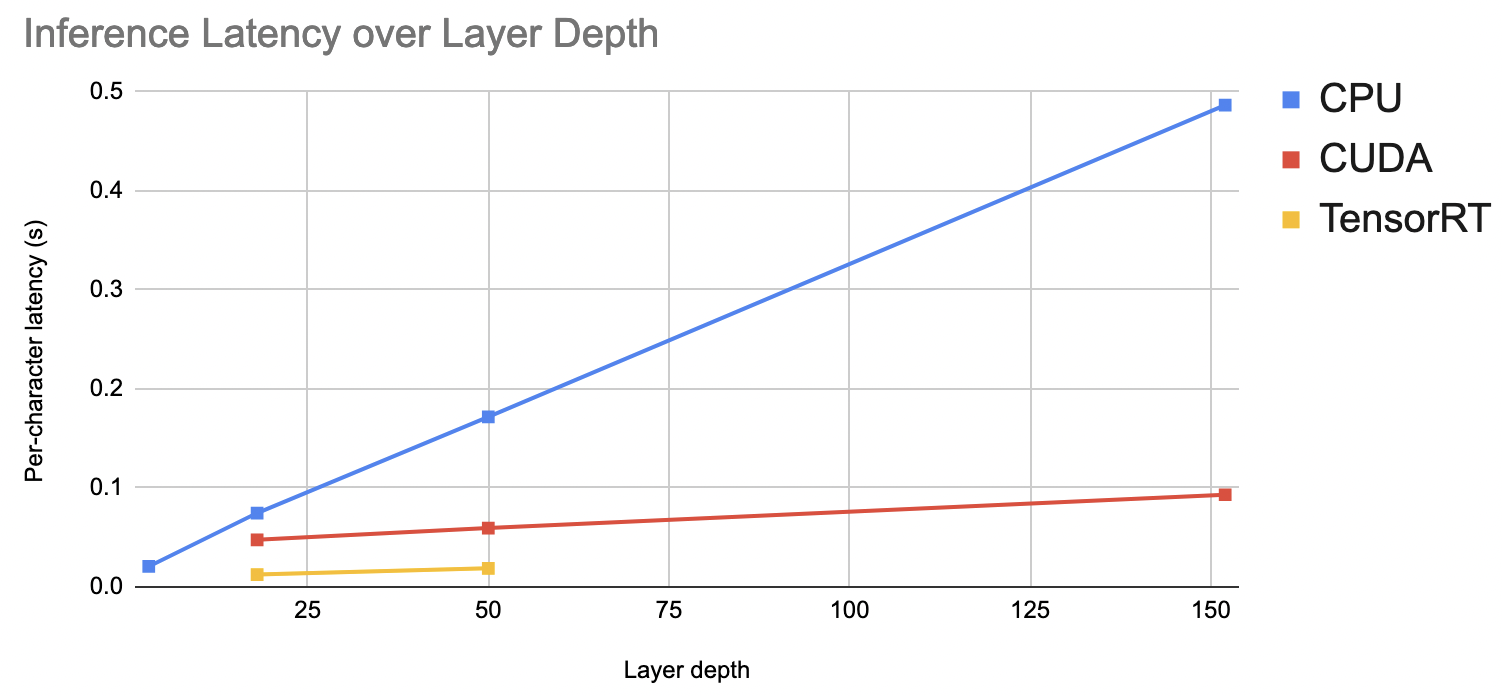
Finally, I was able to measure average per-character latency for a subset of models by running inferences on the Jetson Nano over a subset of the dataset, then averaging the total runtime. It became clear that layer depth was linearly related to per-character latency, even when increasing the number of images per inference. This is accelerated by using parallel platforms such as CUDA or TensorRT. As a result, our ResNet-18 on TensorRT managed to outperform the 3 convolutional block pretrained model on CPU (ResNet-152 failed due to lack of memory on the Jetson Nano).
