Kaitlyn’s Status Report for 4/20/24
Work Done
Since my last status report I have made a lot of progress on the project and am pretty much wrapping up all the tasks I have to do.
I realized that the way I was calculating the actions were incorrect and that Q-learning usually requires discretized actions, so I had to modify the ML model. We initially planned on our model outputting an action for the light instead of the length of time the lights should be green, however I found that the implementation would be easier if we set the light interval rather than setting the state.
I also considered that this method is safer since latency isn’t as much of an issue. Since we are sending how long the traffic light should be green in a specific direction, if we have delays, the light will just keep switching states with the previous interval lengths without problem. It is also much easier to pre-set minimum and maximum light durations, allowing us to prevent cars permanently waiting or not having enough time to pass easily. In contrast, if we send the states to the traffic light, a state being sent too late or being tampered with will affect the safety of cars at the intersection at a higher probability and it is harder to implement the minimum and maximum interval since we have to keep track of time ourselves.
I realize this is a bit hard to explain, but previously the values were represented as a continuous interval, but I modified it as a discrete array so that there will be an action corresponding to the maximum q-value output by the neural network that we can choose for the next state. The image below shows a more visual explanation.
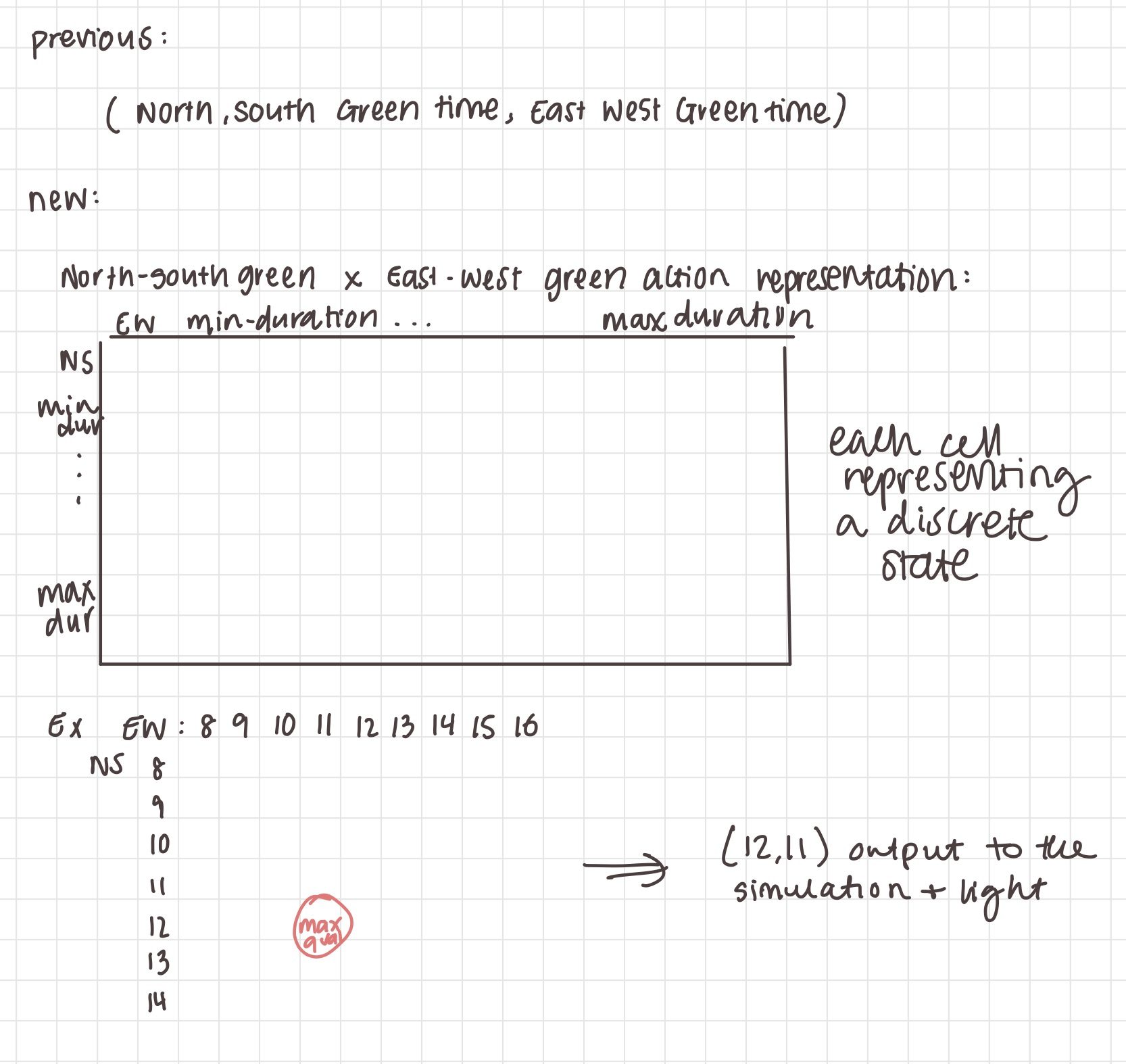
Additionally, I fixed the simulation because I was having trouble with the calibrators not spawning in cars whenever the simulation lasted for longer than an hour, which was not ideal since we needed the simulation to run for much longer in order to train the Q-learning model. I had a long back and forth with developers of SUMO through the mailing list, but ultimately I had to debug the problem myself and I found out that the flows just can’t last too long or the cars will clump and spawn in a very short period of time at the end of the interval.
