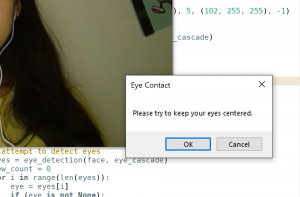
This week, we continued working on implementing our respective portions of the project, making progress in the three main parts. Jessica worked on implementing a center of frame reference, facial landmark detection, and testing the eye detection portion. She thought it would be helpful to have a centered guideline for users to position themselves accordingly during the initial setup phase, so that they have a reference for the center of the video screen. She continued working on the facial landmark detection, and was able to get the coordinates of the center of the nose and mouth. The eye detection portion was also tested more, and the results seem to align with the accuracy goal. Next week, she will work on completing the initial setup phase for the facial landmark detection, and would like to complete the off-center screen alignment portion for the nose as well. She will also continue testing both the eye detection and screen alignment parts.
Mohini finalized the signal processing algorithm and started making the training data set for the neural network algorithm. This week concluded the signal processing portion of our project, so I will be focusing on the machine learning portion as well as integrating the different components of our project together for the rest of the semester. Next week, I will be working on testing the neural network after finishing generating the rest of the training data set.
Shilika began reviewing the neural network concepts, as this is the next technical aspect of the technical interview portion that she will help tackle. She also continued to work on the web application to improve the css and features that appear in the front-end to make the app more user friendly. Next week, she will continue working on the web application and the neural network.