Hardware
I was able to solder together the button trigger and program GPIO polling fairly quickly using a NVIDIA-provided embedded Jetson library. Integrating this function with capturing an image from a connected camera was also helped by third party code provided by JetsonHacks. I am also working on setting up the Nano such that we do not need a monitor to start our software stack. So far, I have been able to setup X11 forwarding and things seem to be working.
In addition, I have started setting up the AGX Xavier to gauge how much of a performance boost its hardware provides, and whether that’s worth the tradeoff in power efficiency and weight (since we’ve pivoted to a stationary device, this may not be as much of a concern). Importantly, we’ve measured that a given page has approximately 200-300 characters. At the current latency, this would amount to 2.5s, which exceeds our latency requirement (however, our latency requirement did assume each capture would contain 10 words per frame, which amounts to far fewer than 200 characters). I am, however, running into issues getting TensorRT working on the Xavier. It’s times like these I regret not thoroughly documenting every troubleshooting moment I run into.
Cropping Experiments
Having selected more-or-less a final model pending measurement, I was able to spend some time this week tinkering with other ideas for how we would “live interpret”/more reliably identify and crop braille. I began labeling a dataset for training YOLOv5 for braille character object detection, but given the number of characters per image, manual labeling did not produce enough data to reliably train a model.
While searching for solutions, I came across Ilya G. Ovodov‘s paper for using a modified RetinaNet for braille detection, as well as its accompanying open-source dataset/codebase. The program is able to detect and classify braille from an image fairly well. From this, I was able to adapt a function for cropping braille out of an image, then ran the cropped images through my classification model. The result was comparable to the RetinaNet being used alone.



AngelinaReader provides a rough training harness for creating a new model. It also references two datasets of 200+ training/validation images, combined. After making some modifications to address bugs introduced by package updates since the last commit and to change the training harness to classify all braille characters under a generalized class, I was able to set up an AWS EC2 machine to train a new RetinaNet for detecting and cropping Braille. Current attempts to train my own RetinaNet are somewhat successful, though the model seems to have trouble generalizing all braille characters into a single object class.


I trained two networks, one on the AngelinaDataset alone, and one on a combination of the AngelinaDataset and DSBI (double-sided braille image) dataset. After 500 epochs, I performed the opposite of Ovodov’s suggested method in the paper and moved the character classification contribution to 0 (we are generalizing braille characters) and trained the model for a further 3000 epochs. However, both implementations failed when given scaled images, unlike AngelinaReader’s pretrained model.


As a result, with so little time and having run out of AWS credits, we are considering adapting the pre-trained model for our pipeline (pending testing on the Jetson) and leaving room for fine tuning/training our own models in the future.
Kevin’s Status Report for 11/19/22
This week, I was able to convert our trained neural network from Apache’s MXNET framework, which AWS uses to train image classification networks, to ONNX (Open Neural Network Exchange), an open-source ecosystem for interoperability between NN frameworks. Doing so allowed me to untether our software stack from MXNET, which was unreliable on the Jetson Nano. As a result, I was able to use the onnx-runtime package to run our model using three different providers: CPU only, CUDA, and TensorRT.
Surprisingly, when testing CPU against CUDA/TensorRT, CPU peformed the best in inference latency. While I am not sure yet why this may be the case, there are some reports online of a similar issue where the first inference after a pause on TensorRT is much slower than following inferences. Furthermore, TensorRT and CUDA have more latency overhead on startup, since the framework needs to set up kernels and send instructions to all the parallel units. This is not something that will affect our final product, however, because it is a one time cost for our persistent system.
In addition to converting our model to MXNET, I also changed the model’s input layer to accept 10 images at a time rather than 1. Doing so allows more work to be done in a single inference, lowering the latency overhead of my phase. Because the number of images per inference will be a fixed value for a given model, I will make sure to tune this parameter to lower the number of “empty” inferences completed as we define the our testing data set (how many characters per scan etc.). It is also possible that as the input layer becomes larger, CPU inference becomes less efficient while GPU inference is able to parallelize, leading to better performance using TensorRT/CUDA.
Finally, I was able to modify output of my classification model to include confidence (inference probabilities) and the next N best predictions. This should help optimize post-processing to our problem space by narrowing the scope of the spell check search.