For example, whenever I set the flow to 3600 seconds, it would spawn most of the cars from 3000 to 3600 seconds instead of evenly distributing the cars across the 3600 seconds. I had to modify the code to use TraCI to automatically spawn flows so that the simulation kept running infinitely and I had to make the flows shorter intervals in time to prevent the clumping.
I responded to the mailing list about resolving the issue myself, and someone explained that the calibrators have the clumped spawning for the following reason:

It was frustrating that this was not very clearly explained in the documentation and I only found this out through an old GitHub issue that a developer responded to.
I also was trying to randomize the routes more to mimic more accurate car behavior so that our testing is more accurate, but the calibrators don’t seem to allow spawning of cars that follow different routes. At the moment, I am just performing the testing on the simulation where cars spawned follow a set route since I haven’t been able to resolve the issue yet. I do think it is possible for me to add some variation in car patterns by rotating which routes the cars follow during a single flow, however this still won’t be completely accurate since this method will lead to a period where all cars follow route 1 for example then all cars follow route 2, instead of a mix of route 1 and route 2 during a period.
Additionally, last weekend Ankita and I went to record simultaneous footage of all four sides the intersection so she can test the image detection more.
I also modified the simulation to add sidewalks for pedestrians which we can also input into the Q-learning model to optimize more, however I am unable to systematically generate pedestrians since calibrators only work for cars, as stated in the email response above, however I am able to spawn in single pedestrians according to the image detection model.
I also ran a full training of the Q-learning model and added the testing infrastructure so that I could compare the results of the simulation with and without the optimization model.
The following is the results gathered by the testing code.
