This week, I worked on a multitude of things. I started with looking into the speech recognition algorithm and thinking of possible ways to increase the accuracy. I created more training data which helped increase the accuracy by about 5%. I also tested the workflow and integration of the algorithm significantly, making sure that the signal processing and machine learning components work well together.
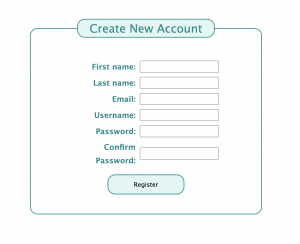
Second, I worked on the web application this week. I spent a little bit of time cleaning up the backend logic for users to create a new account and login into iRecruit. This included fixing a minor bug so now the user’s username appears on the dashboard and the navigation bar. I also created a user database to store the information of any user that makes an account with iRecruit. This database will be utilized in the profile page to keep track of each individual user’s completed behavioral and technical interview practices. Additionally, I worked on the tips page and researched and added in tips for technical interviewing for the user’s convenience.
Majority of my time was spent continuing to work on the technical interview page. I finished creating the questions database so that each of our eight categories have a couple questions. I displayed the user’s chosen category (the output of our speech recognition algorithm) on the webpage as well as a random question associated with that category. I also created an input text box for the user to submit their answer in. Next steps include writing backend code in the Django framework to retrieve the user’s answer and check its accuracy. I also plan on displaying a possible correct answer on the screen, so the user can compare theirs to this sample answer if desired. I will be storing the user’s questions and answers in the database, so that a summary of their practices can be displayed on the profile page.
I believe I am on progress as the skeleton of the technical interview page has been completed. I will spend the rest of the semester trying to improve the speech recognition algorithm and formatting the technical interview page to incorporate the best UI practices; however, I feel that the core of the project has been completed.