I did not have the opportunity this week to retrain / continue training the existing model using images passed through Jay’s pre-processing pipeline. However, as the details of the pipeline are still developing, this may have been a blessing in disguise. Next week, I will be focused on measuring the current models performance (accuracy, latency) using different pre-processing techniques and inference providers, as well as measuring cross-validation accuracy of our final training dataset. This information will be visualized and analyzed in our final report and help inform our final design. In addition, I will also be integrating the trigger button for our final prototype.
Kevin’s Status Report for 11/12/2022
This week was Interim Demo week. I spent some time this week bootstrapping an integrated demo of all our individual parts, which was fairly simple because of the detached and parallel nature of our pipeline. As part of this task, I built a wrapper class for making predictions on a directory of files using the classifier I trained on AWS. Since last week, the mxnet docs have luckily been restored, making this task substantially less confusing.
While the resulting software worked well on my local Ubuntu system, it was quite difficult getting all the dependencies working on the Jetson Nano, given that it is a legacy device with limited support from NVIDIA. Specifically, the Jetson’s hardware platform and older OS meant that package managers like pip rarely offered pre-built wheels for a quick and easy install. As a result, libraries such as mxnet had to be built locally, which took around a day given the Jetson Nano’s computing power. The alternative option would have been to cross-compile the package on a more powerful computer. However, I had trouble getting the dockerfiles provided to accomplish this working. There are still quite a few problems with the hardware that I will have to troubleshoot in the coming weeks.
This week I also used Jay’s pre-processing pipeline to create a second dataset for training my model. Next week, I hope to continue iterating on the existing model on AWS to make it more accurate and reliable for our use case. Furthermore, while per-character inference on the Jetson is fairly fast at around ~0.1s, when processing words by character, this can add up to significant latency. As a result, I will be working on converting the mxnet model to tensorrt, which uses the Nano’s tensor cores to parallelize batch inference. This should also remove some of the difficulty of working with mxnet.
Kevin’s Status Report for 11/05/2022
This week, I spent an unexpected bulk of my time setting up the Jetson Nano with our camera. Unfortunately, the latest driver for the e-CAM50/CUNX-NANO camera we had chosen to use was corrupting the Nano’s on-board firmware memory. As a result, even re-flashing the MicroSD card did not fix the issue and the Nano was stuck on the NVIDIA splash screen when booting up. To fix this, I had to install Ubuntu on a personal computer and use NVIDIA’s SDK manager to reflash the Nano board entirely. We will be pivoting to a USB webcam temporarily while we search for an alternative camera solution (if the USB webcam is not sufficient). Looking at the documentation, the Jetson natively supports USB webcams and Sony’s IMX219 sensor (which is also available in our inventory, but seems to provide worse clarity). I am also in contact with e-con systems (the manufacturers of e-CAM50), and am awaiting a response for troubleshooting the driver software. For future reference, the driver release I used was R07, on a Jetson Nano 2GB developer kit with a 64GB MicroSD card running Jetpack 6.4 (L4T32.6.1).
On the image classifier side, I was able to set up a Jupyter notebook on SageMaker for training a MXNet DNN model to classify braille. However, using default suggested settings and the given dataset led to unsatisfactory results when training for more than 50 epochs from scratch (~4% validation accuracy). We will have to tune some parameters before trying again, but we will have to be careful not to over-test given our $100 AWS credit limit. Transfer learning from Sagemaker’s pre-trained model (trained on ImageNet), conversely, allowed the model to converge to ~94+% validation accuracy within 10 epochs. However, testing with a separate test dataset has not been completed on this model yet. Once I receive the pre-processing pipeline from Jay, I would also like to run the dataset through our pre-processing and use that to train/test the models – perhaps even using it for transfer learning on the existing braille model.
One minor annoyance with using an MXNet DNN model is that it seems that Amazon is the only company actively supporting the framework. As a result, documentation is lacking for how to deploy and run inferences without going through SageMaker/AWS. For example, the online documentation for MXnet is currently a broken link. This is important because we will need to run many inferences to measure the accuracy and reliability of our final model / iterative models, and batch transforms are relatively expensive on AWS.
