Accomplishment (Updated on 04/29)
- Prepared for the final presentation
- Worked with Shakthi to deploy headless device settings by changing the startup application of the Ubuntu, so that the Jetson Nano automatically runs the main.py file, which has the OR model with speech module and button integration.
- During the process, when trying out different permission change commands, the speech module broke down. As a result, we had to reboot the Jetson and reinstall all the necessary programs to run the speech module and OR module.
- I reinstalled python 3.8.0 to the Jetson and opencv 4.8.0 with the GStreamer option enabled to allow video streaming. The same memory swap technique used previously was used to download a huge opencv build folder, which was about 8 GB.
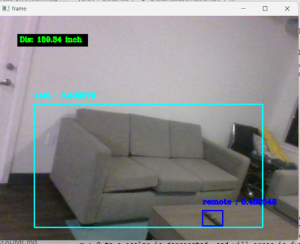
- (Update) Reduced the data latency of the OR model to an average of 1.88s by using a multithreading method to concurrently run the OR model and the video capture by the gstreamer from OpenCV. The OR model uses a frame to detect the closest object while the camera concurrently updates the frame. Although it faces a race condition by multiple threads accessing the global variable at the same time, the data fetched from the global variable would be from the previous instance, which is at most 1 frame behind real time. Not only it works with our use case requirement, but also this would not be noticeable to the user and hence does not affect their navigation experience. For this reason, we decided not to use any mutex or other lock methods for the global variable, which can potentially create a bottleneck and increase the latency of data transfer.
Progress
- Fixed the speech module by rebooting the Jetson to a clean default setting.
- Due to the audio error in the Jetson, the rebooting and reinstalling programs hindered our work for headless deployment. We are behind schedule in this step and will do unit testing once we get to finish this deployment.
Projected Deliverables
- By next week, we will finish deploying the Jetson headless, so that we can test out the OR model by walking around an indoor environment.
- By next week, we will conduct a user testing on the overall device functionality