This past week I focused on working on the A* version of pathfinding, touching up the code to include additional information that will eventually be necessary during implementation, and running some general benchmarks for A* vs normal Dijkstras.
Seeing as I had never used A* before, it took a bit of research to understand what went into making a heuristic function; in case anyone reading this is unfamiliar, A* is an informed version of Dijkstras, which allows the algorithm to guess what the best path is going to be by using a heuristic function written by the person implementing the function. This function will tweak the weights of the priority queue used in Dijkstra’s such the next path chosen should be favored if it is already expected to be along the current best path. Another way of phrasing it is that Dijkstras algorithm is a special case of A*, where the heuristic function is uniform across all data points.
After having learned a bit about it and figuring out how I might write an algorithm for our specific use-case, I decided a good heuristic function would be to favor what would be the best path, assuming there were no obstructions. In the case that there are no obstructions in the graph, or there are obstructions, but they are not in the way of the best path from the current node, this should significantly speed up algorithm time.
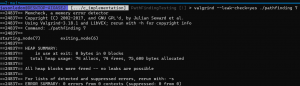
The testing of A* vs Dijkstra’s doesn’t rely on any real-world parameters, so I was able to simulate it by running various tests where there are reported obstructions at some nodes. These are the results:

Keep in mind that these results will vary depending on the graph that is being used for testing, what nodes are being reported as obstructed, and the weighting that is being used in the Heuristic function; that being said, I think this provides a useful insight that using A* might provide some benefit to our project, but the improvement is not guaranteed, especially if there are multiple reported obstructions. It is also important to note that A* should scale better as the graph grows because the cost of calculating the Heuristic function should become more insignificant as the time it takes to find an exit node grows.
I am slightly behind schedule because I have not yet started wireless communication integration. We recently made the decision to use WiFi as the primary source of wireless communication for our nodes due to cost constraints; because WiFi is integrated directly into the ESP32’s that we purchased, I should be able to progress on that throughout this week. However, we still wanted to use ZigBee boards to display a proof of concept. I am unable to start on ZigBee network communication because the XBee boards that we ordered have not yet arrived. To answer the question of how I plan to get back on track, once we get back from spring break, I will have just completed my midterm exams for my other classes, and I expect to have extra time to dedicate to capstone. This additional free time should be the perfect time to catch up on some of the project tasks that I have fallen behind on.
This upcoming week, I want to focus on getting the nodes to communicate with each other over a network. I want to focus on using WiFi first, but if the additional boards have come in over break, I want to attempt to get communication over ZigBee as well. This is going to be the main task that I want to address because it is absolutely necessary to have a working demo for the interim demo that is fast approaching on April 3rd. If there is additional time after focusing on network communication, I will begin working on sending data between the node and incorporating that into the pathfinding: the goal here is to have pathfinding update to reflect the updates sent from other nodes about what is a valid path.