Next week is Interim Demo week, for which we hope to have each stage of our pipeline functioning. This weekend, we expect to complete integration and migration to a single Jetson board, then do some preliminary testing on the entire system. Meanwhile, I will be continuing to tune the SageMaker workflow to automate (a) testing model accuracy / confusion matrix generation (b) intake for new datasets. Once the workflow is low maintenance enough, I would like to help out with coding other parts of our system. In response to feedback we received from the ethics discussions, I am considering prototyping a feature that tracks the user’s finger as they move it over the braille as a “cursor” to control reading speed and location. This should help reduce overreliance and undereducation due to our device.
Team Status Report for 11/05/2022
What are the most significant risks that could jeopardize the success of the project?
One issue we ran into this week was with connecting the eCAM50 MIPI CSI camera that we had expected to use initially. Due to unforeseen issues in the camera driver, the Jetson Nano is left in a boot loop after running the provided install script. We have reached out to the manufacturers for troubleshooting but have yet to hear back.
Looking at the feed from our two alternative cameras, the quality of video feed and the resulting captured image may not exhibit optimal resolution. Furthermore, the IMX219 camera with its ribbon design and wide angle FOV is highly vulnerable to shakes and distortions that can disrupt the fixed dimensional requirements for the original captured image, so further means to minimize dislocation should be investigated.
How are these risks being managed?
There are alternative cameras that we can use and have already tested connecting to the Nano. One is a USB camera (Logitech C920) and the other is an IMX219, which is natively supported by the Nano platform and does not require additional driver installations. Overall, our product isn’t at risk, but there are trade offs that we must consider when deciding on a final camera to use. The C920 seems to provide a clearer raw image since there is some processing being done on-board, but it will likely have higher latency as a result.
We will be locating the camera in a fixed place(rod,…) along with creating dimensional guidelines to place the braille document to be interpreted. Since the primary users of our product could have visual impairments, we will place physical tangible components that will provide guidelines for placing the braille document.
What contingency plans are ready?
We have several contingency plans in place at the moment. Right now we are working with a temporary USB camera alternative to guarantee the camera feed and connection to the Nano. In addition, we also have another compatible camera that is smaller and has lower latency with a small quality trade off. Finally, our larger contingency plan is to work with the Jetson AGX Xavier connected to the wifi extension provided by the Nano, and mount the camera for the most optimal processing speeds.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
Since our last report, no significant changes have been made to the system design of our product. We are still in the process of testing out the camera integrated with the Jetson Nano, and depending on how this goes we will make a final decision as we start to finalize the software. In terms of individual subsystems, we are considering different variations of filtering that work best with segmentation and the opencv processing, as well as having the classification subsystem be responsible for concatenation to simplify translation of the braille language.
Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
Since we did not change any major sections of the system design, we do not have any costs associated currently. Right now, we are prepping for the interim demo and if everything goes well we will be in solid form to finish the product according to schedule. Individually, the work will not vary too much and if needed can be shifted around when people are more accessible to help. At this stage in the product, most of the software for our individual subsystems has been created and we can start to work more in conjunction with each other for the final demo.
Provide an updated schedule if changes have occurred.
Since we had been working based off of the deadlines on the Canvas assignments, our Gantt chart was structured under the impression that Interim Demos would take place during the week of Nov. 14. We have since changed our timeline to match the syllabus.
Kevin’s Status Report for 10/29/22
Following our return from fall break, we spent some time this week to debrief and re-calibrate our expected deliverables for the Interim Demo. One important change that was made for more convenient development was pivoting to the Jetson Nano as our prototyping platform. Outside of working on the Ethics assignment, I spent some time this week partitioning the dataset into separate datasets for cross-validation (train, validate, test), using roughly a 60/20/20 division, respectively. Because of the size of the dataset, I was confident that I could use a larger partition for validating and testing. Once done, I formatted the dataset in accordance to the SageMaker tutorial for TensorFlow, then uploaded it to an AWS S3 Bucket.
