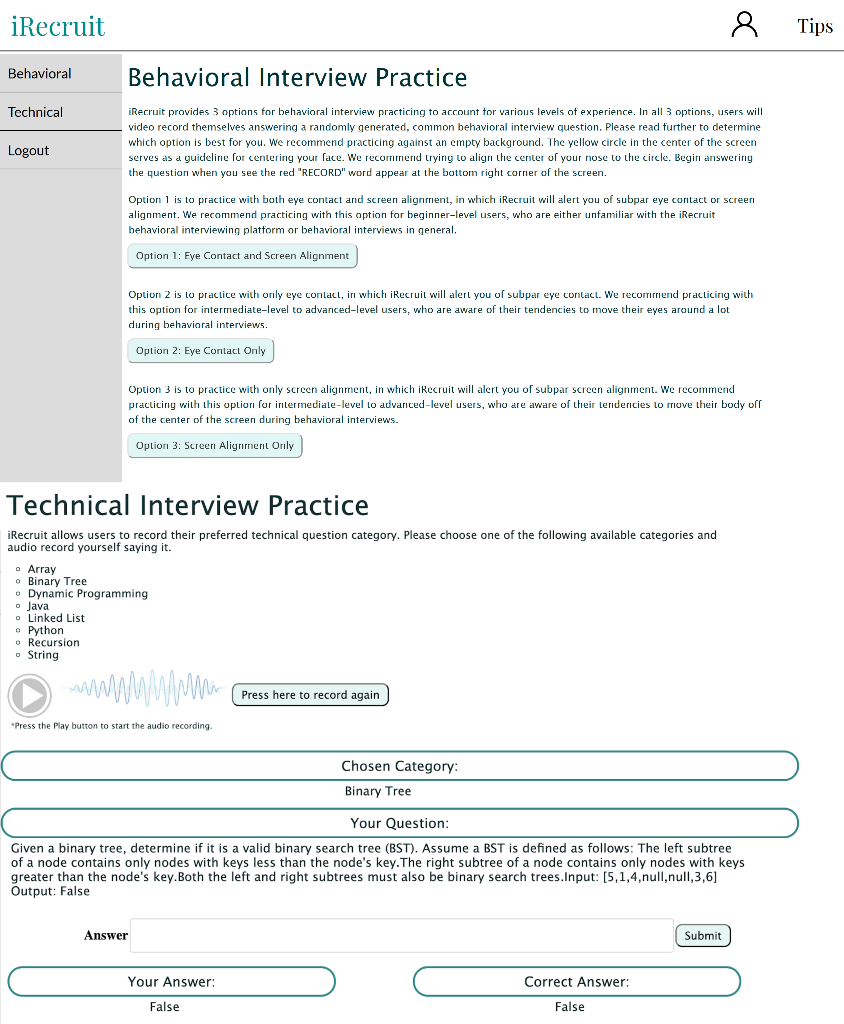
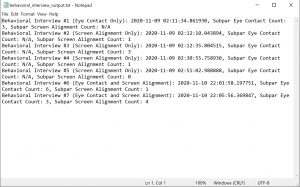
This week, we continued working on the various components of iRecruit. Jessica worked on integrating the eye contact and screen alignment parts together for option 1 of the behavioral interview options, and figured out how to store summary information for each video recording. She was able to combine the eye contact and screen alignment parts to alert the user of both subpar eye contact and screen alignment. There are setup phases for the eye detection and facial landmark detection parts, where the frame of reference coordinates for the center of the eyes, nose, and mouth are calculated in the first 5 seconds. If a user’s eyes, nose, or mouth are off-center, they are alerted with the appropriate category (eye contact or screen alignment). She also implemented the video summaries for the profile part of the behavioral interviews. There is a common text file that keeps track of all the video summaries. For each video recording, the interview number, timestamp, number of times the user had subpar eye contact, and number of times the user had subpar screen alignment are appended to a new line in the file. Next week, she plans on integrating this text file with Django, so that the video summaries show up on the profile page. She also plans on continuing to test the eye contact only option, and beginning to test the screen alignment only option and the integrated option.
Mohini worked on a couple different things this week. Since she finished most of the implementation last week, she spent her time this week testing and refining. She refined the backend database model that kept track of each user and their corresponding questions and answers. Then, she tested the speech recognition algorithm using both automated and manual testing. Automated testing consisted of having a fixed testing data set of approximately 50 samples whereas manual testing consisted of retrieving the testing input through the signal processing algorithm. She will continue this testing next week to determine the true accuracy of the algorithm. Lastly, Mohini started working on the final report and incorporating some of the design changes that we made throughout the project. Next week, she will start recording her parts for the final video demo.
Shilika worked on the web application and added finishing touches such as the Completed Technical Interview page and minor css changes. She also worked on testing the speech recognition algorithm. She ran the automated testing and collected data. Additionally, she ran the in-built gnb methods in python to compare the results of that against the neural network. Next week, she will continue testing the performance of the speech recognition model, and work on the final video and report.