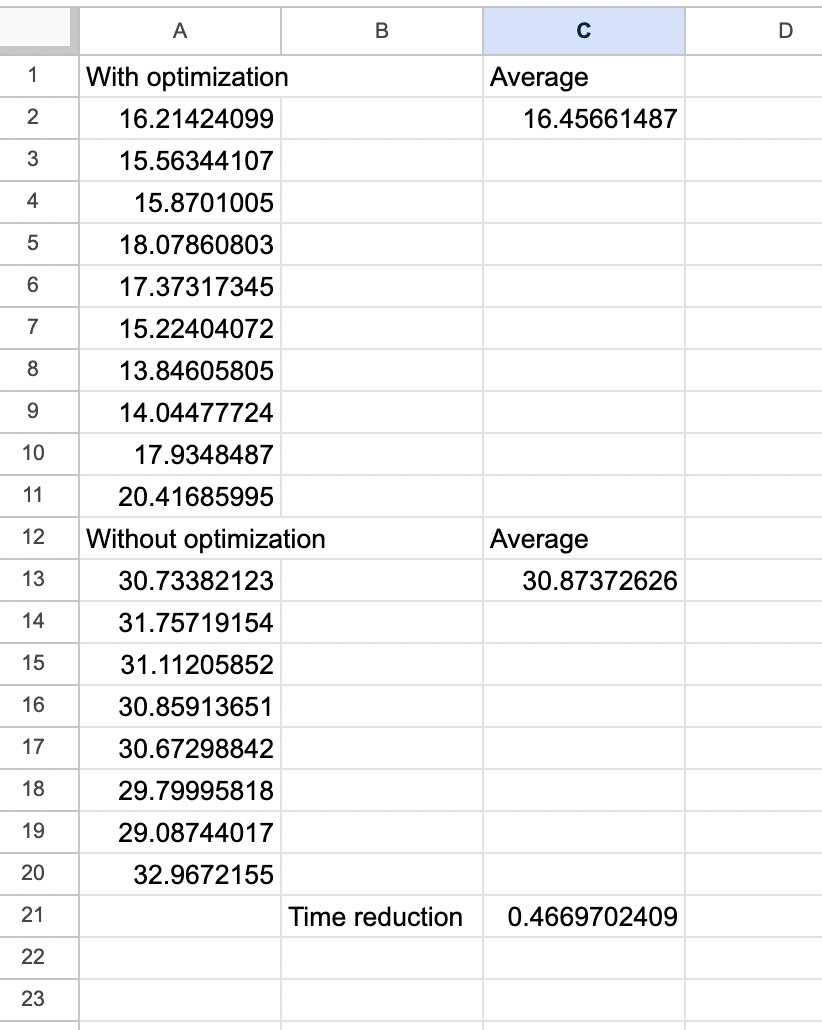
I am pretty satisfied with the approximately 47% improvement in wait times, however these times are likely higher due to the lack of variability in the simulation. I plan on modifying the simulation to add more randomness and retraining the Q-learning model, as stated before, however I think we will definitely meet the time reduction of 10% we initially planned.
Schedule
I am pretty much on schedule, however I moved the hyper parameter tuning for later, since I saw that the model was already very performant without a lot of tuning, however I will be doing this after the presentation next week.
The following is what my remaining tasks look like.
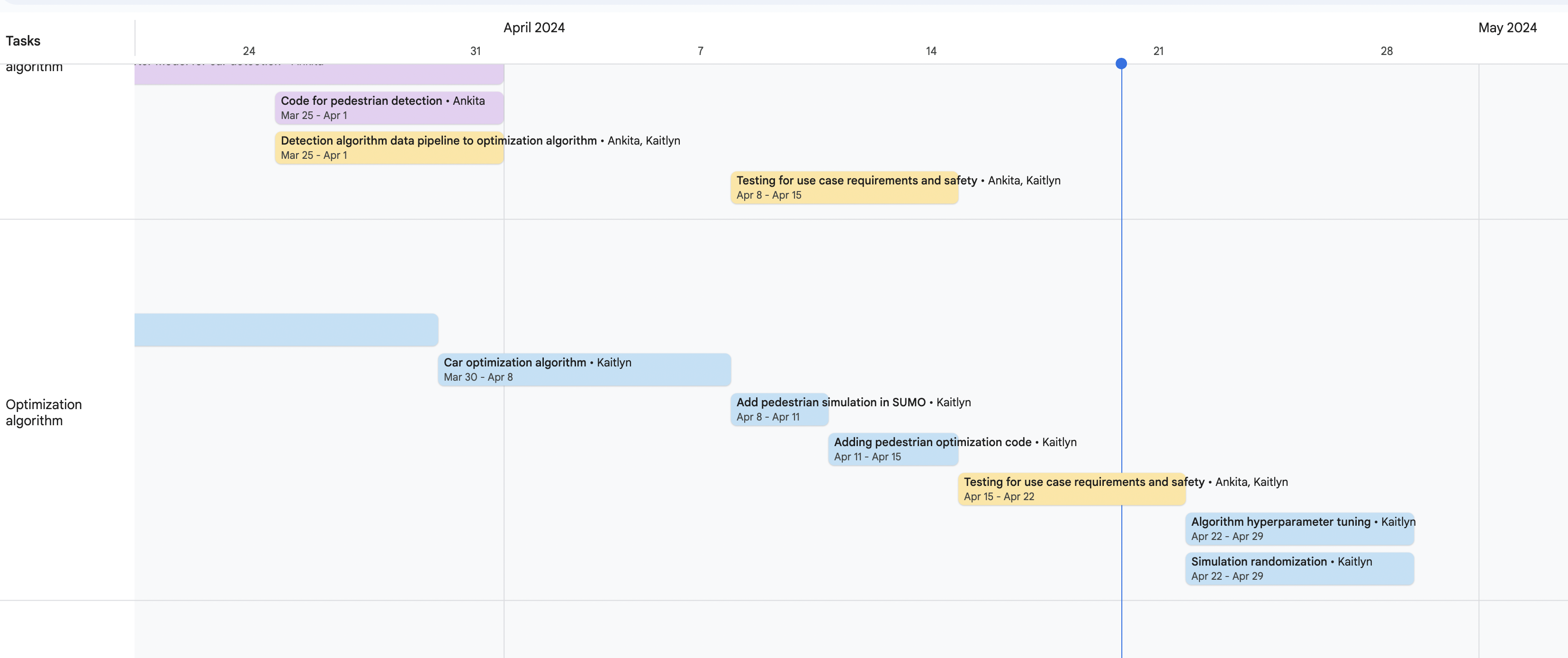
Tasks
- Hyper parameter optimization – I want to try various episode numbers as well as episode lengths and other parameters to see if the model is more performant.
- Alternative Q-learning implementation – if I have time I might try to implement the previous Q-learning we planned where we instead output a state the light should change to and sample every 5 seconds or so for the new state the light should change to, however this will be a stretch goal as it is not necessary for our project, but would be a great comparison to our current implementation to see if there are variations in car wait time reduction.
- Slides for the presentation – I will be working on the slides for the presentation today and tomorrow. I am working on the solution and testing slides for my parts of the project as well as the project management slides.
- Presentation practice – I am presenting this time, so I will also be prepping for the presentation and running through the slides once they are done.
New Tools
The main new tool I had to learn to use was SUMO, the simulation software we are using. In order to get started, I followed the tutorials they listed on their website and read through a lot of the documentation on the specific features I was planning to use. Even though the tutorials were very straightforward, I found that the tools I wanted to use were more obscure and had a lot less documentation, so I had to look up a lot of random forum posts to figure out how to use them. I also started emailing the SUMO users mailing list for help towards the end of my time working on the simulation since I had very complex issues that no one had asked about previously.
Additionally, I had to learn how to use PyTorch and how Deep Q-learning works. Thankfully, there was a lot of documentation on this and there were many tutorials on the topic, especially the example of Q-learning for balancing a stick, and I was able to modify and expand on the example code for our purposes. This was the specific tutorial I referenced a lot: LINK.
I also had to learn how to use the TomTom API, which I was able to easily use with the help of their own documentation which clearly showed me how to set up the API and call specific endpoints. Since I have used a lot of APIs in the past, I was able to test it in Postman and then integrate it into our code easily.