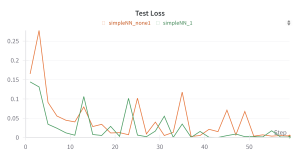
This week, I did some brief work in finalizing some metrics for the ML model. This included some rigorous testing into the real-time performance and the test-time performance. I was also able to develop confusion matrices on some data to get a better picture for how the model is working. I am also pretty confident in my final ML model design with the addition of some more words into the second model to allow for more refined predictions. I also briefly tested the model with the PCB as made by Ria. However, the performance of the model is inconsistent, which I believe is due to the fact that the PCB is currently being secured by tape. I will hope to continue testing once the PCB is more reliably secured, but we always have the original protoboard as a backup plan which I will propose if needed. I also spent a decent chunk of time working on the poster. This tied nicely with the metrics that I found. I also wrote out the start of the final report which will hopefully have us finishing before demo day.
My progress is on schedule with the slight caveat that I am waiting for the PCB design to be finalized. I foresee that minimal adjustments will need to be made once that is attached but we will have to wait and see.
Next week, I hope to quickly finalize our demo day product. Finish the report and video and present on demo day.