This weekend, I was granted AWS credits which I will use to begin training our ML model on SageMaker. Since SageMaker offers multiple frameworks for Image Classification (MXNet, TensorFlow), I will make sure to test both to see which is more accurate. Furthermore, I am planning to use K-Fold cross validation to test the robustness of our dataset. I am currently still training on the open-source dataset without any meaningful modifications outside of relabeling (see last weekly update), however we hope to add some more images that have been run through the pre-processing pipeline soon.
Since we are beginning to pivot toward preparing hardware for our interim demo, I also took some time this week to work independently on bringing up the Jetson Nano and eCAM-50. However, I ran into some issues flashing the SD card, due to a version mismatch between the on-board memory and the image provided by NVIDIA online. Since I do not have an Ubuntu system readily available, I will need to use Jetpack SDK manager on the lab computers to resolve this.
As mentioned above, I’ve run into some unexpected blockers both on hardware bring-up and AWS, but I’m hoping to catch up early this week, hopefully ending tomorrow with a working Jetson Nano and integrated camera, and a working SageMaker model. The rest of the next week will be spent measuring the results of tuning various parameters on SageMaker and choosing the best model to use for our application, in addition to working with Jay to integrate our phases.
Kevin’s Status Report for 10/22/2022
Note: This weekly status report covers any work performed during the week of 10/15 as well as Fall Break.
This past week (10/15), the team spent the majority of their time developing the design report, for which I spent some time performing an experiment to measure the performance of the pre-trained model we are measuring. To do this, I first had to download an offline copy of the labeled dataset made available by aeye-alliance. Then, I relabeled the dataset with braille unicode characters rather than English translations. I also manually scanned through each labeled image to make sure they were labeled correctly. Of the more than 20,000 images downloaded from online containers, I only found 16 mislabeled images and 2 that I deemed too unclear to use.

Attribution of training data will be difficult to maintain if required. We can refer to the labeled data csv files from aeye-allliance, which includes a list of the sources of all images, but we will not be able to specifically pinpoint the source of any single image.
Once I had the correct data in each folder, I wrote a python script which loaded the pre-trained model and crawls through the training dataset, making a prediction for each image. The result would be noted down in a csv containing the correct value, the prediction, and the measured inference time. Using pandas and seaborn, I was able to visualize the resulting data as a confusion matrix. I found that the resulting confusion matrix did not quite reach the requirements that we put forth for ourselves. There are also a number of imperfections with this experiment, which have been described in the design report.
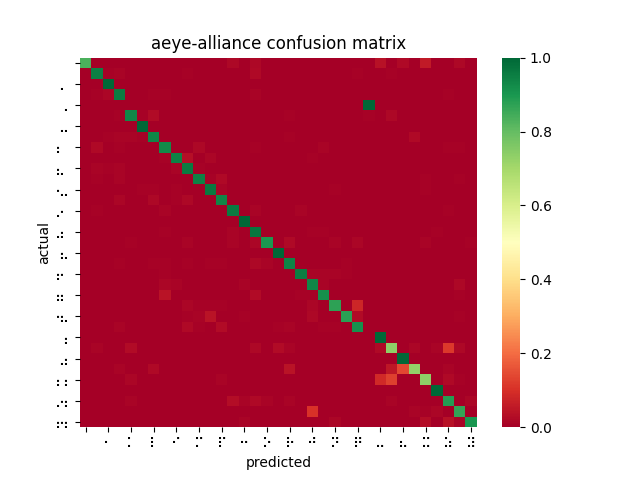
The rest of my time was spent writing my share of the content of the design report. The following week being Fall Break, I did not do as much work as described in our Gantt chart. I looked into how to use Amazon Sagemaker to train a new ML model and setup an AWS account. I am still in alignment with my scheduled tasks, having built a large dataset and measured existing solutions in order to complete the design report. Next week, I hope to use this knowledge to quickly setup a Sagemaker workflow to train and iterate on a model customized for our pre-processing pipeline.